Chapter 9: Fine-Tuning in Practice — Help Large Models and Embedding Models Better Understand Your Domain
In the previous tutorial, we improved the retrieval accuracy of the RAG system by optimizing the retrieval strategy, recall strategy, and query rewriting strategy based on large models. However, the final response results still need to be fused and processed by large models. The strength of the model directly affects the final results. This is like a good dish requires not only high-quality ingredients (an optimized retrieval module provides high-matching text), but also a good chef (a capable LLM that fuses information to generate answers). In this tutorial, we will further improve the accuracy of the RAG system, go into the generation module of the RAG system, discuss the role of large models in it, and introduce how to significantly improve the generation capabilities of large models through fine-tuning of LazyLLM, and even use small models to surpass general large models (i.e., train a good chef), thereby improving the reply quality of the RAG system.
The role of large models in the RAG system
Review of RAG process
In the previous tutorial, we have been able to quickly build the RAG system. Let us quickly review the RAG operation process:
- The retrieval module will query the knowledge base based on the user's Query to recall Top-K related documents through vector similarity;
- The generation module splices the search results with the user Query, and inputs LLM to generate the final response;
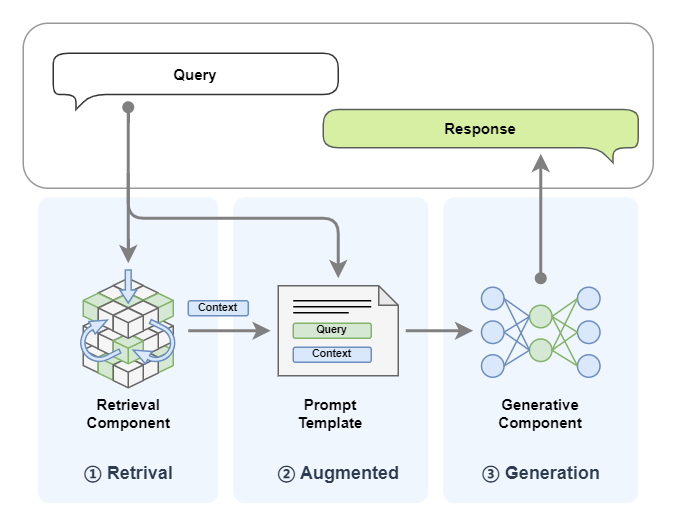
From this we can see that the LLM large model mainly plays the role of content generation in the RAG system. Specifically we can summarize it as follows:
- Semantic Understanding: Analyze the true intention of the query;
- Knowledge Fusion: Coordinate the fusion of original knowledge (knowledge inherent in the LLM large model) and new knowledge (retrieval content);
- Logical reasoning: Reason a reasonable result based on the intent and context of the query;
So there are two main factors that affect the accuracy of the RAG system:
Effectiveness of recall + Ability to generate model content
In the previous tutorials, we have introduced in detail how to improve the recall effect (quick review: Chapter 7: Search upgrade practice: build a “smarter” document understanding system by yourself!, Chapter 8: More than just cosine! The matching strategy determines the quality of your recall). In this issue, we will focus on enhancing the model capabilities of the generation module to improve the quality of the content generated by the model.
Impact of model capabilities
In a typical RAG architecture, the baseline capability of the large language model (LLM) directly affects the reliability of the final output of the system, and its performance bottlenecks are mainly reflected in the following three dimensions:
1. Domain knowledge adaptability defects
General-purpose large models (such as DeepSeek-R1, GPT-4, Claude-3) show strong capabilities in open domain knowledge understanding, but their performance drops significantly when facing vertical fields:
-
Difficulties in interpreting professional terms: For example, IC can refer to “Intensive Care” in the medical field, and “Integrated Circuit” in the electronics field.
-
Lack of long tail knowledge:
- In the medical field, general large models may be mainly exposed to data of common diseases during training, and have less exposure to data of rare diseases. As a result, when the model encounters cases of rare diseases, it may not be able to accurately identify or diagnose, leading to misdiagnosis or missed diagnosis;
- In natural language processing, general models are usually trained based on Mandarin or mainstream languages, and there is less training data for local dialects. As a result, the model may have misunderstandings or incomprehensibility when processing local dialects, affecting the communication effect;
- In cultural knowledge question and answer or recommendation systems, the general model has a good grasp of mainstream cultural knowledge, but lacks understanding of niche cultural knowledge. As a result, when users ask questions about niche culture, the model may not be able to give accurate or relevant answers.
-
Limitations in domain reasoning ability:
- In the legal field, general large models are used to assist in case analysis. When dealing with complex legal cases, it may not be possible to understand the deep legal logic and the relationship between provisions. As a result, the analysis suggestions provided by the model may not be accurate or comprehensive enough, affecting legal decision-making;
- In the field of education, general large models are used to assist in solving mathematical problems. When dealing with advanced mathematical problems, the model may not be able to perform in-depth reasoning and calculations. The model cannot solve complex mathematical problems, or the answers given may be wrong;
- In the field of scientific research, general large models are used to assist in the design of experiments. The model may lack an in-depth understanding of a specific scientific field and cannot take into account all experimental variables and potential effects. As a result, the designed experiments may be flawed and fail to achieve the expected research goals.
2. Weak structured output control
When the system requires fixed format output (such as JSON data tables, standardized reports), the model is susceptible to two key issues:
-
Format Drift Phenomenon:
- In financial data analysis, the model needs to output a standardized JSON format data table. However, because the model does not grasp the format details accurately enough, the nesting level of some fields in the output JSON data is incorrect. For example, data that should belong to subfields is placed directly under the parent field, causing data parsing to fail;
- In the field of e-commerce, the model is responsible for generating JSON data of product information. However, due to format drift, unnecessary spaces, line breaks, or missing quotation marks appear in the data output by the model, causing errors in the front-end system's parsing and affecting product display;
-
Hallucination Interference:
- In the medical report generation scenario, the model needs to output a report containing the patient's basic information, diagnosis results, treatment plan and other fields in a fixed format. However, the model exerts itself when generating the report, fabricating non-key field contents outside the format, such as adding non-existent examination items or treatment recommendations, resulting in distortion of the report content, which may interfere with the doctor's diagnosis;
- In the generation of legal documents, the model needs to output documents according to a standard template. However, due to the interference of hallucinations, the model added fictitious facts or legal provisions irrelevant to the case in the document, resulting in inaccurate document content and affecting the legal validity;
3. Performance is limited by the deployment environment
The knowledge base required by RAG is often private to users, and users prefer to deploy it locally, which means deploying local large models at the same time, and local deployment of large models requires computing power support. It is difficult for ordinary users to have strong computing power. At this time, with computing power resources, they often can only choose some smaller LLM models, such as 7B size models, and the basic capabilities of these smaller LLMs cannot be compared with LLMs of more than 600B, and the capabilities of the models are also weak. Therefore, privacy protection requirements force enterprises to adopt localized deployment solutions, but this creates computing power constraints:
- Model scale limit: A single A100 server (80G video memory) supports the deployment of a maximum 70B parameter model, and the cloud can call 600B DeepSeek-R1 at the same cost;
- Generational differences in capabilities: For example, the accuracy of the LLaMA-7B model is significantly lower than the accuracy of LLaMA-65B.
Fine-tuning to improve large model capabilities
The problems mentioned above can be solved to a certain extent through targeted fine-tuning strategies, which can significantly improve the domain adaptability and output standardization of the generation module in the RAG system.
🧐 So what is fine-tuning?
Fine-tuning is a lightweight technology based on pre-trained large models and secondary training with data in specific fields to adapt the model to professional scenarios.
Fine-tune core methods
- Supervisory fine-tuning (SFT): Inject domain QA data (such as legal cases/medical reports)
- Domain adaptation: LoRA low-rank adaptation technology, freezing original parameters + training adaptation layer
Core Advantages
- Efficiency: After fine-tuning the 7B model, the performance on specific tasks is comparable to the untuned 70B model
- Low cost: Parameter efficient fine-tuning (PEFT) only needs to update 0.1%~20% of the parameters
- Controllability: Strengthen structured output and content output constraints (such as JSON format calibration)
Typical application scenarios
(1)Enhanced domain knowledge adaptability
a. Vertical domain knowledge injection: Construct a fine-tuned data set based on domain-specific data (such as medical cases, legal documents, scientific research papers), and use instruction fine-tuning (Instruction Tuning) to enable the model to learn the knowledge expression pattern in the domain. For example, in a medical scenario, use
b. Long-tail knowledge compensation: For rare terms or low-frequency scenes (such as dialect vocabulary, niche cultural concepts), construct question and answer pairs containing such knowledge, and enhance the model's ability to capture long-tail features through fine-tuning. For example, in dialect processing tasks, dialect-standard language control samples are injected into the training data to strengthen the model's generalization ability across language variants.
(2)Structural output control enhancement
a. Explicit learning of format tags: Embed structured tags (such as {{KEY_START}}diagnosis results{{KEY_END}}) in the fine-tuning data to force the model to learn the separated expression of format and content.
b. Anti-interference training: Inject 20%-30% noise samples into the training set (such as randomly deleting quotation marks, disrupting the JSON hierarchy), requiring the model to maintain content accuracy while repairing the format. In this way, the model's robustness to format drift is improved.
c. Lightweight deployment adaptation environment
Small model capability enhancement: Through progressive knowledge transfer, the capabilities learned by the large model in domain tasks are distilled into the small model. For example, use a large model to generate pseudo-labels for domain-related data (you can also directly use annotated data in relevant professional fields), and then fine-tune the small model based on this data, so that the 7B model can approach the performance of the 65B model on specific tasks.
Here we give an example of a specific scenario:
In the medical field, text information in medical reports (for example, "The patient exhibits symptoms of hypertension and the systolic blood pressure is 150mmHg") needs to be converted into JSON format, which contains key information such as symptoms and blood pressure readings.
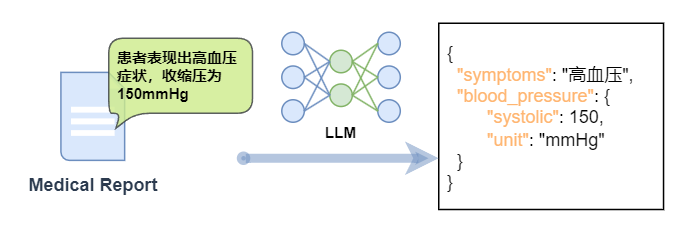
With fine-tuning, the following benefits can be achieved for this type of task:
1. Accurate information extraction
- Fine-tuning can help the model more accurately extract structured information from natural language text, such as symptom type, numerical value, unit, etc.
2. Contextual understanding
- Information in natural language often depends on context, and fine-tuning allows the model to better understand these contexts and thus convert information more accurately.
3. Specific format requirements
- JSON structured text often has strict formatting requirements, and fine-tuning can help the model generate output that meets these requirements.
4. Handling of domain-specific terms
- Fine-tuning can help the model better understand and process professional terms.
Converting natural language to JSON structured text is a typical scenario where fine-tuning can significantly improve the performance and output quality of LLM. Through fine-tuning, the model can learn how to identify and extract key information from natural language and present this information in a predefined structured format.
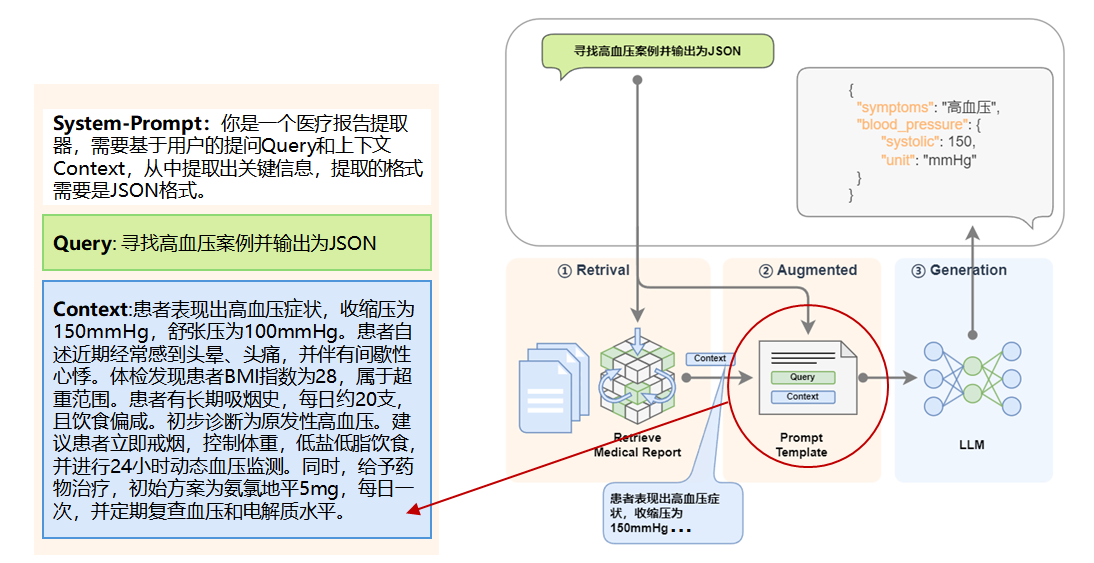
Let's put the fine-tuned model into RAG, like this:
Principles and methods of LoRA fine-tuning
We mentioned above that fine-tuning can solve various problems, so what specific fine-tuning methods are used?
In response to the inherent challenges of traditional full-parameter fine-tuning in terms of resource consumption and catastrophic forgetting (over-adjustment of pre-training weights will destroy the knowledge expression of the model in general fields), LorRA (Low-Rank Adaptation) fine-tuning provides an effective optimization approach and has become a common method in the field of model fine-tuning.
Overview of LoRA fine-tuning
Let's take LoRA fine-tuning as an example to explain the application of fine-tuning in LazyLLM.
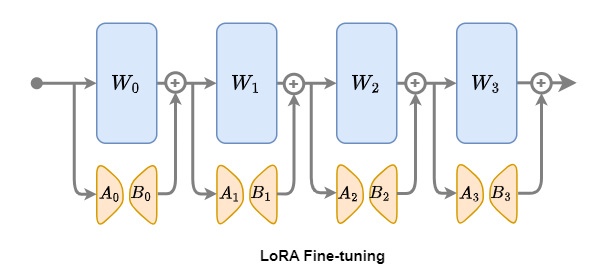
LoRA fine-tuning is an advanced fine-tuning technology designed for Transformer models. Its core idea is to simulate and implement the fine-tuning process by introducing low-rank matrices \(A\) and \(B\) on the basis of keeping the pre-trained model parameters \(W \in \mathbb{R}^{d \times k}\) fixed.
The uniqueness of this method is that it does not directly adjust the parameters \(W \in \mathbb{R}^{d \times k}\) in the original model (such as \(W_0\), \(W_1\), \(W_2\), \(W_3\)), but introduces additional trainable parameters for each layer - the orange matrix \(B \in \mathbb{R}^{d \times r}\) and \(A \in \mathbb{R}^{r \times k}\), only fine-tuning these low-rank matrices.
LoRA fine-tuning steps
- Load the pre-trained model: First, select a pre-trained Transformer model as the basis.
- Introduce low-rank matrices: In each layer of the model, add trainable low-rank matrices \(B \in \mathbb{R}^{d \times r}\) and \(A \in \mathbb{R}^{r \times k}\).
- Fine-tune low-rank matrices: Input task-specific data into the model, and use the backpropagation algorithm to update parameters for low-rank matrices \(A\) and \(B\).
- Evaluation and optimization: Evaluate the performance of the fine-tuned model on the validation set, and further optimize the model based on actual needs.
LoRA mathematical analysis
Going a step further, let's look at the mathematical analysis of LoRA. The LoRA (Low-Rank Adaptation) method is based on the low-rank matrix approximation theory and achieves efficient fine-tuning of parameters by freezing the parameters of the pre-trained model and injecting trainable low-rank matrices. At the mathematical level, for the pre-training weight matrix \(W ∈ R^{d×k}\), LoRA decomposes its update amount into the product of two low-rank matrices:
Among them, \(B \in \mathbb{R}^{d \times r}\), \(A \in \mathbb{R}^{r \times k}\), and \(r \ll \min(d, k)\). Such decomposition results in updates with lower rank, thus reducing the number of parameters that need to be trained.
During forward propagation, the output of the model becomes:
in:
- \(W\) is the original weight matrix of the pre-trained model
- \(x\) is the input
- \(B\) and \(A\) are low-rank matrices (rank \(r\))
- \(\alpha\) is a scaling factor used to flexibly control the adjustment strength of the low-rank matrix to the original weights.
- \(r\) is rank
1. The influence of rank \(r\)
-
Parameter efficiency and model capacity
-
\(r\) determines the approximation ability of the low-rank matrix \(BA\).
- A larger \(r\) allows the matrix to capture more complex updates and improves the model's adaptability to tasks, but will increase the training parameters (the number of parameters is \(r \times (\text{dim}_A + \text{dim}_B)\)), which may lead to overfitting.
- A smaller \(r\) reduces the number of parameters and improves training speed, but may limit the model's expression ability.
-
-
Overfitting and generalization
- Small \(r\): more suitable for small data sets, reducing the risk of overfitting, but may underfit complex tasks.
- Large \(r\): Suitable for large data sets or complex tasks, but more data is needed to avoid overfitting.
-
Experience Points: Typically \(r = 8\) or \(16\) performs well on most tasks.
2. Effect of scaling factor \(\alpha\)
-
Update amplitude control
-
\(\alpha\) adjusts the weight of the low-rank update term \(BAx\).
- Larger \(\alpha\) enhances the impact of incremental updates, which may speed up convergence, but may also destroy pre-training knowledge;
- Smaller \(\alpha\) makes updates gentler, retaining more of the original model's capabilities, but requires longer training time.
-
-
Synergy with Rank
- The \(\frac{\alpha}{r}\) design in the formula balances the effects of different \(r\) values. For example, when \(r\) increases, dividing by \(r\) can prevent the update range from being too large and maintain training stability.
-
Experience value: Usually \(\alpha\) is set to 2 times \(r\) (such as \(\alpha = 16\))
3. The influence of \(\frac{\alpha}{r}\)
-
Update intensity and convergence speed
-
\(\frac{\alpha}{r}\) directly controls the overall contribution of the low-rank term:
- High ratio (such as large \(\alpha\) or small \(r\)): strong update intensity, suitable for quickly adapting to new tasks, but may cause gradient instability.
- Low ratio (such as small \(\alpha\) or large \(r\)): the update is gentle, suitable for retaining pre-training knowledge, and requires longer time for fine-tuning.
-
-
Relationship with learning rate
- \(\frac{\alpha}{r}\) acts like an adaptive learning rate for low-rank terms.
4. Impact of freezing pre-training weights
-
Mitigation of catastrophic amnesia
- The original weight \(W\) is frozen, and only \(B\) and \(A\) are trained to avoid destroying pre-training knowledge and significantly reduce the risk of overfitting.
-
Computational efficiency
- Reduce training parameters to the size of low-rank matrices (such as from hundreds of millions of parameters to millions), saving video memory and computing resources.
Parameter tuning suggestions
-
Task complexity and data volume
- Simple tasks/small data: Choose small \(r\) (e.g. \(r=4\)) and medium \(\alpha\).
- Complex tasks/big data: Try larger \(r\) (e.g. \(r=32\)) and increase \(\alpha\).
-
Resource limitations
- When there is insufficient video memory, priority is given to reducing \(r\) instead of reducing model size.
Parameter summary
- \(r\): balances expression ability and parameter efficiency, determining the flexibility of model fine-tuning.
- \(\alpha\): adjust the intensity of new knowledge injection, and jointly control training stability with \(r\).
- \(\frac{\alpha}{r}\): directly affects the convergence speed and final effect, and needs to be adjusted according to task requirements.
Fine-tune large models based on LazyLLM
So how should we implement fine-tuning? Here we implement a LoRA fine-tuning based on LazyLLM.
We choose a small model and use the training data in the CMRC2018 data set to fine-tune this small model so that it can have better Chinese reading comprehension information extraction capabilities. The models used in RAG before will answer questions based on the knowledge base information we retrieved. The answers are relatively divergent and the degree of freedom is relatively high. Here we hope that the models in RAG have the following characteristics:
- Extract necessary information to answer based on user questions and recalled text paragraphs, without extending the information (corresponding to the above mentioned: weak structured output control and poor adaptability of domain knowledge);
- The model should be small, about 7B, for easy deployment, and a model that is not too large should not be used (corresponding to the contradiction between lightweight deployment requirements and reduced model accuracy mentioned above).
Our overall fine-tuning steps are as follows:
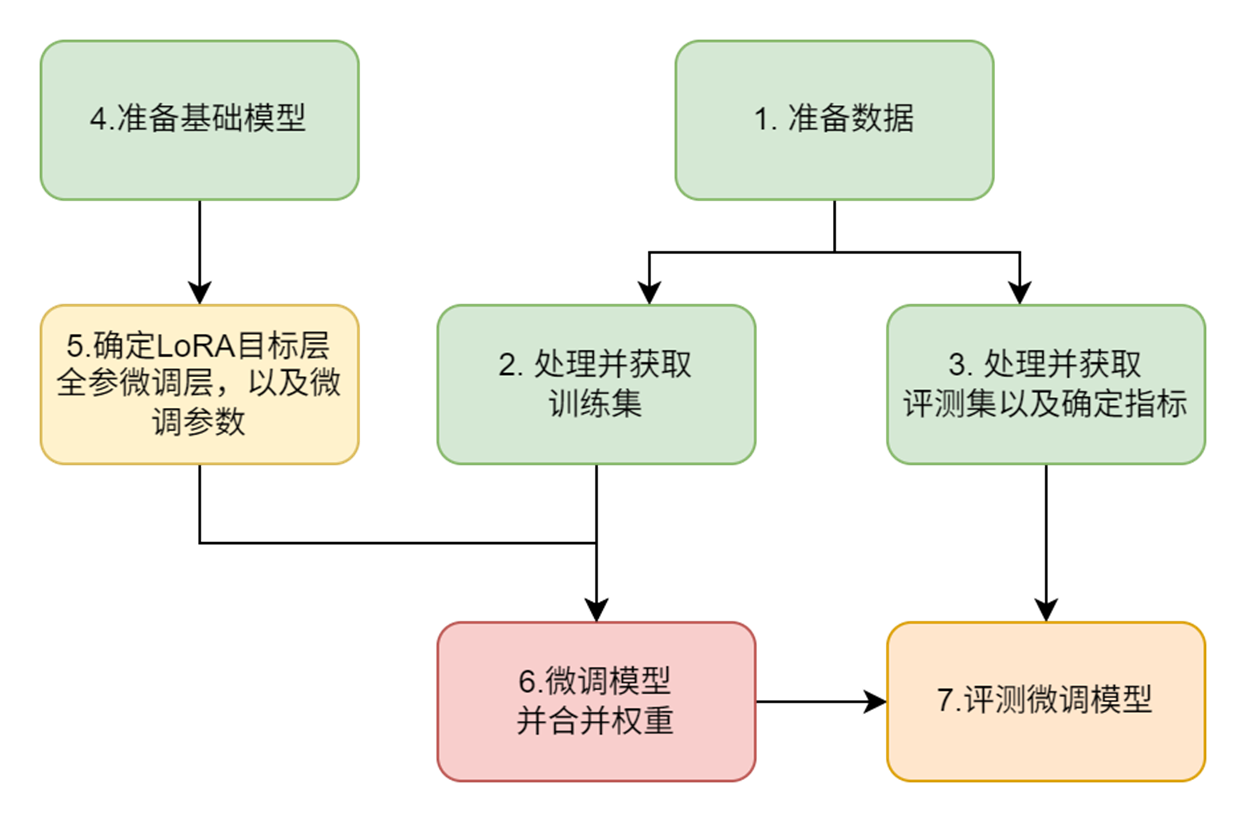
- Question: The answers to the original RAG medium and large models are divergent and need to be streamlined + accurately follow the original text output;
- Goal: Strengthen Chinese reading comprehension information extraction capabilities on the 7B small model *Model selection: InternLM2-Chat-7B.
- Data preparation: Use CMRC2018 training data, focusing on Chinese question and answer and information extraction.
- Fine-tuning method:
- LoRA strategy: freeze the original weights and only train low-rank matrices (BA) to reduce video memory usage.
- Control output: Strengthen the ability to follow the original content and streamline the output.
Data preparation
Dataset Introduction
We choose the CMRC2018 dataset, which consists of nearly 15,000 real-world questions annotated by human experts on Wikipedia paragraphs. In addition, the corresponding task of this data set is: "Span-Extraction Reading Comprehension". Based on a given document and a question, the model needs to extract the answer to the question from the document, where the answer is a continuous fragment of the article.
Dataset size
The CMRC2018 data set mainly consists of three parts: test, validation and train. Here we use the train part as our training set, the test part as our evaluation set, and we do not use the validation part.
| Dataset | Number of essays | Number of questions | Purpose |
|---|---|---|---|
| test | 256 | 1002 | evaluation set |
| train | 2403 | 10142 | training set |
| validation | 848 | 3219 | not used |
Note:
- The knowledge base in the previous tutorial was built based on the passages in the test data set in CMRC2018;
- Here we use the train data set in CMRC2018 for training;
- During the evaluation process, in order to avoid interference from the retrieval module in the RAG system, we use the control variable method, assuming that 100% recall is no problem, that is: we directly use the passage fragments and questions in the test data set in CMRC2018 to splice them together as the input of the large model LLM. The variables are two 7B models before and after fine-tuning to compare and see whether the fine-tuned model has improved its ability to extract Chinese reading comprehension information;
Data structure
The structures of test and train in the data set are consistent. We extract one of the data and see as follows:
[
{
"id": "TRIAL_154_QUERY_0",
"context": "Eugene Kangaroo (\"Macropus Eugenii\") is a small member of the Kangaroo family, and is usually the subject of research on kangaroos and marsupials. Eugene's kangaroos are distributed in the southern islands and west coast of Australia. Because they breed in large numbers on Kangaroo Island every season, destroying the living environment on Echidna Island, they are considered a pest. The Eugene's kangaroo was first discovered in Western Australia by survivors of a shipwreck in 1628. It is the earliest recorded discovery of kangaroos by Europeans, and may be the earliest discovery. There are three subspecies of Australian mammals: the Eugene kangaroo is very small, weighing only about 8 kilograms, and is suitable for breeding. There is a substance in the milk of the Eugene kangaroo, which may be a miracle drug and an improvement on penicillin. AGG01 is a protein that has been proven to be 100 times more effective than penicillin and can kill 99% of bacteria and fungi, such as Salmonella, Proteus vulgaris and Staphylococcus aureus.
"question": "Where are Eugene's kangaroos distributed?",
"answers": {
"text": [
"Eugene's kangaroo is distributed in the southern islands and west coast of Australia"
],
"answer_start": [
52
]
}
},
...
In the above data:
context: is a text segment;question: is a question directed at the text segment;answers: Answers to corresponding questions are given, including:text: The specific content of the answer, derived from the text segment;answer_start: The starting position of the answer in the text paragraph;
Training set processing
- We extract the article field
contextand the question fieldquestionfrom the original train data set, and splice them into theinstructionfield for fine-tuning. The splicing template is: "Please use the original text of the following paragraph to answer the question\n\n### Known paragraph: {context}\n\n### Question: {question}\n". - Use the
answersand itstextfields in the original data as the fine-tunedoutputfield - Since fine-tuning also requires an
inputfield, which we do not need for this task, it is set to empty.
# Template for constructing QA prompts
template = "Please use the original text of the following paragraph to answer the question\n\n### Known paragraph: {context}\n\n### Question: {question}\n"
def build_train_data(data):
"""Format training data using predefined template"""
extracted_data = []
for item in data:
extracted_item = {
"instruction": template.format(context=item["context"], question=item["question"]),
"input": "",
"output": item["answers"]["text"][0]
}
extracted_data.append(extracted_item)
return extracted_data
We take a piece of processed data as follows:
[
{
"instruction": "Please use the original text of the following paragraph to answer the question\n\n### Known text: Huangdu (scientific name:) is a perennial twining vine with spherical or conical tubers in the leaf axils, with spherical or oval bulbils of varying sizes and yellowish-brown outer skin. It has checkered small transverse veins, with 7-9 obvious veins at the base; the base of the petiole is twisted and slightly wider, as long as the leaves or slightly shorter. It blooms in summer and autumn, and is dioecious. The fruiting period is from September to October in Oceania, Korea, and Africa. Asia, India, Japan, Taiwan, Myanmar and China's Jiangsu, Guangdong, Guangxi, Anhui, Jiangxi, Sichuan, Gansu, Yunnan, Hunan, Tibet, Henan, Fujian, Zhejiang, Guizhou, Hubei, Shaanxi and other places, growing at an altitude of 300 meters to 2,000 meters In rice-rich areas, it mostly grows along river valleys, valley ditches or on the edges of mixed woods. It has not yet been artificially introduced and cultivated in the Americas. It is an exotic species to the Americas and has the opportunity to multiply in farmland and climb tall trees to compete for sunlight. Potato. Huangyao (original Materia Medica), Shanzigu (plant names and facts), Lingyuzi Dioscorea (Russian, Latin, and Chinese seed plant names), Lingyuzi (Fora of Guangzhou, Hainan Flora), Huangyaozi (name of medicinal materials in Jiangsu, Anhui, Zhejiang, Yunnan and other provinces), Shanzigu (Chuxiong, Yunnan)\n\n### Question: What is the color of the skin of Huangdu? \n",
"input": "",
"output": "Tawny skin"
},
...
Evaluation set processing
The fields in our evaluation set are basically retained. Only the answers field is processed and the content is extracted:
def build_eval_data(data):
"""Extract necessary fields for evaluation dataset"""
extracted_data = []
for item in data:
extracted_item = {
"context": item["context"],
"question": item["question"],
"answers": item["answers"]["text"][0]
}
extracted_data.append(extracted_item)
return extracted_data
We take a piece of processed data as follows:
[
{
"context": "Furong Cave is located on the banks of the Furong River in Jiangkou Town, Wulong County, Chongqing, 20 kilometers away from Wulong County. Furong Cave was discovered in 1993 and opened to tourists in 1994. It was listed as a national 4A tourist attraction in China in 2002, and in June 2007, it became a component of the Southern China Karst-Wulong Karst. It is the first karst cave in China to be listed as a World Natural Heritage. It is 2,846 meters long and famous for its numerous shafts and complete types of cave deposits. There is a rare group of karst shafts in the world within an area of about 20 square kilometers. There are at least 50 shafts over 100 meters scattered, among which Qikeng Cave has a depth of 920 meters, the longest in Asia. There are more than 70 kinds of sediments in Furong Cave, including almost all the karst cave sedimentary types named by scientists, among which the pool sediment is the essence. There is a "gypsum" at the east end of Furong Cave. "Huazhi Cave", the antler-shaped curled stone branches in the cave are 57 centimeters long, the longest in the world. The gypsum Huazhi Cave is currently permanently sealed. A Jiangkou Power Station Dam has been built on the Furong River adjacent to the entrance of Furong Cave. The impact of the reservoir's impoundment on groundwater circulation and the evolution of the karst landscape is currently difficult to estimate.",
"question": "Where is Furong Cave located?",
"answers": "The banks of Furong River in Jiangkou Town, Wulong County, Chongqing"
},
...
Fine-tuning the model
After the data processing is complete, we can start fine-tuning.
It is worth noting: LazyLLM supports fine-tuning, deployment, and inference in one package!
The fine-tuning related configuration code is mainly as follows:
import lazyllm
from lazyllm import finetune, deploy, launchers
model = lazyllm.TrainableModule(model_path)\
.mode('finetune')\
.trainset(train_data_path)\
.finetune_method((finetune.llamafactory, {
'learning_rate': 1e-4,
'cutoff_len': 5120,
'max_samples': 20000,
'val_size': 0.01,
'per_device_train_batch_size': 2,
'num_train_epochs': 2.0,
'launcher': launchers.sco(ngpus=8)
}))\
.prompt(dict(system='You are a helpful assistant.', drop_builtin_system=True))\
.deploy_method(deploy.Vllm)
model.evalset(eval_data)
model.update()
In the above code, LazyLLM's TrainableModule is used to implement: fine-tuning->deployment->inference:
-
Model configuration:
model_pathspecifies the model we want to fine-tune. Here we use Internlm2-Chat-7B and directly specify its path;
-
Fine-tuned configuration:
.modesets the startup fine-tuning modefinetune;.trainsetsets the data set path for training. What is used here is the training set we processed earlier;.finetune_methodsets which fine-tuning framework to use and its parameters. A tuple is passed in here (only two elements can be set):- The first element specifies the fine-tuning framework used is Llama-Factory:
finetune.llamafactory - The second element is a dictionary containing the parameter configuration of the fine-tuning framework;
- The first element specifies the fine-tuning framework used is Llama-Factory:
-
Inference configuration:
.promptsets the Prompt used during inference. Note that in order to be consistent with the system field in the fine-tuned Prompt,drop_builtin_systemis turned on to replace the original system-prompt with `You are a helpful assistant.`.deploy_methodsets the inference framework for deployment, and the vLLM inference framework is specified here;
-
Evaluation configuration:
- Here we use
.evalsetto configure the evaluation set we processed before;
- Here we use
-
Start task:
.updatetriggers the start of the task: the model is fine-tuned first. After the fine-tuning is completed, the model will be deployed. After deployment, it will automatically use the evaluation set to go through inference to obtain the results;
Some key parameters in fine-tuning are as follows:
| Parameters | Function | Recommended settings | Tuning suggestions |
|---|---|---|---|
| learning_rate | Control parameter update range | 1e-4~5e-5 | Take the smaller value for large models |
| cutoff_len | Maximum context length | 5120 | Adjusted according to GPU memory |
| max_samples | Maximum training sample size | 20000 | Note that too small will result in too little training data, |
| per_device_train_batch_size | Single card batch size | 2 | Decrease when there is insufficient video memory |
| num_train_epochs | Training rounds | 2.0 | Set according to task loss reduction |
In addition, we can also configure some LoRA-related parameters (LazyLLM has set a set of experience parameters by default, so it is not reflected in the above code. Here we show it as follows. You can try various parameters to make elixirs:
| Parameters | Function | Recommended settings | Description |
|---|---|---|---|
| lora_alpha | LoRA scaling factor | 16 | - |
| lora_dropout | LoRA dropout rate | 0.0 | - |
| lora_rank | LoRA rank | 8 | - |
| lora_target | LoRA target module of the total model | all | All linear modules in the model. |
Effect evaluation
After fine-tuning in the previous step and obtaining the inference results of the evaluation set, we need to compare the results with the correct answers of the evaluation set to confirm the effect of our fine-tuning.
Evaluation purpose
- Verify the fine-tuning effect: Compare the model output with the standard answer, and quantify the model optimization results (whether it surpasses the general large model)
- Task Adaptability Test: Common indicators (faithfulness, Answer Relevance) are not applicable to the "Chapter Fragment Extraction" task and require customized evaluation
- Optimization Direction Guidance: Locate model shortcomings through indicator differences (such as complete consistency, semantic accuracy, original text dependence)
Evaluation indicator design
Here, based on the characteristics of our tasks, three-dimensional evaluation indicators are designed:
- Exact Match
- Semantic similarity (Cosine Score)
- Origin Score
Let us now introduce the design details of these three indicators in detail:
1. Exact matching rate
We define exact matching as follows:
where:
- \(N\): total number of test samples;
- \(y_i\): the standard answer of the \(i\)th sample;
- \(\hat{y}_i\): model prediction results;
- \(\mathbb{I}\): indicator function (takes 1 when there is a complete match, otherwise takes 0);
The characteristic of this indicator is that the prediction result and the standard answer need to be completely consistent
Without considering the calculation of the average, the code to implement only one of them is simple, as follows:
Code function:
This code is used to determine whether the model's prediction result (output) for a single sample is completely consistent with the standard answer (true_v) of the sample, and give an exact matching score (exact_score) accordingly.
Code explanation:
output: The prediction result of the model for a certain sample.true_v: The standard answer for this sample.exact_score: Exact match score, value is 1 or 0. If the prediction result is completely consistent with the standard answer, the score is 1; otherwise, the score is 0.
2. Semantic similarity
We define semantic similarity as follows:
where:
- \(N\): total number of test samples;
- \(y_i\): the standard answer of the \(i\)th sample;
- \(\hat{y}_i\): model prediction results;
- \(emb()\): is a vector encoding based on the BGE model (bge-large-zh-v1.5), which can encode natural language into a vector, that is:
$$ emb(text) = BGE_Encoder(text) $$
It is worth noting that this evaluation index truncates the original value of [-1,0). As long as the semantics of negative correlation are 0 points, the score can only be positive correlation.
The corresponding code is implemented as follows. There is no averaging here, just one of the items. It is also assumed that the text has been vectorized by the BGE model:
import numpy as np
def cosine(x, y):
"""Calculate cosine similarity between two vectors"""
product = np.dot(x, y)
norm = np.linalg.norm(x) * np.linalg.norm(y)
raw_cosine = product / norm if norm != 0 else 0.0
return max(0.0, min(raw_cosine, 1.0))
Code function:
This code implements a function that calculates the cosine similarity between two vectors, and is particularly useful for evaluating the semantic similarity between model predictions and standard answers. This is the core calculation part in the above exact matching definition (CS) and is used for similarity calculation of a single sample.
Code explanation:
-
\(x\) and \(y\): represent two vectors respectively. In practical applications, these two vectors are usually the result of vectorizing text by the BGE model, namely \(emb(y_i)\) and \(emb(\hat{y}_i)\).
-
\(\text{np.dot}(x, y)\): Calculate the dot product of two vectors.
-
\(\text{np.linalg.norm}(x)\) and \(\text{np.linalg.norm}(y)\): Calculate the L2 norm (i.e. Euclidean norm) of vectors \(x\) and \(y\) respectively.
-
\(\frac{\text{product}}{\text{norm}}\): Calculate the original cosine similarity value.
-
\(\mathrm{raw\_cosine}\): Stores the original cosine similarity value, but returns 0.0 directly if the denominator is 0 (that is, at least one of the two vectors is a zero vector).
-
\(\max(0.0, \min(\mathrm{raw\_cosine}, 1.0))\): Truncate the original cosine similarity value to ensure that the result is within the range of \([0, 1]\), and the semantics of negative correlation are scored 0 points.
3. Inclusion of the original text
We define the original text inclusion degree as follows:
where:
- \(N\): total number of test samples;
- \(\hat{y}_i\): model prediction results;
- \(w\): represents each word in the prediction result;
- \(Context\): article content;
- \(\mathbb{I}\): indicator function (takes 1 when all words appear in the original text, otherwise takes 0 if there are more words than the original text).
We implement the corresponding code as follows. This does not include averaging, only one of them is involved:
def check_words_from_content(infer, content):
"""Check if all words in inference output exist in original context"""
return 1 if all(w in content for w in infer.split()) else 0
Code function:
This code implements a function check_words_from_content, which is used to check whether all words in the model prediction results appear in the original content. This is the core calculation part in the above definition of original inclusion (OS), which is used to determine the inclusion of a single sample.
Code explanation:
infer: The prediction result of the model for a certain sample, that is, \(\hat{y}\).content: The original content of the sample, that is, \(Context\).infer.split(): Split the prediction results into a list of single words.all(w in content for w in infer.split()): Use Python'sallfunction and a generator expression to check whether each word or vocabulary ininferis present in content. ReturnsTrueif all words or terms exist; otherwise returnsFalse.return 1 if ... else 0: Returns 1 or 0 depending on the check result, as the implementation of the indicator function \(\mathbb{I}\). Returns 1 if all words or terms are present in the original text; otherwise returns 0.
4. Comparative analysis of indicators
We will conduct a comparative analysis of the above three evaluation indicators:
| Indicator dimensions | Value range (single item) | Ideal value (single item) | Numerical characteristics (single item | Advantages | Limitations | Task evaluation dimension description |
|---|---|---|---|---|---|---|
| Exact match rate | {0, 1} | 1.0 | Binary judgment | The result is clear and unambiguous | Zero tolerance for differences in expression | How much reasoning can be 100% faithful to the answer |
| Semantic similarity | [0, 1] | 1.0 | Continuous value | Capture semantic similarity | Depend on encoding model quality | Due to the selection of fragment range or the change of expression, similarity is used to evaluate different expressions of the same content; |
| Original text inclusion degree | {0, 1} | 1.0 | Binary judgment | Ensure answers are faithful to the original text | Ignore reasonable synonymous substitutions | Task requirements, answers must be in the original text, this indicator can reflect whether the answers are all derived from the original text; |
Comprehensive evaluation script
Let us bring all the above evaluation indicators together to achieve the following complete evaluation:
def caculate_score(eval_set, infer_set):
"""Calculate three evaluation metrics: exact match, cosine similarity, and word containment"""
assert len(eval_set) == len(infer_set)
# Initialize embedding model
m = lazyllm.TrainableModule('bge-large-zh-v1.5')
m.start()
accu_exact_score = 0
accu_cosin_score = 0
accu_origi_score = 0
res = []
for index, eval_item in enumerate(eval_set):
output = infer_set[index].strip()
true_v = eval_item['answers']
# Exact match scoring:
exact_score = 1 if output == true_v else 0
accu_exact_score += exact_score
# Cosine similarity scoring:
outputs = json.loads(m([output, true_v]))
cosine_score = cosine(outputs[0], outputs[1])
accu_cosin_score += cosine_score
# Word containment scoring:
origin_score = check_words_from_content(output, eval_item['context'])
accu_origi_score += origin_score
res.append({'context':eval_item['context'],
'true': true_v,
'infer':output,
'exact_score': exact_score,
'cosine_score': cosine_score,
'origin_score': origin_score})
save_res(res, 'eval/infer_true_cp.json')
total_score = len(eval_set)
return (f'Exact Score : {accu_exact_score}/{total_score}, {round(accu_exact_score/total_score,4)*100}%\n'
f'Cosine Score: {accu_cosin_score}/{total_score}, {round(accu_cosin_score/total_score,4)*100}%\n'
f'Origin Score: {accu_origi_score}/{total_score}, {round(accu_origi_score/total_score,4)*100}%\n')
In the above code:
- First pass in the test set and the results of inference, and ensure that the two sets are the same size;
- Then in order to implement text vectorization here, we use LazyLLM's
TrainableModuleto load abge-large-zh-v1.5model, and use.startto deploy it; - Then we go through all the data, calculate each score under the three indicators, and accumulate them;
- Finally we save all results, calculate the final evaluation result and return it as a string.
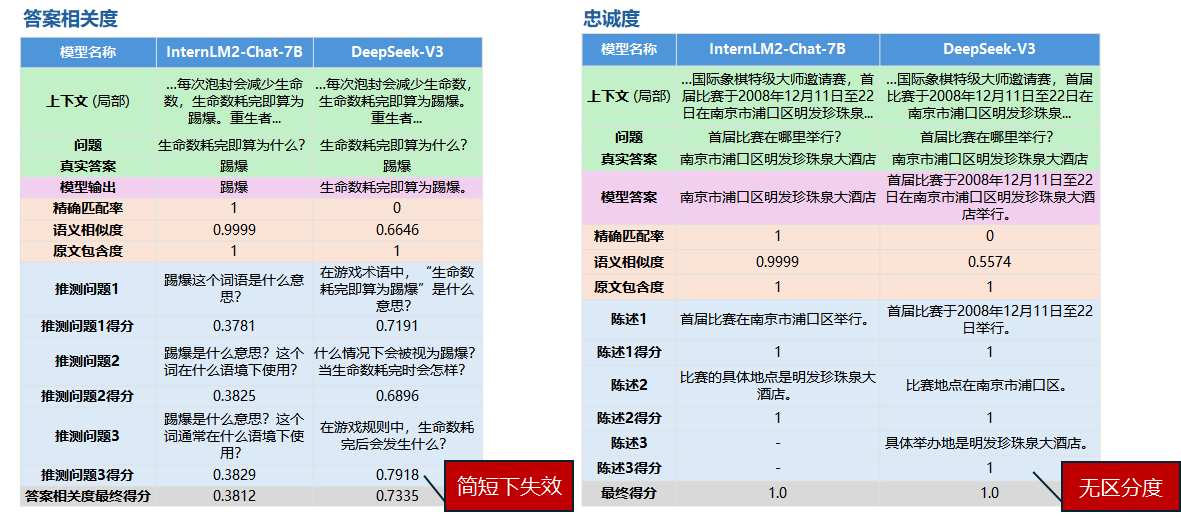
Comparison of evaluation results
Here we compare the model Internlm2-Chat-7B before fine-tuning and the model after fine-tuning. We also compare the online model DeepSeek-V3.
In the results in the table below, the scores are in brackets, the total score is 1002 points, and the percentage is the score as a percentage of the total score.
| Model | Exact match rate | Semantic similarity | Original text inclusion |
|---|---|---|---|
| Internlm2-Chat-7B | 2.10%(21) | 74.51%(746.6) | 5.19%(52) |
| DeepSeek-V3 | 5.29%(53) | 74.85%(750.0) | 15.17%(152) |
| After Internlm2-Chat-7B training | 39.72%(398) | 86.19%(863.6) | 94.91%(951) |
From the above evaluation results, we can see that the model after fine-tuning has significantly better indicators than before fine-tuning, even for large online models.
-
Exact Match Rate Leap
- After fine-tuning, the improvement was 37.62 percentage points (2.10% → 39.72%), nearly 8 times higher than the online model
- Explain that the model learns to follow a specific answer format
-
Semantic relevance optimization
- The similarity increased by 11.68 percentage points (74.51% → 86.19%)
- Compared with online models (large models with more than 600 B): +11.34 percentage points advantage
-
Qualitative change in original text dependence
- The inclusion rate jumped from 5.19% to 94.91%, an increase of 18.3 times
- Show that the model has been mastered:
- ✅ Key information positioning capabilities
- ✅ Original text extraction strategy
- ✅ Knowledge boundary control (avoiding hallucinations)
Based on the experimental data we can conclude:
In the RAG system, under the premise that the recall module is accurate and the recall is correct, the degree of adaptation of the model in the generation module to the task greatly affects the final effect. Fine-tuning is an effective means to improve the model's ability to adapt to downstream tasks, and even the ability improved through fine-tuning can surpass the general large model.
General evaluation comparison
Here we evaluate the model based on the evaluation indicators of the two general generation modules introduced in Retrieve with Higher Accuracy, and compare them with the evaluation indicators we designed.
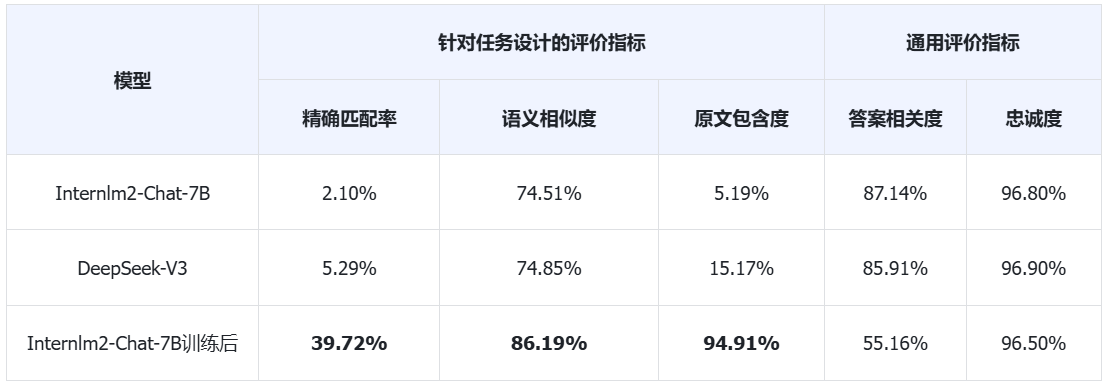
From the data in the table above, we can see that the general evaluation index shows that after fine-tuning, the model's answer correlation has dropped significantly. Under this evaluation index, it means that fine-tuning has failed, but is this really the case? Let’s extract the data from the evaluation process and take a look:
After fine-tuning InternLM2-Chat-7B, answer correlation
{
"context": "Based on the games developed on \"Kart Runner\" and \"Bubble Hall\", it is developed and published by South Korea's Nexon. Mainland China is operated by Shanda Games. This is the first time Nexon has granted Shanda Network its game operating rights again after 6 years. Taiwan is operated by Game Orange. Players use water guns, small guns, hammers or water bombs to soak enemies (players or NPCs), which is a bubble seal, and the bubble is broken into a kick. If the bubble is not there at the time If kicked out within a certain period of time, the number of lives will be reduced, and the number of lives will be exhausted. The reborn person will be invincible for a certain period of time, and the player with the most points will win. The rules vary depending on the mode. In 2V2 and 4V4 random matching, players can climb up the ranking list (in order: rough stone, bronze medal, silver medal, gold medal, platinum, diamond, and master). , you can choose classic, hot-blooded, sniper and other modes to play. If you are in the game, you will not be able to match within 4 minutes (each time you are in the game + 4 minutes). The opening time is from time to time during the summer or winter vacation. The 8-player classic mode is randomly matched and the points are scored. The more points you get during the event, the rewards will be obtained at the end. ",
"exact_score": 1,
"cosine_score": 0.9999,
"origin_score": 1,
"question": "What does it count as if the lives are exhausted?",
"true_answer": "Kick blast",
"answer": "Kick blast",
"infer_questions": [
{
"question": "\nWhat does the word kick mean?",
"score": 0.3781
},
{
"question": "\nWhat does kicking mean? In what context is this word used?",
"score": 0.3825
},
{
"question": "\nWhat does kicking mean? In what context is this word usually used?",
"score": 0.3829
}
],
"final_score": 0.3812
},
DeepSeek-V3, Answer Relevance
{
"context": "Based on the games developed on \"Kart Runner\" and \"Bubble Hall\", it is developed and published by South Korea's Nexon. Mainland China is operated by Shanda Games. This is the first time Nexon has granted Shanda Network its game operating rights again after 6 years. Taiwan is operated by Game Orange. Players use water guns, small guns, hammers or water bombs to soak enemies (players or NPCs), which is a bubble seal, and the bubble is broken into a kick. If the bubble is not there at the time If kicked out within a certain period of time, the number of lives will be reduced, and the number of lives will be exhausted. The reborn person will be invincible for a certain period of time, and the player with the most points will win. The rules vary depending on the mode. In 2V2 and 4V4 random matching, players can climb up the ranking list (in order: rough stone, bronze medal, silver medal, gold medal, platinum, diamond, and master). , you can choose classic, hot-blooded, sniper and other modes to play. If you are in the game, you will not be able to match within 4 minutes (each time you are in the game + 4 minutes). The opening time is from time to time during the summer or winter vacation. The 8-player classic mode is randomly matched and the points are scored. The more points you get during the event, the rewards will be obtained at the end. ",
"exact_score": 0,
"cosine_score": 0.6646,
"origin_score": 1,
"question": "What does it count as if the lives are exhausted?",
"true_answer": "Kick blast",
"answer": "When the number of lives is exhausted, it will be counted as a kick.",
"infer_questions": [
{
"question": "\nIn game terminology, what does \"when the number of lives is exhausted is counted as a kick\" mean?",
"score": 0.7191
},
{
"question": "\nUnder what circumstances will it be considered a kick? What will happen when the life count is exhausted?",
"score": 0.6896
},
{
"question": "\nIn the game rules, what happens after the number of lives is exhausted?",
"score": 0.7918
}
],
"final_score": 0.7335
},
In the above comparison, true_answer is the annotated answer, answer is the answer of model inference, question is the question, and answer correlation needs to generate possible questions (question in infer_questions) based on the answer answer of model inference. Here are three, and then let the possible questions and the real questions be vectorized to find the cosine similarity. Under the short answer, it is difficult for the model to infer questions related to the real question question.
- The
answerof InternLM2-Chat-7B after fine-tuning is: "Kicked" - The
answerof DeepSeek-V3 is: "When the number of lives is exhausted, it will be counted as a kick."
It can be seen that because DeepSeek-V3 provides more information, the questions inferred by the evaluation model are more accurate, so the score is higher. But actually this is not what we expected, we wanted it to be short and precise, just like the standard answer "kick it to the punch"! Correspondingly, the semantic similarity cosine_score and exact_score we use here reflect the expectations very well.
Faithfulness makes little difference here:
After fine-tuning InternLM2-Chat-7B, faithfulness:
{
"context": "China (Nanjing) Chess Super Competition (Pearl Spring Super Tournament), formerly known as the China (Nanjing) Chess Grandmaster Invitational Tournament, the first competition was held at the Mingfa Pearl Spring Hotel in Pukou District, Nanjing from December 11 to 22, 2008. This competition was hosted by the Nanjing Municipal People's Government and the Chess and Card Sports Management Center of the State Sports General Administration, and was hosted by the Pukou District People's Government, Organized by the Nanjing Municipal Sports Bureau and co-organized by Kangyuan Pharmaceutical Co., Ltd., Yangtze Evening News, and Mondale International Entrepreneurship University, it is designated as a level 21 event by FIDE and is the highest level chess competition held in Asia so far. The competition will consist of ten rounds, with the first five rounds from December 11th to 15th, and a break on the 16th and 17th. The last 5 rounds were played on the 21st. Each side had 90 minutes and 30 seconds added to each move. The total prize money was 250,000 euros, of which the winner was 80,000 euros, and the second to sixth place were 55,000 euros, 30,000 euros, 25,000 euros, and 20,000 euros. As a result, Topalov won the championship, Aronyan won the runner-up, and Bu Xiangzhi won the third place. Name. It was admitted as a Grand Slam event on February 1, 2009 and was renamed the China (Nanjing) Chess Super Competition. The second competition was held from September 27 to October 9, 2009. The \"Kangyuan Pharmaceutical Cup\" 2010 China (Nanjing) Chess Super Competition was held from October 19 to 30, 2010.",
"exact_score": 1,
"cosine_score": 0.9999,
"origin_score": 1,
"question": "Where will the first competition be held?",
"true_answer": "Mingfa Pearl Spring Hotel, Pukou District, Nanjing",
"answer": "Mingfa Pearl Spring Hotel, Pukou District, Nanjing",
"statements": "\nThe first competition was held in Pukou District, Nanjing City.|||The specific location of the competition is Mingfa Pearl Spring Hotel.",
"scores": [
{
"statement": "The first competition was held in Pukou District, Nanjing.",
"score": 1
},
{
"statement": "The specific venue of the competition is Mingfa Pearl Spring Hotel.",
"score": 1
}
],
"final_score": 1.0
},
DeepSeek-V3, faithfulness:
{
"context": "China (Nanjing) Chess Super Competition (Pearl Spring Super Tournament), formerly known as the China (Nanjing) Chess Grandmaster Invitational Tournament, the first competition was held at the Mingfa Pearl Spring Hotel in Pukou District, Nanjing from December 11 to 22, 2008. This competition was hosted by the Nanjing Municipal People's Government and the Chess and Card Sports Management Center of the State Sports General Administration, and was hosted by the Pukou District People's Government, Organized by the Nanjing Municipal Sports Bureau and co-organized by Kangyuan Pharmaceutical Co., Ltd., Yangtze Evening News, and Mondale International Entrepreneurship University, it is designated as a level 21 event by FIDE and is the highest level chess competition held in Asia so far. The competition will consist of ten rounds, with the first five rounds from December 11th to 15th, and a break on the 16th and 17th. The last 5 rounds were played on the 21st. Each side had 90 minutes and 30 seconds added to each move. The total prize money was 250,000 euros, of which the winner was 80,000 euros, and the second to sixth place were 55,000 euros, 30,000 euros, 25,000 euros, and 20,000 euros. As a result, Topalov won the championship, Aronyan won the runner-up, and Bu Xiangzhi won the third place. Name. It was admitted as a Grand Slam event on February 1, 2009 and was renamed the China (Nanjing) Chess Super Competition. The second competition was held from September 27 to October 9, 2009. The \"Kangyuan Pharmaceutical Cup\" 2010 China (Nanjing) Chess Super Competition was held from October 19 to 30, 2010.",
"exact_score": 0,
"cosine_score": 0.5574,
"origin_score": 1,
"question": "Where will the first competition be held?",
"true_answer": "Mingfa Pearl Spring Hotel, Pukou District, Nanjing",
"answer": "The first competition was held at the Mingfa Pearl Spring Hotel in Pukou District, Nanjing from December 11 to 22, 2008.",
"statements": "\nThe first competition was held from December 11 to 22, 2008.|||The competition location is Pukou District, Nanjing City.|||The specific venue is Mingfa Pearl Spring Hotel.",
"scores": [
{
"statement": "The first competition was held from December 11 to 22, 2008.",
"score": 1
},
{
"statement": "The competition location is Pukou District, Nanjing City.",
"score": 1
},
{
"statement": "The specific venue is Mingfa Pearl Spring Hotel.",
"score": 1
}
],
"final_score": 1.0
},
In the above comparison, we can see that although DeepSeek-V3 provides more information, it is the same as the fine-tuned model. It basically uses the content in the original text to answer the questions as required. Therefore, although it has more statements (3), the final score is the same as the fine-tuned model. This explains why the final faithfulness scores are indistinguishable. It is worth noting that cosine_score semantic similarity and exact_score exact matching are used here to distinguish the difference between the two.
From the comparison results of the two indicators above, we can see that if there are specific task requirements for the generation module in the RAG system, the commonly used evaluation indicators cannot be measured well. At this time, the evaluation indicators need to be designed according to the final effect requirements of the task!
Use fine-tuned large models in RAG
LazyLLM supports one-stop fine-tuning, deployment, and inference, but what should you do if you have fine-tuned a large model and want to use it directly? It's very simple: the base_model remains unchanged, and you can use target_path to specify the fine-tuned model path, as shown below:
base_model = 'internlm2-chat-7b'
sft_model = '/path/to/sft/internlm2-chat-7b'
llm = lazyllm.TrainableModule(base_model, sft_model)
Taking the basic RAG as an example:
import os
import lazyllm
prompt = ('You will act as an AI question-answering assistant and complete a dialogue task.'
'In this task, you need to provide your answers based on the given context and questions.')
base_model = 'internlm2-chat-7b'
sft_model = '/path/to/sft/internlm2-chat-7b'
llm = lazyllm.TrainableModule(base_model, sft_model)
documents = lazyllm.Document(dataset_path=os.path.join(os.getcwd(), "KB"), embed=embed = lazyllm.TrainableModule('bge-large-zh-v1.5'), manager=False)
documents.create_node_group(name='split_sent', transform=lambda s: s.split('\n'))
with lazyllm.pipeline() as ppl:
ppl.retriever = lazyllm.Retriever(
doc=documents, group_name="split_sent", similarity="cosine", topk=1, output_format='content', join='')
ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | lazyllm.bind(query=ppl.input)
ppl.llm = llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
ppl.start()
Experimental process
The experimental processes of the three models are shown in the following videos:
- Deployment, reasoning and evaluation of Internlm2-Chat-7B:
- Fine-tuning, deployment, reasoning and evaluation of Internlm2-Chat-7B:
- Reasoning and evaluation of DeepSeek-V3:
Fine-tune the Embedding model based on LazyLLM
In the RAG (Retrieval-Augmented Generation) system, the Embedding model plays a key role:
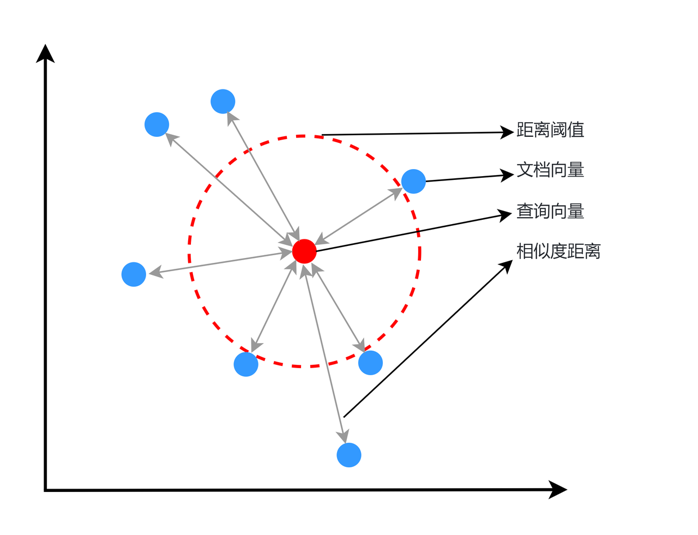
- Semantic encoding: Convert text data into high-dimensional vector representation, retaining semantic information
- Similarity calculation: Efficient correlation retrieval through vector cosine similarity
- Knowledge Base Index: Pre-coded document library to create a vector index for fast retrieval
- Query Understanding: Convert user query into vector and match the most relevant knowledge fragments
In this tutorial, we will use BAAI's bge-large-zh-v1.5 as the basic model to improve vertical field effects through financial field data fine-tuning (SFT).
Data preparation
In embedding learning, our goal is to:
- Semantically similar samples (positive pairs) are closer in vector space.
- Semantically irrelevant or opposite samples (negative pairs) are farther away.
The role of negative samples is to provide a comparison reference to let the model know "which ones should not be close." For example, when our query is "What is ChatGPT?", the doc of our positive sample is "ChatGPT is a language model developed by OpenAI, based on the Transformer architecture...", and the doc of our negative sample can be set to "Midjourney is an AI image generation model...".
Here we use the financial question and answer data set: virattt/financial-qa-10K for demonstration:
Data processing flow:
- Load the original data set
- Generate negative samples (10 negative examples for each sample)
- Create training set/evaluation set split (9:1 ratio)
- Build knowledge base files
The main code implementation is as follows:
def build_dataset_corpus(instruction: str, neg_num: int = 10, test_size: float = 0.1, seed: int = 1314) -> tuple:
"""Process dataset and create training/evaluation files.
Args:
instruction (str): Instruction template for prompts
neg_num (int): Number of negative samples per instance
test_size (float): Proportion of data for test split
seed (int): Random seed for reproducibility
Returns:
tuple: Paths to training data, evaluation data, and knowledge base directory
"""
# Load and preprocess dataset
ds = load_dataset("virattt/financial-qa-10K", split="train")
ds = ds.select_columns(column_names=["question", "context"])
ds = ds.rename_columns({"question": "query", "context": "pos"})
# Generate negative samples
np.random.seed(seed)
new_col = []
for i in range(len(ds)):
ids = np.random.randint(0, len(ds), size=neg_num)
while i in ids: # Ensure no self-match in negatives
ids = np.random.randint(0, len(ds), size=neg_num)
neg = [ds[int(i)]["pos"] for i in ids]
new_col.append(neg)
# Create dataset splits
ds = ds.add_column("neg", new_col)
def str_to_lst(data):
data["pos"] = [data["pos"]]
return data
ds = ds.map(str_to_lst) # Convert pos to list format
ds = ds.add_column("prompt", [instruction] * len(ds))
split = ds.train_test_split(test_size=test_size, shuffle=True, seed=seed)
# Save training data
train_data_path = build_data_path('dataset', 'train.json')
split["train"].to_json(train_data_path)
# Process and save evaluation data
test = split["test"].select_columns(["query", "pos"]).rename_column("pos", "corpus")
eval_data_path = build_data_path('dataset', 'eval.json')
test.to_json(eval_data_path)
# Create knowledge base
kb_data_path = build_data_path('KB', 'knowledge_base.txt')
corpus = "\n".join([''.join(item) for item in test['corpus']])
with open(kb_data_path, 'w', encoding='utf-8') as f:
f.write(corpus)
return train_data_path, eval_data_path, os.path.dirname(kb_data_path)
After processing, a piece of data from the training set is as follows (json file):
{"query":"What was the total stockholder's equity (deficit) for Peloton Interactive, Inc. as of June 30, 2021?","pos":["As of June 30, 2021, Peloton Interactive, Inc.'s consolidated statements reflected a total stockholder's equity (deficit) of $1,754.1 million."],"neg":["In June 2023, the company entered into an ASR agreement to repurchase $500 million of its common stock with a completion date no later than August 2023, and in 2024, the company expects to repurchase $2.0 billion of its common stock.",...,"\u2022Overhead costs as a percentage of net sales increased 40 basis points due to wage inflation and other cost increases, partially offset by the positive scale impacts of the net sales increase and productivity savings."],"prompt":"Represent this sentence for searching relevant passages: "}
The following fields need to be included:
query: (str) User questionpos: (List[str]) Correct answer paragraphneg: (List[str]) Randomly sampled negative samplesprompt: (str) command template
A piece of data from the evaluation set is as follows (json file):
{"query":"How have certain vendors been impacted in the supply chain financing market?","corpus":["Certain vendors have been impacted by volatility in the supply chain financing market."]}
The following fields need to be included:
query: user questionscorpus: the correct text fragment corresponding to the question
The knowledge base part is as follows (txt file):
Certain vendors have been impacted by volatility in the supply chain financing market.
Recruitment As the demand for global technical talent continues to be competitive, we have grown our technical workforce and have been successful in attracting top talent to NVIDIA. We have attracted strong talent globally with our differentiated hiring strategies for university, professional, executive and diverse recruits. The COVID-19 pandemic created expanded hiring opportunities in new geographies and provided increased flexibility for employees to work from locations of their choice. Our workforce is about 80% technical and about 50% hold advanced degrees.
In 2023, Moody’s Investors Service upgraded AbbVie’s senior unsecured long-term credit rating to A3 with a stable outlook from Baa1 with a positive outlook.
Fine-tuning process
Distributed fine-tuning through the LazyLLM framework:
embed = lazyllm.TrainableModule(embed_path)\
.mode('finetune').trainset(train_data_path)\
.finetune_method((
lazyllm.finetune.flagembedding,
{
'launcher': lazyllm.launchers.remote(nnode=1, nproc=1, ngpus=4),
'per_device_train_batch_size': 16,
'num_train_epochs': 2,
}
))
docs = Document(kb_path, embed=embed, manager=False)
docs.create_node_group(name='split_sent', transform=lambda s: s.split('\n'))
retriever = lazyllm.Retriever(doc=docs, group_name="split_sent", similarity="cosine", topk=1)
retriever.update()
This code is consistent with the previous configuration using LazyLLM's TrainableModule to fine-tune LLM:
embed_path: used to specify the fine-tuned model;train_data_path: Data set path used for training;lazyllm.finetune.flagembedding: specifies the fine-tuning framework;
Key parameters:
ngpus=4: Use 4 GPUs for parallel trainingper_device_batch_size=16: batch size per GPUnum_train_epochs=2: train for 2 epochs
It is worth noting that in the code here, we not only gave embed the fine-tuning configuration parameters, but also put it into the Document later. The Document registered a strategy to split the knowledge base document according to newlines. Finally, we also configured Retriever to act on the document and its corresponding segmentation method, and used cosine similarity as a measurement tool, while allowing only the most relevant text segment (topk=1) to be returned. Because LazyLLM supports one-click fine-tuning, deployment and inference, after executing update(), LazyLLM will first fine-tune the embed model, and then deploy the fine-tuned model to provide vectorization for Document and Retriever.
Effect evaluation
Here we use the contextual recall rate and Context Relevance introduced in the previous tutorial to evaluate our fine-tuned model. As a comparison, here we use
bge-large-zh-v1.5 is used as the base model, and the changes in the two indicators before and after fine-tuning are compared.
The call of the evaluation indicators is as follows:
from lazyllm.tools.eval import NonLLMContextRecall, ContextRelevance
def evaluate_results(data: list) -> tuple:
"""Evaluate retrieval results using multiple metrics.
Args:
data (list): List of retrieval results to evaluate
Returns:
tuple: Evaluation scores (context recall, context relevance)
"""
recall_eval = NonLLMContextRecall(binary=False)
relevance_eval = ContextRelevance()
return recall_eval(data), relevance_eval(data)
The logic of fine-tuning, deployment and inference is mainly as follows:
# Prepare dataset
train_data_path, eval_data_path, kb_path = build_dataset_corpus(
instruction=args.instruction,
neg_num=args.neg_num,
test_size=args.test_size,
seed=args.seed
)
# Deploy retrieval service
retriever = deploy_serve(
kb_path=kb_path,
embed_path=args.embed_path,
train_data_path=train_data_path,
train_flag=args.train_flag,
per_device_batch_size=args.per_device_batch_size,
num_epochs=args.num_epochs,
ngpus=args.ngpus
)
# Run SFT or Evaluation
results = []
query_corpus = load_json(eval_data_path)
for item in tqdm(query_corpus, desc="Processing queries"):
query = item['query']
inputs = f"{args.instruction}{query}" if args.use_instruction or args.train_flag else query
retrieved = retriever(inputs)
results.append({
'question': query,
'context_retrieved': [text.get_text() for text in retrieved],
'context_reference': item['corpus']
})
# Save and report results
save_json(results, args.output_path)
recall_score, relevance_score = evaluate_results(results)
print(f"Evaluation Complete!\nContext Recall: {recall_score}\nContext Relevance: {relevance_score}")
Based on the above logic, we obtain the following results:
| Before fine-tuningbge-large-zh-v1.5 | After fine-tuningbge-large-zh-v1.5 | |
|---|---|---|
| Context Recall | 78.28 | 88.57 |
| Context Relevance | 75.71 | 86.57 |
It can be seen that after fine-tuning, both indicators have been significantly improved. It shows that fine-tuning is effective! The overall evaluation process is: load the evaluation set → use the retrieval service (service deployed after fine-tuning) → perform batch inference → calculate dual indicators.
【bge-large-zh-v1.5 before fine-tuning】
【After fine-tuning bge-large-zh-v1.5】
Use the fine-tuned Embedding model in RAG
Similar to using a fine-tuned LLM, here we can also use a fine-tuned Embedding model, as shown below:
import os
import lazyllm
prompt = ('You will act as an AI question-answering assistant and complete a dialogue task.'
'In this task, you need to provide your answers based on the given context and questions.')
embed = lazyllm.TrainableModule('bge-large-zh-v1.5', 'path/to/sft/bge')
documents = lazyllm.Document(dataset_path=os.path.join(os.getcwd(), "KB"), embed=embed, manager=False)
documents.create_node_group(name='split_sent', transform=lambda s: s.split('\n'))
with lazyllm.pipeline() as ppl:
ppl.retriever = lazyllm.Retriever(
doc=documents, group_name="split_sent", similarity="cosine", topk=1, output_format='content', join='')
ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | lazyllm.bind(query=ppl.input)
ppl.llm = lazyllm.OnlineChatModule(source="sensenova")\
.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
ppl.start()
Further reading
More fine-tuning methods
From the perspective of the updated parameter range in the model, in addition to the LoRA fine-tuning introduced above, common fine-tuning includes full-parameter fine-tuning, frozen fine-tuning, etc.
1. Fine-tuning of all parameters
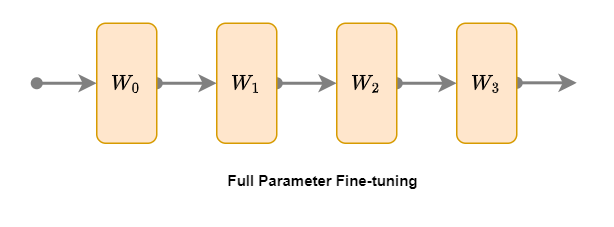
Full Parameter Fine-tuning is the most direct fine-tuning method. Its main idea is to fine-tune all parameters of the entire model for specific tasks on the basis of a pre-trained model (also a fine-tuned model). As shown in the figure above, the orange parameters of the four layers of the model: W1, W2, W3, and W4 are all involved in fine-tuning. The specific steps are as follows:
- Load the pre-trained model: Use the pre-trained large language model as the basic model.
- Prepare task data: Collect and organize relevant data based on specific tasks.
- Fine-tune the model: Input the task data into the model and update all parameters of the model through the back propagation algorithm.
- Evaluation and optimization: Evaluate the performance of the fine-tuned model on the validation set and optimize according to needs.
The advantage of full-parameter fine-tuning is that it can fully tap the potential of the model on specific tasks, but the disadvantage is that it consumes a lot of computing resources and is prone to over-fitting.
2. Freeze fine-tuning
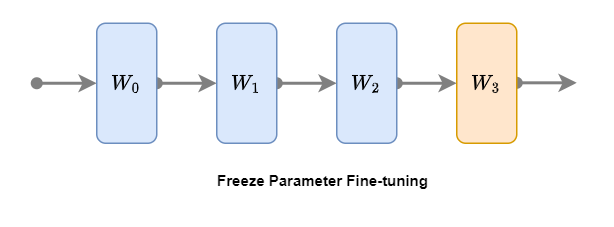
Freeze Parameter Fine-tuning is a fine-tuning method that saves computing resources. During the frozen fine-tuning process, the underlying parameters of the pre-trained model (also fine-tuned models) remain unchanged, and only some layer parameters are fine-tuned** (frozen fine-tuning can freeze any layer, and it is common to fine-tune the top layer of the model). As shown in the picture above, freeze the first three layers of the model, blue W0, W1, and W2, and only fine-tune the last (top) layer, orange W3. The specific steps are as follows:
- Load the pre-trained model: Use the pre-trained large language model.
- Freeze the underlying parameters: The underlying parameters of the model are fixed and will not participate in training.
- Fine-tune top-level parameters: Enter task data into the model and only update top-level parameters.
- Evaluation and optimization: Evaluate the model performance on the validation set and optimize according to needs.
The advantage of frozen fine-tuning is that it consumes less computing resources, but compared to full-parameter fine-tuning, model performance may be reduced.
We summarize these fine-tuning techniques as follows:
| Fine-tuning method | Computing resource consumption | Parameter update range | Advantages | Disadvantages |
|---|---|---|---|---|
| Full Parameter Fine-tuning | High | All parameters | Fully tap the potential of the model, strong adaptability | High resource consumption, easy to overfit |
| Freeze Fine-tuning (Freeze) | Low | Only some layer parameters | Save computing resources, fast training | Performance may not be as good as full parameter fine-tuning |
| LoRA fine-tuning | Medium | Low-rank matrix | Save resources and maintain the advantages of pre-training | There are certain restrictions on the model structure |
Fine-tune data format
As mentioned above, we have processed the data set fields into: Instruction, input and output formats, which are the data formats of Alpaca instruction fine-tuning. Here we not only introduce the instruction fine-tuning format in detail, but also introduce another commonly used format: the OpenAI instruction fine-tuning data format.
1. Alpaca command fine-tuning data format
Alpaca format is a data format used for command fine-tuning. It contains information such as commands, input, output, system prompt words, and historical conversations. The format is suitable for both single-turn and multi-turn conversation scenarios, allowing the model to generate more accurate answers based on historical information.
Basic data format
The basic structure of this data is as follows:
[
{
"instruction": "Human instructions (required)",
"input": "Human input (optional)",
"output": "Model's answer (required)",
"system": "System prompt word (optional)",
"history": [
["Instructions for the first round (optional)", "Answers for the first round (optional)"],
["Second round of instructions (optional)", "Second round of answers (optional)"]
]
}
]
1. “instruction” (required)
- Description: This field contains the instructions or questions given by the user, which is the core content that the model needs to understand and respond to.
- Example: For a single-turn conversation, it might be "Tell me what the weather is like today."; for a multi-turn conversation, it might be "I want to learn about artificial intelligence."
2. “input” (optional)
- Description: This field is used to provide additional input information, which may be background information, context or specific data related to the instruction.
- Example: In a single-round dialogue, if the instruction is "Translate the following sentence", the input may be "Hello, how are you?"; in a multi-round dialogue, supplementary information from the previous round of dialogue may not be filled in or provided.
3. “output” (required)
- Description: This field contains the answers or outputs generated by the model in response to the instructions and inputs.
- Example: For a single-turn conversation, it might be "The weather is sunny today and the temperature is 20 degrees Celsius."; for a multi-turn conversation, it might be "Artificial intelligence is a technology that simulates intelligent human behavior."
4. “system” (optional)
- Description: This field is used to provide system-level prompt words or instructions that can guide the model's behavior or answering style.
- Example: This might be “Please answer in a formal tone.” or “Try to use simple vocabulary when answering.”
5. “history” (optional)
- Description: This field is an array used to store historical information of multiple rounds of dialogue. Each element is an array containing two strings, representing the user instructions and model responses in one round of dialogue.
- Example: In a multi-turn conversation, the following historical information may be included:
[
["What is artificial intelligence?", "Artificial intelligence is technology that simulates human intelligent behavior."],
["What are the applications of artificial intelligence?", "Artificial intelligence is used in fields such as autonomous driving, speech recognition, and image processing."]
]
Single-turn dialogue example
[
{
"instruction": "Please tell me what the weather is like today.",
"input": "",
"output": "It's sunny today and the temperature is 20 degrees Celsius.",
"system": "",
"history": []
}
]
Multi-turn dialogue example
[
{
"instruction": "I want to know information about artificial intelligence.",
"input": "",
"output": "Artificial intelligence is technology that simulates human intelligent behavior.",
"system": "",
"history": [
["What is artificial intelligence?", "Artificial intelligence is technology that simulates human intelligent behavior."],
["What are the applications of artificial intelligence?", "Artificial intelligence is used in fields such as autonomous driving, speech recognition, and image processing."]
]
}
]
2. OpenAI command fine-tuning data format
The OpenAI format is a data format for command fine-tuning that organizes conversations by role and content. The role can be system, user or assistant, and the content is the speech of the corresponding role. The format works equally well for single-turn and multi-turn dialogue scenarios.
Basic data format
The basic structure of this data is as follows:
{
"messages": [
{
"role": "system",
"content": "System prompt word (optional)"
},
{
"role": "user",
"content": "Human instructions"
},
{
"role": "assistant",
"content": "Model answer"
}
]
}
1. “messages”
- Description: This field is an array that contains all the turns of the entire conversation. Each turn consists of "role" and "content".
2. “role”
- Description: This field indicates the role of the message, which can be "system", "user" or "assistant".
- "system": System prompt word, used to provide background information or guide the behavior of the model.
- “user”: User role, indicating the user’s instructions or questions.
- “assistant”: Assistant role, representing the model’s answer or output.
3. “content”
- Description: This field contains the specific content of the corresponding role.
- Example: For the "system" role, it might be "Please answer in a friendly tone."; For the "user" role, it might be "I would like to learn about artificial intelligence."; For the "assistant" role, it might be "Artificial intelligence is technology that simulates intelligent human behavior."
Single-turn dialogue example
{
"messages": [
{
"role": "system",
"content": ""
},
{
"role": "user",
"content": "Please tell me what the weather is like today."
},
{
"role": "assistant",
"content": "It's sunny today and the temperature is 20 degrees Celsius."
}
]
}
Multi-turn dialogue example
{
"messages": [
{
"role": "system",
"content": ""
},
{
"role": "user",
"content": "I want to learn about artificial intelligence."
},
{
"role": "assistant",
"content": "Artificial intelligence is technology that simulates human intelligent behavior."
},
{
"role": "user",
"content": "What are the applications of artificial intelligence?"
},
{
"role": "assistant",
"content": "Artificial intelligence is used in fields such as autonomous driving, speech recognition, and image processing."
}
]
}