Chapter 6: Retrieve with Higher Accuracy — Core Logic and Techniques for Improving RAG Recall Performance
In earlier lessons, we learned that a Retrieval-Augmented Generation (RAG) system combines two core components—retrieval and generation—to answer user queries based on external knowledge sources. This approach helps mitigate large-model hallucinations and enables domain-specific question answering with stronger contextual grounding. The basic idea of RAG is straightforward: the retrieval module first identifies relevant context from a large collection of documents, and the generation model then uses this retrieved information to produce more precise and reliable answers.
This article focuses on the performance evaluation method of the RAG system, focusing on how to evaluate the performance of the retrieval and generation components and related strategies to improve the effectiveness of the retrieval component. First, we will delve into the evaluation criteria of the retrieval component, including Recall and Context Relevance, to measure the coverage and precision of retrieval. Next, we will introduce the evaluation indicators of the generated components, such as Faithfulness and Answer Relevance, which are used to determine whether the generated content is accurate, trustworthy, and closely related to the retrieved content. After introducing the core evaluation indicators, we will further discuss common methods to improve the performance of the retrieval component, including query rewriting strategies, optimized retrieval strategies, and reordering strategies, to build a more accurate RAG retrieval component.
Evaluating RAG Performance
The RAG system combines the two components of retrieval and generation to find relevant information from external knowledge sources to combat the hallucination problem of large models and generate responses that fit the user's query context. The retrieval component recalls a small number of documents related to the user query from a large amount of external data, and then inputs these documents as context to the generation component to generate answers. Therefore, in a simple RAG system, we can evaluate the following links, and by improving the output indicators of these links, we can ultimately achieve the goal of improving the output of the RAG system:
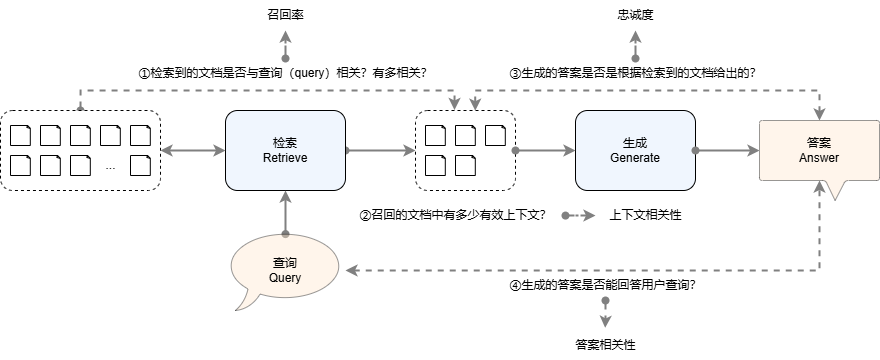 Figure 1: RAG evaluation dimensions and related methods
Figure 1: RAG evaluation dimensions and related methods
(1) Are the documents recalled by the retrieval component from a large number of external data sources relevant to the user query, and how relevant are they? This link determines whether the context obtained by the generation component is relevant to the user's query. In other words, whether the system can generate answers that match the user's query context depends on the relevance of the documents recalled by the retrieval component to the query. We usually measure the relevance of the documents recalled by the retrieval component to the user query through the recall rate indicator. The higher the recall rate, the more relevant context the generation component obtains, and the more likely it is to generate answers that are highly relevant to the user query. When the recall rate is very low, the system effect will be similar to the generation component directly answering the user's question.
(2) How many valid contexts are there in the documents recalled by the retrieval component? Generally speaking, the document length recalled by the retrieval component is relatively large. At this time, there is no guarantee that all the information in the entire document is relevant to the query. At this time, the noise may cause the final answer to be significantly different from the target answer. Context Relevance (Context Relevance) in the RAGAS framework is usually used to evaluate this link to calculate the proportion of context related to the query.
(3) Are the answers given by the generation component relevant to the context provided by the retrieval component? The ability of the generation component determines whether the generation component can fully utilize this information to give answers that fit the query context when the retrieval component provides context that is highly relevant to the user's query. There are currently a variety of large language models to choose from. How to choose the generation component that is most suitable for the current system first needs to measure this ability. Faithfulness in the RAGAS framework is an important indicator to measure whether a large model can generate a model that is highly relevant to the provided context.
(4) Is the system’s final answer relevant to the user’s query? Improving the correlation between RAG system answers and user queries is the ultimate optimization goal of the RAG system. We usually evaluate this through the Answer Relevance (Answer Relevance) in the RAGAS framework.
An ideal RAG system should have high recall and context relevance scores in the retrieval component, and high fidelity and Answer Relevance scores in the generation component.
Retrieve component evaluation
In RAG practice, the quality of the retrieval component is usually evaluated by looking at the results between query and recall. Commonly used evaluation indicators include recall and context relevance. The recall rate refers to how many documents related to the query are recalled by the system from the document library, measuring the recall rate of the system; while the Context Relevance measures the proportion of sentences related to the query in the recalled documents to the total number of sentences. The higher the value for both values, the better. The higher the value, the more relevant the context provided by the retrieval component is to the user query, which helps the system output answers that are highly relevant to the question.
1. Recall rate
Recall is the ratio of the number of retrieved relevant documents to the number of all relevant documents in the document library. It measures the recall rate of the retriever, that is, how many of all relevant documents have been retrieved. The calculation formula for recall rate is as follows:
Among them, TP (True Positive) represents the samples whose true category is positive and the result is also a positive example, that is, the number of documents related to the query in the retrieval results; FN (False Negative) represents the sample whose true category is positive but the result is identified as a negative example, that is, the relevant documents that have not been recalled. For example, there are 5 documents in the document library that are related to the current query, but the retrieval component retrieves only 3 documents, so the recall rate is 3/5=0.6. In practical applications, the higher the recall rate, the more relevant evidence is provided to the generation component, which helps to improve the overall effect of RAG.
2. Context Relevance
The above recall rate is an evaluation method at the document block level. In addition, a more fine-grained evaluation method can be constructed to evaluate the retriever. RAGAS is an advanced RAG evaluation system [Reference 1]. Here is a brief introduction to its proposed context relevance.
Context Relevance extracts sentences related to the query on the retrieved documents, and then calculates the accuracy at the sentence level. Its calculation method can be expressed as:
Context Relevance mainly measures the proportion of sentences related to the query in the context given by the retrieval component. The higher the value, the more effective reference content the context contains, which is helpful for the generation component to extract key evidence from it. For example, there are 5 documents in the document library that are related to the current query, but the search component only retrieves 3 documents. These 3 documents contain a total of 10 sentences, and there are only 4 sentences related to the query. The CR value is 4/10=0.4.
Generate component evaluation
The generation component of RAG mainly generates answers through the documents given by the retrieval component, which is mainly evaluated from two dimensions: faithfulness (faithfulness) and Answer Relevance (Answer Relevance). Fidelity evaluates whether the answers given by the generation component are related to the context given by the retrieval component, which is crucial to combating the large model illusion, while answer correlation requires evaluating whether the answers given by the generation component can accurately respond to the question.
1. Faithfulness
When the answer given by the generating component can be found in the context, the answer a is said to be loyal to the context c. In order to construct objective calculation indicators, the following process is usually followed:
(1) Use LLM to extract a series of sentences from the answer. The purpose of this step is to reduce long and difficult sentences into multiple concise and accurate assertions S (or propositions);
(2) Input the assertion S extracted in the previous step and the context given by the retriever to LLM, and let LLM infer whether these assertions come from the retrieval context;
(3) Calculate the final score
Where |V| is the number of assertions derived from the search context, and |S| is the number of all assertions. The larger the value, the higher the faithfulness of the system. Let’s look at an example:
Query: Which is the tallest mountain on Earth? Context: Mount Everest is the highest mountain on Earth, with an altitude of approximately 8848.86 meters, located on the border of Nepal and Tibet, China. Highly loyal answer: The highest mountain on Earth is Mount Everest, with an altitude of 8848.86 meters. Low faithfulness answer: The tallest mountain on Earth is Mount Everest, at 5895 meters above sea level.
Let’s take the low-faithfulness answer among them as an example to construct an assertion
Assertion 1: The tallest mountain on earth is Mount Everest.
Assertion 2: The highest mountain on Earth is 5895 meters above sea level.
At this time, the answer that the large model should output is:
Assertion 1: Yes.
Assertion 2: No.
So for the answer to this question, the system has a faithfulness score of 0.5.
2. Answer Relevance
Answer Relevance (AR) measures the quality of the answers generated to user queries, that is, the relevance of the answers to the user's questions, checking whether the answers are complete and whether they contain redundant information. To evaluate this, N questions are generated through a large model, which should be highly similar to the original question if the provided answer is relevant to the original question. The process can be broken down into:
(1) Given an answer, let LLM generate N questions that may correspond to the answer. N is generally between 3 and 4;
(2) Vector embedding for all possible questions;
(3) Calculate the similarity between the potential question vector qi and the original query vector q:
Where sim can be a vector similarity calculation method such as cosine similarity. Also for the answer "The highest mountain on earth is Mount Everest, with an altitude of 8848.86 meters", a large model is used to generate the answer, and the following three possible questions are obtained:
Question 1: Which is the tallest mountain on earth?
Question 2: What is the altitude of Mount Everest?
Question 3: Which mountain has the highest altitude in the world?
Then the vectors of the above three questions are combined with the query vector q, that is, "Which is the highest mountain on Earth?", to calculate the average similarity.
Complete example for evaluation
Let's look at a complete example below. Assume that there are 10 paragraphs in our document library. For the query: "What are the applications of deep learning?", we perform document retrieval, question and answer, and perform indicator calculations.
**Document library content (where ✅ is a document related to the query, ❌ is irrelevant): **
✅ Deep learning is widely used in computer vision, such as image classification, target detection and autonomous driving. It can improve the accuracy of image recognition and enable autonomous vehicles to perceive the surrounding environment in real time.
❌ Traditional machine learning relies on manual feature engineering, while deep learning automatically learns features. In contrast, deep neural networks can automatically extract effective features from massive data and reduce manual intervention.
✅ Deep learning can be used in medical image analysis to assist doctors in diagnosing diseases. For example, AI can automatically identify abnormalities in X-rays and improve the accuracy of early detection of diseases.
✅ Deep learning plays an important role in recommendation systems, such as Netflix and Taobao recommendation algorithms. It can analyze users' browsing and purchase records and provide personalized content recommendations.
❌ Deep learning has high computational complexity and requires GPU acceleration. The support of high-performance computing equipment enables deep learning to process large-scale data and increase training speed.
✅ Natural language processing is an important application of deep learning, including machine translation and dialogue systems. NLP technology based on deep learning makes the translation system more natural and smooth, and improves the understanding ability of intelligent assistants.
✅ The financial industry has also benefited from deep learning, especially in fraud detection and stock market predictions. For example, AI can analyze transaction patterns and identify abnormal behavior to prevent fraud.
❌ Recurrent Neural Network (RNN) is suitable for time series forecasting. It can be used for financial market analysis and predicting stock price trends.
❌ Convolutional neural network (CNN) has remarkable effects in image processing. It can automatically extract features such as edges and shapes of images to improve the performance of computer vision tasks.
✅ Reinforcement learning is a part of deep learning that has been applied to game AI such as AlphaGo. By constantly playing against itself, AI can learn the best strategies and surpass human masters in games such as Go.
For the query **: "What are the applications of deep learning?", the sentences recalled by keyword search include the following 5 sentences: **
✅ Deep learning is widely used in computer vision, such as image classification, target detection and autonomous driving. It can improve the accuracy of image recognition and enable autonomous vehicles to perceive the surrounding environment in real time.
❌ Traditional machine learning relies on manual feature engineering, while deep learning automatically learns features. In contrast, deep neural networks can automatically extract effective features from massive data and reduce manual intervention.
✅ Deep learning can be used in medical image analysis to assist doctors in diagnosing diseases. For example, AI can automatically identify abnormalities in X-rays and improve the accuracy of early detection of diseases.
✅ Deep learning plays an important role in recommendation systems, such as Netflix and Taobao recommendation algorithms. It can analyze users' browsing and purchase records and provide personalized content recommendations.
❌ Deep learning has high computational complexity and requires GPU acceleration. The support of high-performance computing equipment enables deep learning to process large-scale data and increase training speed.
Search recall rate:
There are 3 sentences that are correct (really relevant) and 2 sentences that are wrong (do not belong to the application). There are a total of 6 sentences related to deep learning applications in the document library, so the recall rate is 3/6=0.5;
Retrieve Context Relevance:
Among the 5 sentences recalled, there are 10 sentences, 3 of which are related to the query, so their Context Relevance is 3/5=0.6;
For ** "What are the applications of deep learning?" and the retrieved context, the model (internlm2-7b) gives the answer: **
Deep learning is widely used in many fields. The following are some key application areas: 1. Computer Vision: Deep learning plays an important role in computer vision tasks such as image classification, target detection and autonomous driving. Through deep neural networks, deep learning can automatically extract and identify features in images from large amounts of data, improving self-driving vehicles' ability to perceive the surrounding environment, thereby improving safety. 2. Medical health: In the field of medical image analysis, deep learning can help doctors diagnose diseases quickly and accurately. For example, AI can automatically identify abnormalities in X-rays, thereby improving the accuracy of early detection of diseases and helping to provide earlier intervention and treatment. 3. Recommendation system: Deep learning is widely used in recommendation systems, such as Netflix and Taobao’s recommendation algorithms. By analyzing users' browsing and purchase records, deep learning can personalize content recommendations and improve user satisfaction and purchase conversion rates. 4. Natural language processing: Deep learning also has significant applications in text analysis, speech recognition, machine translation, etc. By learning a large amount of language data, deep learning models can understand and generate natural language to provide support for applications such as intelligent customer service and intelligent assistants. 5. Financial services: Deep learning has applications in fraud detection, risk assessment and investment strategies. By analyzing large amounts of financial data, deep learning can help financial institutions better identify risks, optimize investment portfolios, and improve business efficiency. 6. Scientific research: Deep learning is also widely used in scientific research, such as data processing and pattern recognition in astronomy, biology, chemistry and other fields. Through deep learning, scientists can process and analyze complex data more quickly, thereby advancing scientific research. 7. Game development: Deep learning plays an important role in game AI, which can help game characters better understand game rules and player behavior, and provide a more intelligent game experience. 8. Industrial Automation: In the fields of manufacturing and industrial automation, deep learning can be used to predict equipment failures, optimize production processes, and improve product quality. By analyzing sensor data, deep learning models can provide early warning of failures, reducing downtime and production costs. In short, deep learning has a wide range of applications and is changing the way various industries operate and providing more efficient and smarter solutions. With the continuous advancement of technology and optimization of algorithms, the application prospects of deep learning are still broad.
**Use LLM to extract assertions (limited to 10, extracted by ChatGPT): **
"Deep learning plays an important role in computer vision tasks."
"Deep learning can improve self-driving vehicles' ability to perceive their surroundings."
"Deep learning can help doctors diagnose diseases quickly and accurately."
"Deep learning can automatically identify abnormalities in X-rays and improve the accuracy of early detection of disease."
"Deep learning is widely used in recommendation systems, such as Netflix and Taobao's recommendation algorithms."
"Deep learning is used for natural language processing tasks such as text analysis, speech recognition, and machine translation."
"Deep learning can help financial institutions identify risks and optimize investment strategies."
"Deep learning is used for data processing and pattern recognition in scientific research."
"Deep learning can optimize production processes and product quality in industrial automation."
"Deep learning is changing the way industries operate and delivering more efficient and smarter solutions."
**LLM infers whether these assertions come from a retrieval context (ChatGPT): **
"Deep learning plays an important role in computer vision tasks.": 1
"Deep learning can improve self-driving vehicles' ability to perceive their surroundings.": 1
"Deep learning can help doctors diagnose diseases quickly and accurately.": 1
"Deep learning can automatically identify abnormalities in X-rays and improve the accuracy of early detection of diseases.": 1
"Deep learning is widely used in recommendation systems, such as Netflix and Taobao's recommendation algorithms.": 1
"Deep learning is used for natural language processing tasks such as text analysis, speech recognition, and machine translation.": 1
"Deep learning can help financial institutions identify risks and optimize investment strategies.": 0
"Deep learning is used for data processing and pattern recognition in scientific research.": 0
"Deep learning can optimize production processes and product quality in industrial automation.": 0
"Deep learning is changing the way industries operate and delivering more efficient and smarter solutions.": 0
Calculate faithfulness to get:
6/10 = 0.6
LLM generates possible questions based on large model answers:
In which fields does deep learning have important applications?
**Calculate the similarity between the original question "What are the applications of deep learning?" and the most likely question generated by LLM "In which fields is deep learning important?" (here, cosine similarity is used as an example): **
The calculation result is 0.8.
| Recall | Context Relevance | Faithfulness | Answer Relevance |
|---|---|---|---|
| 0.5 | 0.6 | 0.6 | 0.8 |
Based on the indicators in the above examples, we can see that the optimization of every link is crucial. Judging from the current indicators, the recall rate (0.5) shows that there is still much room for improvement in the retrieved relevant documents. The original text provided 6 depth-related paragraphs but only 3 were recalled. Improving the comprehensiveness of the retrieval will help the large model obtain more comprehensive information and give answers with higher credibility. In this example, the context correlation index is (0.6), which is the same as the recall rate. However, in reality, when a paragraph contains multiple sentences, the content will be more divergent. Therefore, how to perform more concentrated segmentation for longer paragraphs can further improve the context correlation. Faithfulness (0.6) is low, indicating that the generated answers deviate from the original content, and the knowledge integration strategy needs to be optimized to ensure that the output is highly consistent with the retrieved content. For example, this example does not recall documents related to the financial field, but gives relevant answers. This is a sign of low faithfulness in the model generated results. Although the answer given in this example is quite reasonable, this phenomenon is not good if it is in a field that is highly professional and requires strong data support.
If you only look at the answer correlation (0.8) index, you will come to the conclusion that the current system is extremely effective, but in fact the system's retrieval effect on the document library and its faithfulness to the given context are not high. This is why it is necessary to evaluate each link of the RAG system through multiple indicators. Overall, improving recall rate, enhancing faithfulness, and making detailed adjustments in context relevance and Answer Relevance will significantly improve the overall performance of the RAG system.
Improve the recall rate of RAG system
In the RAG system, the core task of the retrieval component is to find the context most relevant to the user query from a large-scale document library and provide it to the generation component as auxiliary information. The quality of the documents output by the retrieval component directly determines the accuracy, information coverage, and overall readability of the final generated content. If the retrieved context lacks key information, contains a lot of noise, or does not accurately reflect user intent, then no matter how powerful the generative model itself is, it will be difficult to produce high-quality answers. Therefore, optimizing the retrieval process and maximizing the recall rate is one of the key challenges to improve the effectiveness of RAG.
This section will focus on the optimization strategy of the retrieval component of the RAG system. According to the execution process of the system, several common recall rate improvement methods will be introduced from upstream to downstream. First, we discuss Query Rewrite Strategy (Query Rewrite), that is, how to rewrite user queries to express retrieval needs more accurately and improve the coverage and relevance of recall results. Subsequently, we introduce retrieval strategy optimization, including using node groups, selecting appropriate document representation methods, and appropriate retrieval methods. Finally, we discuss Reranking (Reranking), that is, how to use the reranking model to rearrange the documents after obtaining the preliminary search results so that the most relevant information is ranked first. Through the comprehensive application of these methods, we can further realize multi-channel recall RAG, effectively improve the recall rate and context quality of the RAG system, and thereby improve the accuracy, completeness and readability of the final generated results.
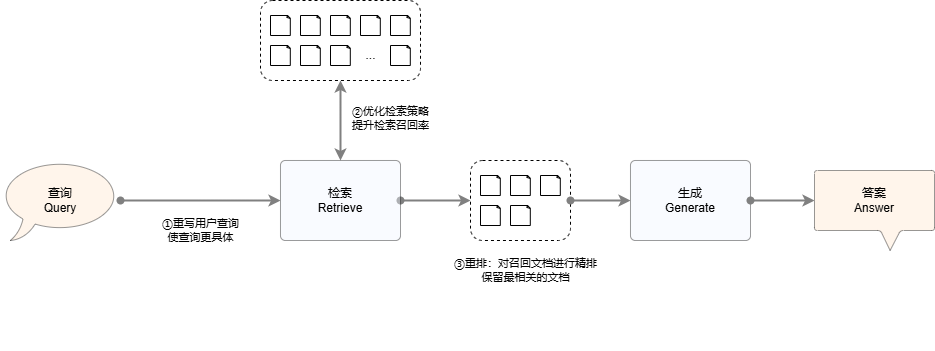 Figure 2: Common optimization methods to improve the recall rate of RAG systems
Figure 2: Common optimization methods to improve the recall rate of RAG systems
RAG performance, focusing on R
Example case: Optimization effect of an enterprise’s internal knowledge question and answer system
Background: An enterprise deployed an internal knowledge question and answer system based on RAG for employees to quickly query policies and procedures. However, the initial results were not good and user feedback accuracy was low.

By introducing multi-channel recall, optimizing the reordering strategy and fine-tuning the generation model, the accuracy of each stage of the RAG system has been significantly improved. In particular, the recall accuracy has increased from 40% to 95%, which has led to the subsequent rearrangement accuracy to 92% and the question and answer accuracy to 88%. This shows that: The recall stage is a key link to improve the performance of the entire RAG system. High-quality recall not only improves document relevance, but also provides more accurate and rich context for the generated components, thereby significantly improving the accuracy and reliability of the final answer.
Query rewrite strategy
In practical applications, the queries entered by users are usually unpredictable, so it is not easy to directly hit the most relevant documents for the query from the candidate set. Query rewriting technology can handle the ambiguity of user queries and guide them to clarify the user's true intention to retrieve accurate documents. In addition, query rewriting can also enhance the diversity of retrieval and collect information from multiple dimensions. Here are several simple query rewriting strategies.
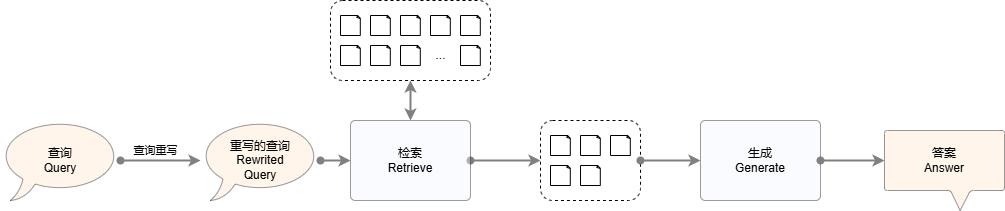 Figure 3: RAG system process for applying query rewrite strategy
Figure 3: RAG system process for applying query rewrite strategy
1. Expanded query
Queries entered by users are often ambiguous or lack sufficient contextual information, making it difficult for systems to accurately understand their intent and return the most relevant results. Query expansion is an effective optimization strategy that supplements, transforms or optimizes the original query to make it more specific and clear, thereby improving the accuracy of retrieval and the comprehensiveness of recall.
There are many methods of query expansion, and common strategies include synonym expansion, context supplementation, and question template transformation. Synonym expansion can increase the expressive richness of the query and improve the diversity of search results; context supplementation can use historical conversation information or the user's previous queries to supplement key information and reduce ambiguity; and question template conversion can structure the query so that it is more in line with the best matching mode of the retrieval system, thereby improving the search effect. These methods and their application scenarios will be introduced in detail below.
(1) Synonym expansion: By introducing synonyms or related words, the scope of the query can be expanded, thereby improving the diversity and comprehensiveness of the results. For example, the query "healthy diet" can be expanded into multiple forms such as "healthy diet, healthy diet recommendations, how to maintain a healthy diet" to provide multiple perspectives.
(2) Contextual supplementation: Modify the current query to make it more specific by analyzing conversation history or previous queries. For example, in weather-related topics, if the user has already asked about the weather in a certain place that day, and then asks "What will the weather be like in the next 14 days?", the area in the historical record should be expanded to the latest query.
(3) Question template conversion: Enhance the retrieval effect by converting the query into a specific question template, for example, rewriting the query "What is xxx?" into "What is the definition of xxx?".
2. Sub-question query
The core idea of the sub-question query strategy is to generate and ask sub-questions related to the main question to better understand and answer the main question. Subproblems are usually more specific and can help the system understand the main problem more deeply, and are usually used for more abstract problems. The simple subquery construction process can be summarized as the following flow chart:
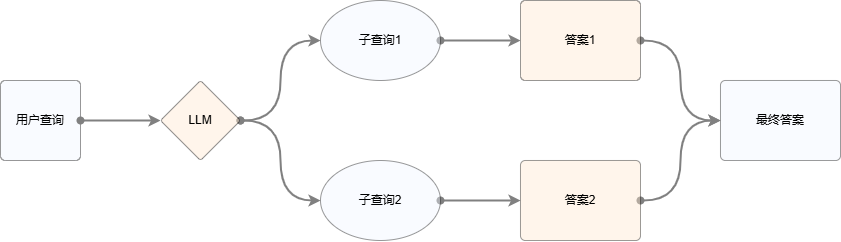 Figure 4: Schematic diagram of sub-problem query strategy
Figure 4: Schematic diagram of sub-problem query strategy
(1) Generate multiple sub-questions from user queries through LLM. For example, for the original question "What is RAG?", the following sub-query decomposition can be performed: "What is the definition of RAG?", "What are the characteristics of RAG?", "What is the principle of RAG?", etc. The sub-query construction can provide multiple perspectives for the question, thereby making the answer more specific and comprehensive;
(2) Each sub-question goes through RAG to obtain relevant answers;
(3) Combine all questions to get the final answer.
Although the sub-problem method can improve the recall diversity of the retrieval component, it also brings a large time loss. At this time, engineering optimization may need to be carried out simultaneously to ensure that the system response time does not take too long. You can also consider only retrieving sub-questions without generating answers for each sub-question, and pass all relevant documents and main questions into the generation component.
3. Multi-step query
The core idea of multi-step query is to use a large model to decompose a complex query into multiple sub-questions. First, sub-question 1 is generated and the answer is obtained, and then the answer and context are input into the large model to generate sub-question 2, etc., and the process is advanced layer by layer until the final answer is obtained. It is suitable for scenarios that require multiple rounds of reasoning or information concatenation.
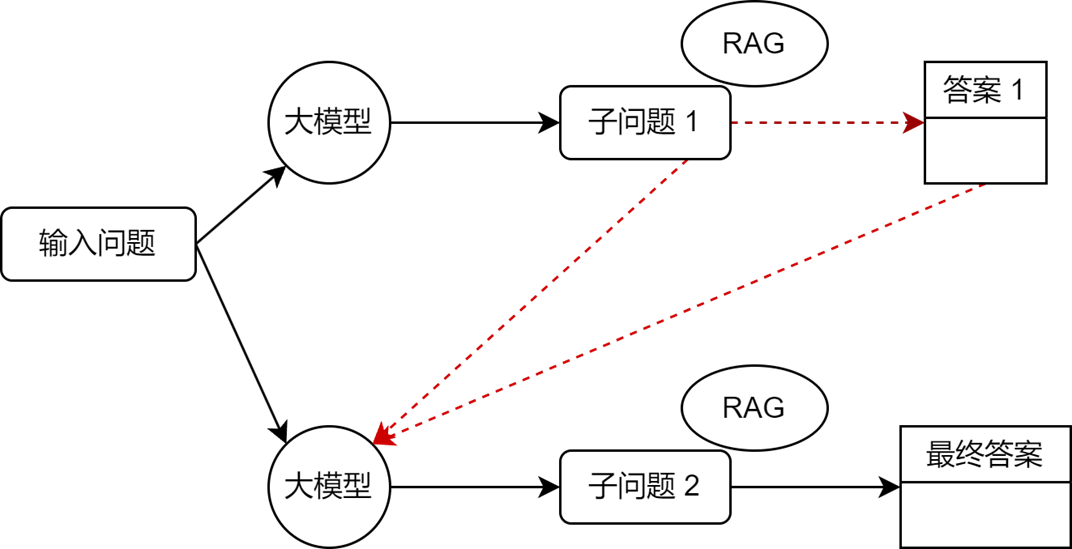
For example, when we ask the question: "How high is the highest mountain in the world?" the system will first break it down into sub-question one: "What is the highest mountain in the world?" and get the answer: "Mount Everest." It then uses sub-question one and its answer as context to generate sub-question two: "How high is Mount Everest?" Finally, by answering sub-question two, we get the exact answer to the original question. The simple multi-step query construction process is as shown in the flow chart above.
In addition to the above three simple query rewriting methods, HyDE, backtracking prompts and other methods are currently commonly used to generate richer and more specific queries. Interested readers can consult related papers to learn. Query rewriting methods can provide dynamic adjustments based on the specific needs and context of users, helping to achieve more accurate and comprehensive document recall.
Optimize search strategy
Retrieval refers to a technology that starts from the specific information needs of users, uses certain methods for specific information collections, and finds relevant information based on certain clues and rules. Figure 5 shows a simple retrieval process. First, the given query is compared with five documents in the document library. It is found that the documents with id 2 and 3 are more relevant to the query, so these two documents are returned.
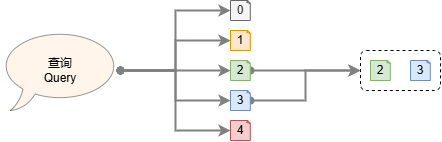
Figure 5: A simple retrieval process, calculating the relevance of each document and returning the most relevant document
One of the most important and challenging issues in the retrieval process is how to measure the relevance of the query and the document and find the document closest to the query. Based on the existing natural language processing technology and information retrieval related technology, we can optimize from the following dimensions:
(1) Retrieved object (Node Group): Split a single document into multiple highly targeted sub-units. Long documents usually contain multiple topics, and during direct retrieval, related content may not be successfully recalled due to scattered topics. However, through reasonable strategies such as chunking or summary extraction, long texts can be broken down into more targeted fragments, allowing the retrieval system to more accurately match the query content, thus improving the recall rate and retrieval quality of relevant information. In RAG, this strategy is called document parsing, and all document fragments parsed by the same rule are called a node group. Different node groups are suitable for tasks with different characteristics.
(2) The representation method of the retrieved object (original text vs vectorization): whether to vectorize the text or not, if so, which vectorization model to choose. Appropriate document representation methods can provide certain help for the accuracy of retrieval. Vectorized document representation methods can retain semantic information and recall documents with high semantic similarity, while documents without vectorization can quickly find paragraphs where relevant keywords appear.
(3) Specific retrieval method of the retrieval object (similarity, Similarity): Select the appropriate similarity calculation method according to the representation method of the retrieval object. After selecting the document representation method, you need to choose an appropriate similarity calculation method for recall. For example, if you choose the original text representation, it is not suitable to use vector similarity as a similarity measure.
Combining the above three dimensions, the recall rate of the retrieval component can be greatly improved, and the downstream context can be provided with a higher similarity to the query. The details and appropriate scenarios of the above three strategies will be introduced in detail below.
Node group
This section discusses two common node group construction methods in RAG systems, namely the node construction strategy based on binning and blocking and the node construction strategy based on semantic extraction. The document chunking section focuses on analyzing fixed size chunking (Fixed Size Chunking) and recursive chunking (Recursive Chunking). The fixed-size chunking method is simple and straightforward, but may destroy the semantic coherence of the text; while the recursive chunking method can better preserve semantic integrity by introducing delimiters to divide the text. Subsequently, we will introduce how to use abstraction, keyword extraction, question and answer pair extraction and other methods to generate nodes with more prominent semantic information to optimize the retrieval effect. For example, summaries can help the system quickly obtain key information, keyword extraction can speed up retrieval, and question and answer pairs can directly provide standardized and efficient responses. Through the study of this section, you will understand how different node construction strategies affect the recall effect of the RAG system, and learn how to select the appropriate node group for specific tasks to improve the accuracy and efficiency of information retrieval.
The node group is the object on which the retrieval component performs the retrieval operation. A retrieval is only performed on one node group. Figure 5 shows how node groups are constructed from the original text: several different node groups are obtained by applying different parsing rules for all documents in the document set. The content in different node groups is different from each other. For example, document block node groups with different granularities are obtained by dividing the document into different length constraints, or node groups with the same theme but different texts are obtained through semantic processing methods such as summary extraction.
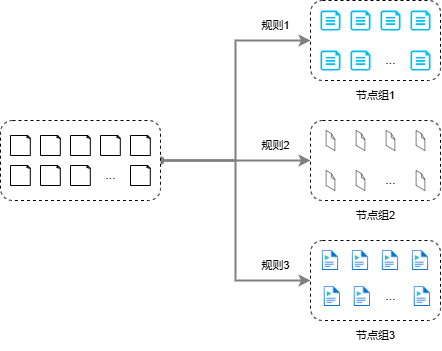
Figure 6: Multiple node groups are constructed from source documents according to different rules
1. Node group construction method based on document chunking:
A long text usually contains multiple topics, and system processing efficiency will decrease when the document is too long. Document chunking (Chunking) is a method of dividing a document into multiple sub-paragraphs. The divided paragraphs focus on different topics, the content is more targeted, and it is easier to return accurate results in specific queries. The choice of document chunking strategy will have a certain correlation with the task. Reasonable selection of chunking strategies based on different tasks will be helpful to improve the RAG recall effect. The two most commonly used document chunking strategies are fixed-size chunking and recursive chunking, which perform well in most tasks.
(1) Fixed Size Chunking
Fixed-size chunking is the most direct and common chunking method. It splits the text directly into blocks of predetermined size. For example, we specify that every 20 "words" are divided into a block. However, the concept of "word" is not accurate in large model processing tasks. We usually use "token" as the unit. A token can be a word, a punctuation mark, a number, a symbol, etc. Although the fixed-size chunking approach is low-cost, it lacks context awareness and often ignores document content or form. We can improve this by using overlapping blocks, allowing adjacent blocks to share some content. Figure 7(1) The example on the left is an example of fixed-size blocking (where each color represents a block, and the green part is the overlap between adjacent blocks. The fixed size selected in this example is 25, and the number of overlaps is 5). Observing the blocking results, it can be seen that the sentence "One is a jujube tree" is forcibly divided into two parts. We cannot obtain the detailed information of the two trees through the first document block, nor can we obtain from the second document block that the jujube tree is in the back garden, which destroys the coherence of the document.
(2) Recursive Chunking
Unlike fixed-size chunking, recursive chunking improves processing efficiency and contextual understanding by gradually subdividing text. Specifically, recursive chunking first splits the text using primary delimiters (such as paragraphs) and then applies secondary delimiters (such as sentences) if the chunk is still too large. In this way, during each chunking process, the model will rely on information retrieval to obtain relevant context, thereby enhancing the accuracy and quality of generation. This recursive chunking method can handle longer texts without losing key information. Compared with fixed-size chunking, this method can retain a certain degree of semantic coherence and ensure that the semantic content of each chunk is complete. For example, the example on the right in Figure 7(2) below shows an example of using newlines as delimiters. Compared with fixed-size chunking, this method can retain a certain degree of semantic coherence and ensure that the semantic content of each chunk is complete.

Figure 7 (1): Example of document blocking effect. Each colored paragraph in the picture will be treated as a node. The left side is the fixed size blocking method, and the right side is the recursive blocking method.
(3) Semantic chunking
Semantic chunking is a chunking method based on text semantic information. It does not rely on simple characters or word lengths, but segments based on semantic units in the text. Specifically, it first vectorizes the text, then calculates the cosine distance between embeddings, and combines embeddings with close feature distances together to form a block. In this way, the text is broken into chunks with semantic integrity and coherence, and the content within each chunk usually revolves around a specific theme or meaning. For example, the example on the left in Figure 7(2) performs semantic segmentation on the document. It can be seen that the title and corresponding content are divided into one block. Compared with segmenting directly based on line breaks ("\n"), a certain degree of semantic continuity is ensured.
(4) Document-based chunking
Document-based chunking is common in large-scale text processing and information retrieval systems. Unlike traditional character- or word-based chunking methods, this method creates chunks based on natural divisions in the document (such as titles or chapters), with each document acting as an independent processing unit. This chunking method helps maintain the overall context and information structure of the text. This approach works particularly well for structured data such as HTML, Markdown, or code files, but is less useful when the data lacks clear structural elements. For example, the example on the right side of Figure 7 (2), compared to the example on the left side of Figure 7 (1), the title and content are better distinguished, and the structure of the original text is maintained without being destroyed.

Figure 7(2): Example of document chunking effect. Each colored paragraph in the figure will be treated as a node. The left side is the semantic chunking method, and the right side is the chunking method based on document characteristics.
2. Node group construction method based on semantic extraction:
When we use symbol-level chunking to process documents, we often encounter problems such as missing context and insufficient syntax and semantic understanding when faced with complex structured data, long texts, or information integration problems across multiple documents. This is because traditional symbol-level chunking methods mainly focus on the literal level of text and cannot effectively capture deeper semantic and contextual connections. In order to make up for this shortcoming, we can introduce text containing certain semantic information such as abstracts or keywords for retrieval. Currently, the construction of these node groups does not require manual extraction one by one, and can be implemented directly by calling a large model. For example, abstracts can quickly extract key information and reduce interference from irrelevant content; keywords can speed up the retrieval process and shorten query response times; question and answer pairs can provide instant and accurate responses through standardized questions and answers, improving user experience.
The following is a simple explanation of the advantages of summary, keywords, and Q&A for node groups through a printer after-sales service scenario:
(1) Keyword node group:
User asked: "How to clean the printer's ink cartridges?"
If the document does not have valid tags and keywords, the system may need to find information related to "Ink Cartridge Cleaning" paragraph by paragraph, resulting in inefficiency. If we use keyword extraction technology to extract keywords related to "ink cartridge cleaning" from the document, such as "ink cartridge", "cleaning", "cleaning steps", etc., then through these keywords, we can quickly locate the corresponding paragraphs. In this way, these relevant paragraphs and user questions are sent to the large model for answers, effectively improving retrieval efficiency.
(2) Summary node group:
User asks: "How do I connect my printer to Wi-Fi?"
For this problem, if you search for the keyword Wi-Fi, in addition to connecting to Wi-Fi, there will also be other operation-related documents. At this time, the keyword search will lose a certain accuracy. By generating a summary of the entire document, we can extract the core information from the document and store it in a form of appropriate length for reading. For example, after a summary is generated in the printer connection settings-related content section, the summary information in the corresponding document section must include the printer's Wi-Fi connection information. After obtaining the original text corresponding to the summary, it is passed into the large model together with the user's questions to achieve context-based answers.
(3) Preset QA pair node group:
User asked: "My printer prompts that the paper is jammed, what should I do?"
Looking directly from the document may reveal that the steps for handling a "paper jam" are scattered across multiple paragraphs. At this time, by extracting question and answer pairs, all information related to "paper jam" can be extracted and stored in advance as a standardized question and answer pair, for example: Question: My printer prompts that the paper is jammed, what should I do? Answer: 1. Turn off the printer and unplug the power supply. 2. Open the paper tray and check for jammed paper. 3. Carefully remove the jammed paper and restart the printer. Then, the recalled questions (only recalled based on the questions during recall), answers and user questions are passed to the large model to complete user Q&A.
Original text vs vectorization
Original text and vectorization (also called embedding) are two commonly used text representation methods in natural language processing. The original text is the text itself, and vectorization is a representation method that maps text into high-dimensional vectors through an embedding model. The text under the two representations corresponds to different retrieval methods. Original text-based retrieval (Lexical Search) refers to symbol-based retrieval methods such as keyword matching, also known as original text matching; vector-based retrieval, also known as semantic search (Semantic Search), refers to a method that maps the original text to a high-dimensional vector space through statistical learning or neural networks, and then performs similarity calculations in the vector space.
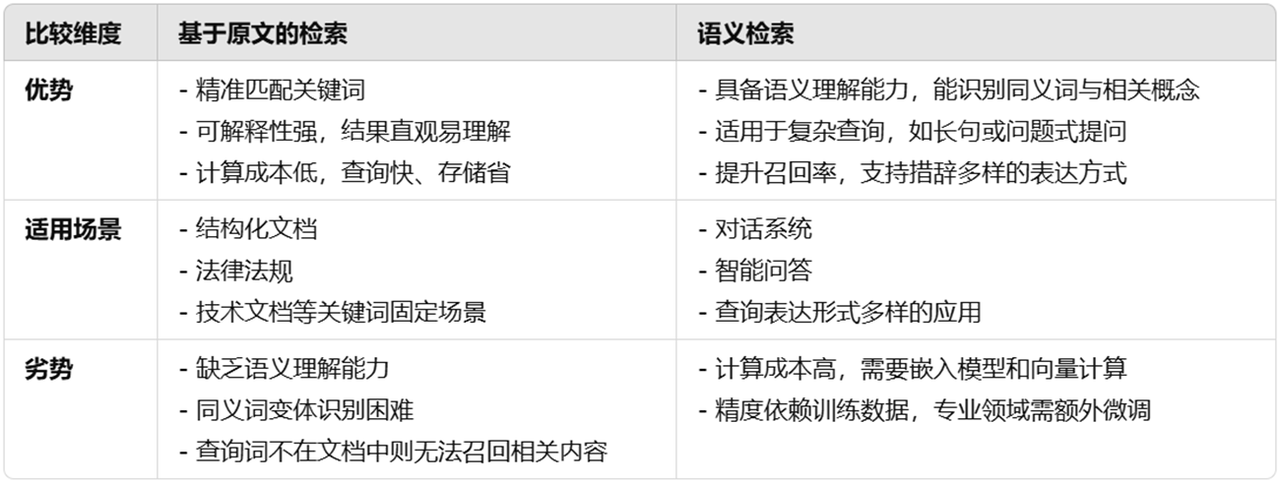
The advantages of retrieval based on original text are (1) it can accurately match keywords, and is suitable for scenarios where keywords are relatively fixed, such as structured documents, laws and regulations, and technical documents; (2) the results are highly interpretable, and the retrieved text is often highly consistent with the query terms, making it easy for users to understand; (3) it has advantages such as low computational cost, which is usually implemented based on inverted indexes, with fast query speed and relatively small storage overhead. However, its disadvantages are the lack of semantic understanding and low recall rate for long texts. Original text retrieval cannot identify synonyms, synonyms and other variations. As a result, relevant information may not be retrieved if the query is slightly different. Moreover, if the query term does not appear in the text, original text retrieval cannot recall relevant paragraphs.
The advantages of semantic retrieval are (1) Semantic understanding ability: it can identify synonyms and context-related concepts, and it can match relevant content even if the query term does not appear directly in the document; (2) It is suitable for complex queries: it can understand long sentences and question-based queries (such as "How to clean printer ink cartridges"), and is suitable for applications such as dialogue systems and intelligent question and answer. (3) Improve recall rate: Texts that are semantically similar but worded differently can be found, making the retrieval more comprehensive. However, its disadvantage is that the computational cost is high, it requires pre-training the vector model and performing vector calculations during query, which consumes a lot of resources. And the retrieval quality depends on the quality of the training data. In some professional fields (such as medicine, law), additional fine-tuning may be needed to improve accuracy.
In practical applications, we can combine original text-based retrieval methods and vector-based retrieval according to needs to optimize the final effect of the system. In terms of implementation, retrieval based on the original text is usually relatively simple. It only needs to store the text in blocks and match the original text during retrieval. Semantic retrieval requires the text to be vectorized before the system starts working. Only after completing this step can it start receiving user queries for subsequent retrieval. The following is a brief introduction to text embedding technology.
1. What kind of technology is text embedding
Text embedding technology first vectorized words, that is, mapping a word into a mathematical vector to facilitate computer calculations. Figure 8 gives a simple example: vector encoding for the four words "I love my family". First, create a word list. In this example, there are only three words, so the size of the word list is 3, which are "I", "love", and "home" in order; then mark the position where each word appears in order as 1, and the remaining positions as 0. In this In the word list, the word "I" corresponds to [1,0,0], the word "love" corresponds to [0,1,0], and the word "home" corresponds to [0,0,1]; therefore, the vectorized representation of the phrase "I love my family" is shown in the matrix on the right side of Figure 8. This is one hot embedding. One-hot encoding is a classic word vectorization algorithm that can differentiately represent all words in the vocabulary. However, as the vocabulary expands, the vector dimension will expand infinitely, and bottlenecks will be encountered in terms of storage and calculation.
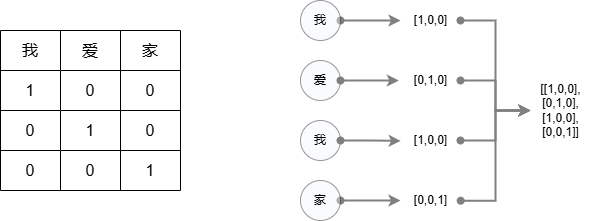
Figure 8: One-hot encoding example
Although word vectors can achieve the purpose of mapping text into vectors, if it is the amount of data of a book, what will be the final vector dimension? Therefore, we need a more efficient vectorization method, that is, sentence (or paragraph) vectorization technology. The early method of realizing sentence vectorization was to average the word vectors (for example, the sentence vector of "I love my family" in the above example is [1, 0.5, 0.5]). But this approach is often less effective because it ignores factors such as context and the importance of words.
In 2014, Google proposed the transformer structure. Networks based on the transformer structure have the advantages of strong representation capabilities and adaptability to long sequence data. Until now, transformer is still the mainstream basic network structure in fields such as machine learning and natural language processing. Currently, embedding models that can preserve contextual semantics are commonly used based on transformer networks. These models map the chunked document into a fixed-dimensional vector that retains the contextual information of the text to a certain extent. The distance or angle between vectors can reflect the semantic similarity between texts. Even if two sentences use different vocabulary, if they express similar meanings, they will be very close in the embedding space, which is difficult to achieve by original text matching. Currently commonly used text embedding models include the bge series and jina series. Users can find the corresponding model weights on platforms such as huggingface according to their needs, or call online models provided by mainstream large model manufacturers. Figure 9 shows an example of embedding the four words "I love my family" through a neural network. Compared with the one-hot encoding in Figure 8, the result has a higher dimension and more complex values, but the effect is often better in practical applications facing large-scale data.

Figure 9: Example of text embedding calculation based on neural network
2. How to search through Embedding
It is not difficult to imagine that the algorithm for retrieval using the original text is to perform keyword matching based on user queries and document fragments of the original text. How to use Embedding to perform vector retrieval? Let’s first look at the following figure:
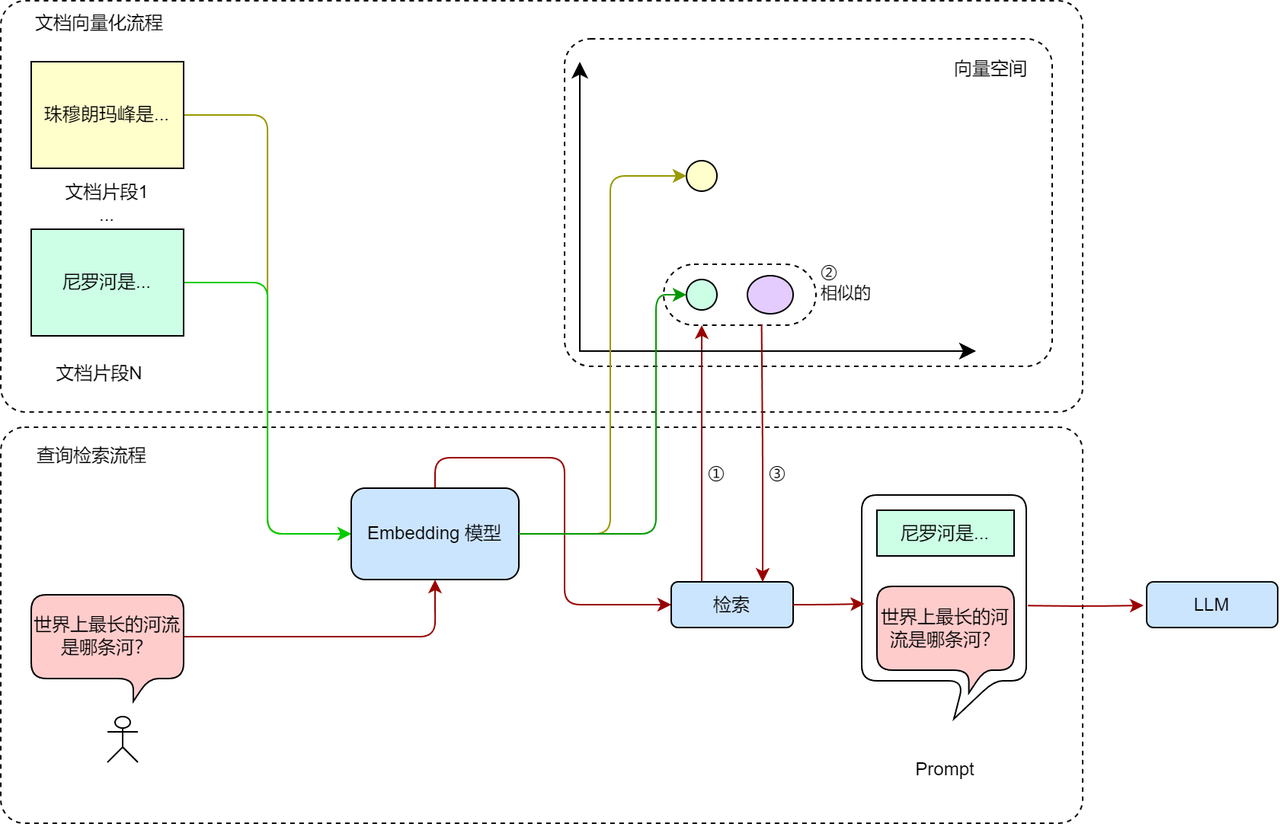
Figure 10: Example of RAG system workflow implemented using vectorization technology
Figure 10 shows the RAG based on semantic retrieval The retrieval component workflow mainly consists of two parts: the text vectorization process and the query retrieval process. The document vectorization part vectorizes the sliced documents to achieve mapping from sentences to vectors. This step is usually performed offline and has nothing to do with user queries; the query retrieval flow part The process is an online process. Each intermediate result in this step is related to the user query. Specifically, after the user query is embedded in the model, the similarity is calculated with all vectors in the document library, and then several document fragments most relevant to the query are returned and input to the large model together with the user query. The figure shows an example of the response of the RAG system when the user queries the longest river in the world. Assume that text fragment 1 is related information about Everest, and the corresponding vector is the yellow point in the right coordinate system, and document fragment N is related information about the Nile River, corresponding to the green point in the right coordinate system. When the user enters the query "Which is the longest river in the world?", the query is first mapped to the vector space where the document library is located (i.e. ① in the figure) through the same Embedding model as the document embedding; then the retriever looks for document vectors that are close to it in the vector space (i.e. ① in the figure) ②), in this example, the green dot representing the Nile-related information is the vector most relevant to the user query; then the retriever returns the original document text corresponding to the document vector, that is, the document fragment N containing the Nile-related information (i.e. ③ in the figure); finally, we input the document fragment (Nile-related information) and the user query (which is the longest river in the world?) to the large model to complete a round of retrieval and question-answering based on the embedded vector.
3. Large and small block strategy
In the RAG system, "small block recall, large block generation" is a common and efficient strategy, and its core idea is:

- Small block recall: Small block is used for high-precision recall. Documents are first divided into smaller granularities (such as paragraphs, sentences). Each small block carries more refined semantic information, which facilitates accurate calculation of similarity with user queries. In the retrieval phase, only small block vectors are compared for similarity, making it easier to find content that is semantically close to the user's query.
- Chunk recall: Chunk is used for context generation. Once a small chunk is successfully recalled, the system will find the chunk to which the small chunk belongs (such as an entire section of content or a complete subtopic) and provide it as context to the large model for generating more complete and coherent answers. The advantage of this is to avoid small pieces of information being too fragmented, making it difficult to understand large models; and at the same time, reducing the computing and storage costs of storing all large pieces into the database.
4. Dense vectors and sparse vectors
As mentioned above, the advantage of vectorized representation of text paragraphs compared to original text matching is that it can retain the semantics of the paragraphs. The specific performance is that similar paragraphs have higher similarity. There are two commonly used vector retrievals, one is dense vector retrieval and the other is sparse vector retrieval. The following is a brief introduction to the two methods and analyzes their respective advantages and disadvantages. You can choose the appropriate retrieval method according to your own needs.
(1) Dense Vector:
The characteristic of dense vectors is that the dimensions are much smaller than the vocabulary size. For example, the input of bge-embedding can reach 8196 tokens, but the output is a fixed 1024-dimensional. The values of most elements in dense vectors are non-zero, and are generally calculated through models such as Word2Vec, BERT, bge-m3, jina-embedding . There are two ways to obtain dense vectors. One is to directly perform mean pooling on word vectors (mostly used in bag-of-word models), and the other is to calculate the corresponding vector of [CLS] (as shown in Figure 11) through models such as BERT and use it as the embedding vector of the current sentence. It can be seen from the above calculation method that the dense vector of a sentence (or paragraph) is mainly an average of the semantics of the current paragraph. It can identify synonyms and context-related concepts, and can match related content even if the query term does not appear directly in the document. However, its disadvantages are that its ability to capture the details of the text is not strong enough and its calculation cost is high. For example, for the query "The discipline of artificial intelligence was founded in 1956.", the vector generated by bge-m3 is embedded into a 1024-dimensional vector:
The above-mentioned vectors have no directly readable meaning, poor interpretability, and dense vectorization model training is complex and usually requires reliance on a large amount of data. Document representation based on dense vectors usually may lose specific values, special terms, entity names or syntactic structures in the text after passing through the vectorization model. In practical applications, for example, in professional fields such as law or medicine, certain terms and expressions are crucial to correctly understanding the text, and dense vectors may not be able to fully retain these key information, making it difficult to accurately match semantic retrieval.
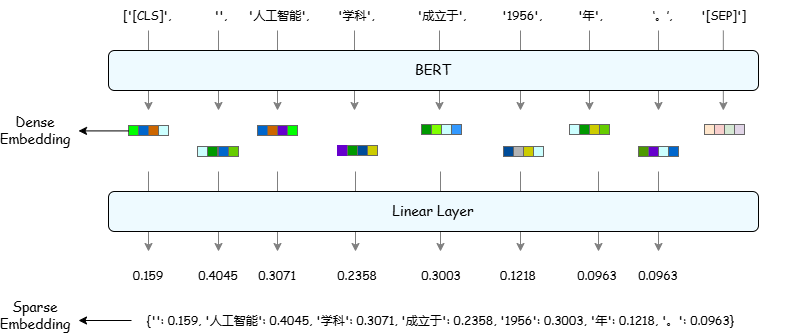
Figure 11: Comparison between using neural networks to generate dense vectors and sparse vectors
(2) Sparse Vector:
Sparse vectors are characterized by high dimensions, usually equal to the size of the vocabulary (Vocabulary). For example, the vocabulary size of bge-m3 is 250002, but most elements in the vector are 0, and non-zero values only appear on words that appear in the paragraph. There are two ways to obtain sparse vectors. One is to construct a fixed-size word list (such as 100,000 words) for each document, and then fill in the word frequency (TF) or TF-IDF weight at the corresponding word index position. Fill in the word positions that do not appear with 0 to obtain a sparse representation. The other is a method based on deep learning. Currently, commonly used methods include SPLADE, bge-m3, etc. This type of method combines BERT semantic modeling and the interpretability of sparse vectors, and represents queries and documents into sparse word vectors, thus taking into account the word matching capabilities of traditional algorithms and the semantic understanding capabilities of deep learning models. Compared with dense vectors, which focus on the average meaning of the passage, sparse vector representation calculates the weight of each word on the vocabulary list and can retain more details. The dimensionality of sparse vectors is very high, and most elements are 0, so the storage method based on array data structures is extremely cost-effective. Sparse vectors are usually stored in the form of (pos, value), where pos represents the vocabulary position and value represents the weight of the current word in this paragraph. Taking bge-m3 as an example, to calculate sparse vectors, first segment the sentence, obtain the word vector through BERT, and then calculate the weight of each word on the word list through a linear layer, instead of using the [CLS] bit embedding to summarize the entire sentence. Likewise for "The discipline of artificial intelligence was founded in 1956.", the sparse embedding output of bge-m3 is:
{'6': 0.159, '81492': 0.4045, '72584': 0.3071, '104220': 0.2358, '189638': 0.3003,
'470': 0.1218, '30': 0.0963}
'6' means that the value of the 7th position of the corresponding vector is 0.159, which means that in the current paragraph, the weight of the 7th word in the vocabulary is 0.159.
By comparing the dense representation and sparse representation of BGE-M3, we can find that the dense representation outputs a 1024-dimensional vector for any length of paragraph, while the sparse representation is related to the length of the paragraph and the words that appear. Each dimension of a dense vector contains information, and its values are usually small and evenly distributed, representing the overall position of the text in the high-dimensional semantic space. This representation is able to capture complex contextual information, making it more robust when calculating semantic similarity. However, since dense vectors are high-dimensional continuous values, their interpretability is poor, and it is difficult to directly understand the specific meaning of each dimension. In comparison, sparse vectors have fewer non-zero dimensions, usually directly correspond to specific vocabulary items, and have corresponding weights. The weights reflect the importance of the word in the paragraph. This representation makes sparse vectors easier to index and can be combined with traditional inverted indexes to improve retrieval efficiency.
In practical applications, dense vectors are suitable for semantic matching and cross-language retrieval because they can capture contextual information and implicit relationships in high-dimensional space, while sparse vectors are suitable for efficient keyword searches and tasks with strong interpretability requirements. Both have their own advantages and disadvantages. When used together, you can simultaneously utilize the semantic capabilities of dense representation and the efficient indexing capabilities of sparse representation to achieve more accurate search and matching.
Similarity calculation method
As mentioned above, the text embedding after vectorization will retain the semantics of the original text, that is, the similarity between semantically similar document embeddings will be higher. In order to accurately find document fragments that are similar to the user query, we need to choose an appropriate distance measurement function for similarity calculation. The simple similarity calculation process is to vectorize the user query, calculate the similarity between the vector and all vectors in the document library one by one, and select the specified top-k as the result, or further select the point whose similarity meets a certain threshold as the final result. Assuming that two-dimensional vectors are used as embedding dimensions, all blue points in Figure 12 represent vectors in the document library, and red points are query vectors. The vector of the red point and all other blue points are calculated, and the k closest points are selected as the results, or the two points that meet the distance threshold (i.e., red circles) are selected as the recall results.
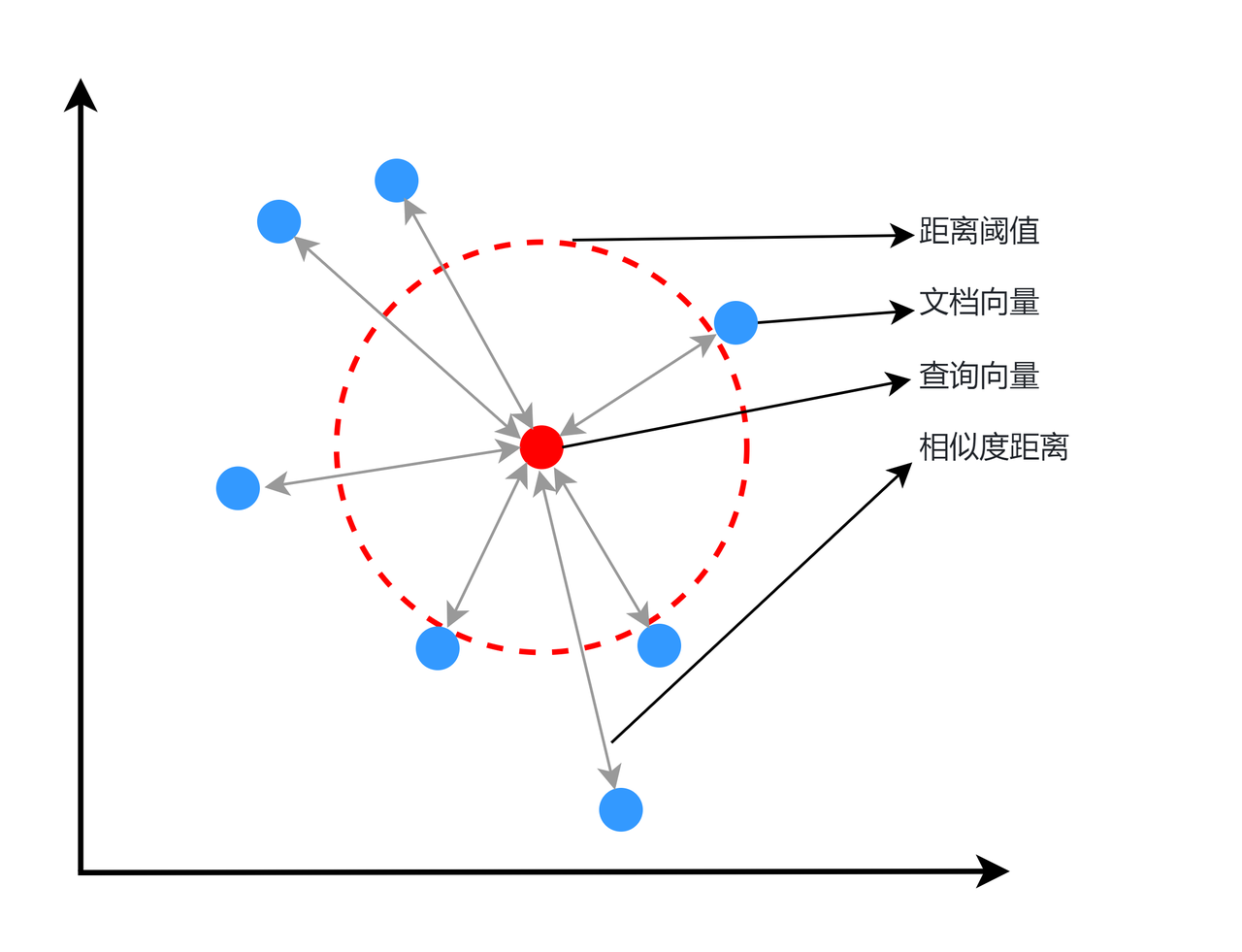 Figure 12: Vector similarity calculation
Figure 12: Vector similarity calculation
1. Inner Product
A vector is an ordered array of n rows and 1 column (n*1) or an ordered array of 1 row and n columns (1*n) consisting of n real numbers. The inner product of vectors is also called the dot product and quantity product of vectors. The dot multiplication operation is performed on two vectors, which is the operation of multiplying the corresponding bits of the two vectors one by one and then summing them. The result of the dot multiplication is a scalar. Let the vectors a and b be respectively
Then the inner product formula of a and b is:
The inner product reflects the degree to which two vectors "project" in the same direction. In a geometric sense, the larger the inner product, the closer the two vectors are in the same direction. When the inner product is 0, the two vectors are orthogonal, that is, they are linearly independent. We usually use the inner product as a distance metric in sparse vectors. Let's look at an example, assuming there are 3 TF-IDF vectors:
A=(0, 0.3, 0, 0.7, 0, 0.5)
B=(0, 0.4, 0, 0.6, 0, 0.2)
C=(0, 0, 0.8, 0, 0.6, 0 )
Stored in sparse representation:
A = {1: 0.3, 3: 0.7, 5: 0.5}
B = {1: 0.4, 3: 0.6, 5: 0.2}
C = {2: 0.8, 4: 0.6}
Calculate the inner product:
IP(A, B) = (0.3×0.4)+(0.7×0.6)+(0.5×0.2)
=0.12+0.42+0.10
=0.64
IP(A, C) = (0.3×0)+(0×0.8)+(0.7×0)+(0×0.6)+(0.5×0)
= 0
It can be obtained that the similarity between vectors A and B is 0.64, and the similarity between vectors A and C is 0.
2. Cosine Similarity
Cosine similarity is a standardized inner product measure, which measures the similarity of two vectors in direction, regardless of their length (i.e., module). For example, although x, y ** and x, z ** in the figure have different lengths, their cosine similarities are equal.
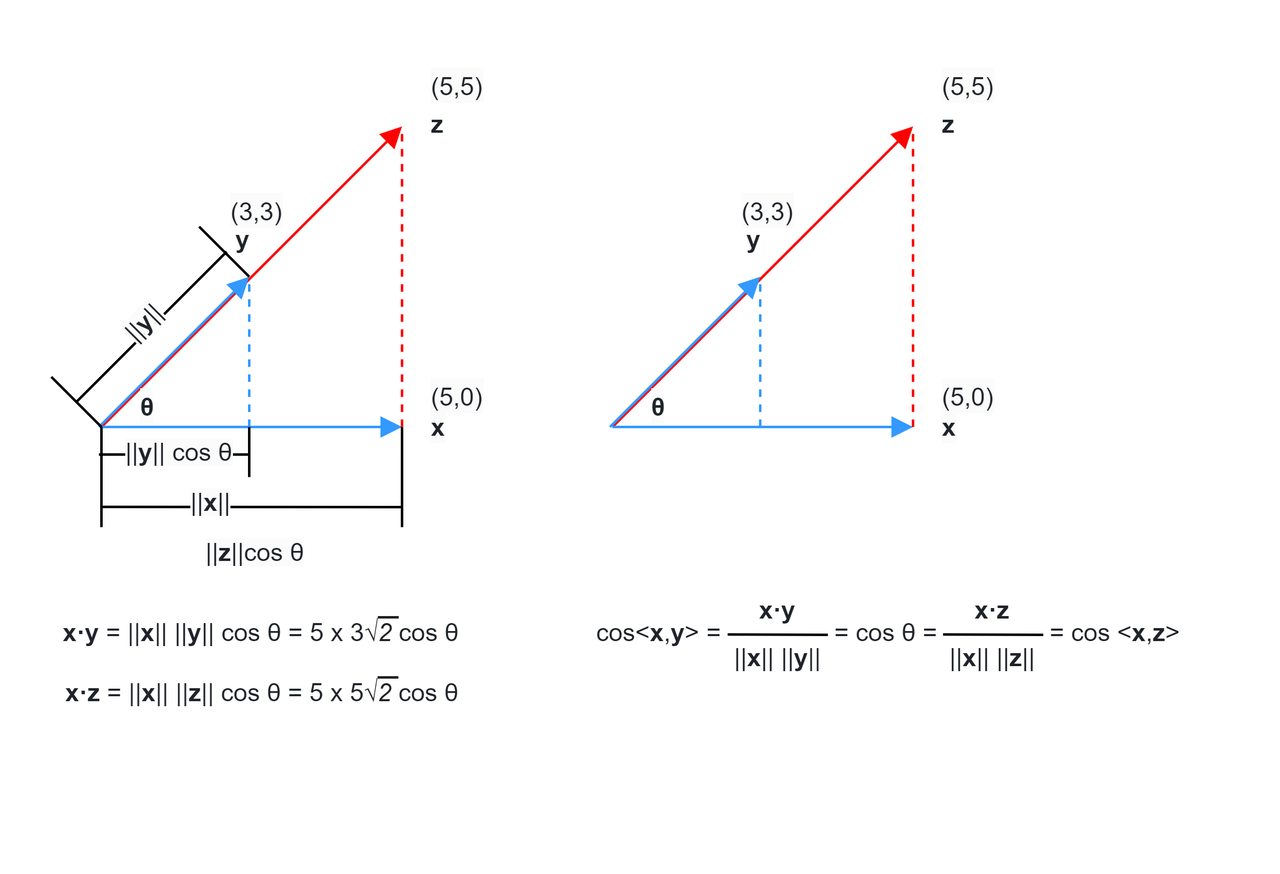
Figure 13: Comparison between inner product and cosine similarity, where the left side is the inner product and the right side is the cosine similarity.
Cosine similarity is calculated as follows:
Among them, ||x|| and ||y|| are the modules (i.e. length) of the vectors x and y respectively. The value range of cosine similarity is [-1,1], where 1 means exactly the same direction (i.e. y, z in the figure), 0 means orthogonal (i.e. no similarity), and -1 means completely opposite directions. Cosine similarity is often best practice in NLP tasks, where 1 means exactly the same direction, 0 means orthogonal (i.e. no similarity), and -1 means exactly the opposite direction. In the distance calculation of dense vectors, we usually use cosine similarity as the distance metric.
3. bm25
bm25 (best matching 25) is a ranking method based on a probabilistic model that is optimized for the frequency of keywords in documents. The core idea of BM25 is to model the relevance of documents based on Term Frequency (TF) and document length, and at the same time introduce a "penalty" mechanism for common words in documents, which is a method widely used in traditional search engines. Different from cosine and IP similarity, bm25 does not calculate similarity through embedding, but uses the following principles to measure the relevance of a document for a certain query:
(1) Term frequency (TF): the number of times a certain word appears in the document. Intuitively speaking, the more a word appears in a document, the more relevant the document is to that word.
(2) Inverse document frequency (IDF): measures the scarcity of a word in the entire document collection. Frequently occurring words may be less important in differentiating documents, so their weight should be reduced; while rare words may be more important in differentiating documents. It is defined as:
where N is the total number of documents, and df(qi) is the number of documents containing the query term qi.
(3) Normalization of document length: The word frequency distribution of short documents and long documents is different. BM25 reduces the impact of document length on relevance by normalizing the document length.
Knowing the above basic idea, let’s record the document as D, the query as Q, f(qi, D) as the word frequency of query word qi in document D, and the calculation formula of bm25 is defined as follows:
Where |D| is the length of document D, avgdl is the average length of all documents, k1 and b are adjustment parameters, usually k1 is between [1.2, 2.0], and b is set to 0.75. Among them, k1 controls the influence of word frequency. Larger k1 values increase the impact of word frequency on correlation calculations, while smaller values suppress the impact of high-frequency words and prevent over-reliance on certain common words. b controls the normalization of document length. The value range of b is [0, 1]. When b=1, the document length has the greatest impact on the score; when b=0, the length effect is not considered.
The above three similarity calculation methods are not absolutely good or bad. Generally, users can choose one or more methods to apply to different searchers according to their own needs. Generally speaking, different similarity calculation methods are used for different document representation methods. The following table shows the commonly used combinations of sparse retrieval and dense retrieval based on different vector representation methods.
| Traditional method (TF-IDF) | BERT-based method (BGE-M3) | |
|---|---|---|
| sparse search | bm25 | IP |
| dense search | cosine | cosine |
Reorder
The recall and reranking strategy is also called a two-stage retrieval, in which the first stage is retrieval and the second stage is reranking. It is widely used in tasks such as search engines, recommendation systems, and question and answer systems. The basic idea is: after a set of documents is obtained through preliminary retrieval, the retrieval results are re-ranked through an additional model to improve the final effect.
It is known that the retrieval stage has already output the similarity score, and the result is a result with a higher similarity score. Why do we need to reorder? First, the retriever performs similarity calculation based on the vector output by the embedding model. At this time, the approximate information loss due to information compression will directly affect the accuracy of the retrieval results. Secondly, traditional methods such as BM25 based on simple features such as word frequency have limited ability to capture deep semantics and context, which will also affect retrieval accuracy. The re-ranking model is often a larger model than the embedding model. Through a complete Transformer inference step, a similarity score is generated for the query and document, which has higher accuracy than calculating cosine and other similarities.
Why not retrieve directly through the ranking model instead of using the embedding model and retriever and then use the ranking model? This is because the reordering model requires inputting queries and documents at the same time, which means that each query requires score calculation on the entire amount of documents, which consumes a lot of resources and causes the system response speed to become very slow, which is not conducive to user experience. The retriever can retrieve a small number of documents from a large data set much faster than using a reordering model. The two-stage retrieval algorithm usually recalls more documents in the retrieval stage, and selects a small number of documents with high scores as the final retrieval results during reordering, forming a funnel-shaped structure to gradually reduce the number of recalled documents.
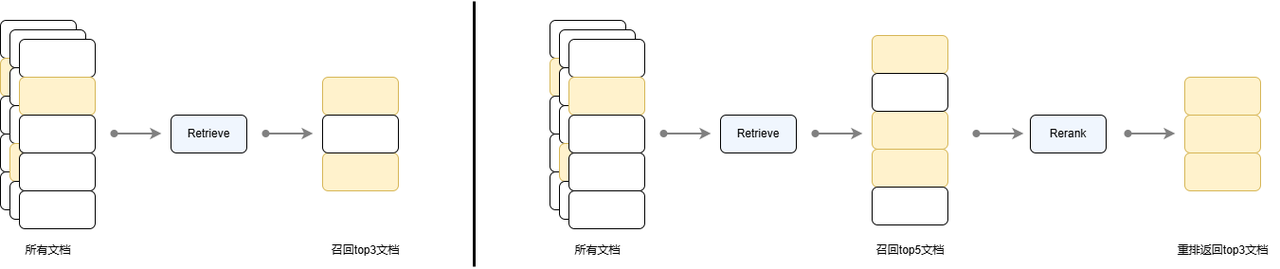
Figure 14: Comparison of single-stage recall and two-stage recall strategies. The highlighted parts in the figure represent relevant documents.
As can be seen from Figure 14, in the two-stage retrieval, Retriever (recall model) and Reranker (reranking model) each perform their own duties and have different functions: Retriever is mainly responsible for efficient screening and quickly extracting candidate documents related to the query from massive documents. Common methods include semantic retrieval and sparse vector retrieval such as BM25. However, since text embedding will cause a certain amount of information loss, and BM25 cannot capture semantic information, it will affect accuracy to a certain extent. In order to overcome this problem, Reranker is introduced to more accurately filter the initially recalled documents, perform a more fine-grained semantic analysis on the recalled document collection, and recalculate the similarity score. Transformer-based ranking models (such as bge-reranker-large, bge-reranker-base) are commonly used to perform the re-ranking step and generate a similarity score for queries and documents, which can capture more complex semantic information and improve the final retrieval effect, but the computational cost is high. In the recall and rearrangement strategy, Retriever is responsible for efficient recall, and Reranker is responsible for precise sorting. The two are combined to form a funnel structure of "wide casting + precise screening" to balance efficiency and effect.
Multi-Retriever RAG
In a RAG system, the quality of the recall phase directly determines the accuracy and relevance of the final generated answer. The traditional single retrieval strategy may miss some key information, while multi-channel recall RAG can improve the retrieval recall rate by integrating multiple retrieval methods, thereby optimizing the final generation effect. The introduction of the reordering strategy can not only filter and sort the recalled documents more precisely, but also realize multi-way recall, that is, joint retrieval based on multiple retrievers and different retrieval strategies. This method can extract relevant information from documents at different levels and different granularities, thereby improving retrieval coverage and improving the overall performance of the RAG system.
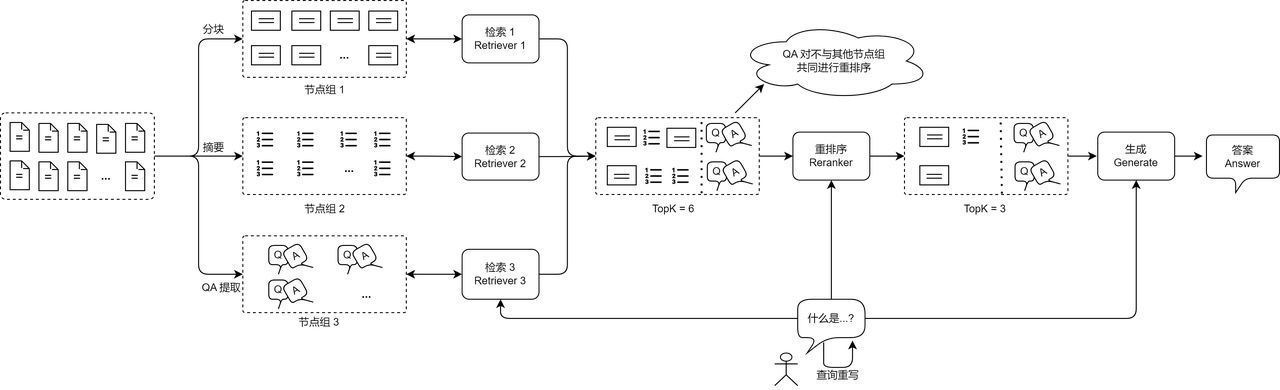
Figure 15: Multiple recall RAG
In practical applications, we can configure multiple different types of retrievers, each retriever is responsible for processing different data sources or different granularity of information, and then sort all retrieved and recalled documents to obtain the final context. For example, we can divide the original query into multiple subqueries through query splitting, search for different data sets respectively, and then integrate and sort all the search results to obtain the final contextual information. Multi-channel recall can be optimized from the following key steps:
(1) Rewrite user queries: For user queries, perform synonym replacement, supplement historical content, or generate multiple subqueries so that the searcher can search for content in different dimensions. Taking subqueries as an example, for complex queries, direct retrieval may not cover all relevant information, so splitting the query into multiple subqueries so that different retrievers can search for different dimensions can effectively improve the comprehensiveness of the context. For example, when a user queries: "What are the main challenges of AI-generated content in 2023?" Possible subqueries include "What are the technical limitations of AI-generated content in 2023?", "What are the regulatory and ethical challenges of AI-generated content in 2023?", "What are the difficulties in commercial application of AI-generated content in 2023?", then each subquery is input into a different retriever to recall the corresponding context segment respectively.
(2) Retrieval of multiple node groups: Using multiple retrievers to retrieve different data sources or different node groups in parallel can help improve the system recall rate. In the traditional RAG structure, a single retriever is usually used to obtain information from one data source, while using multiple retrievers to query different data sources or different knowledge granularities can effectively recall relevant documents. For example, the system in Figure 15 sets up three retrievers to retrieve original document blocks, document summaries, and predefined question and answer pairs respectively. This approach allows RAG to query information at different granularities and search for document fragments that are strongly relevant to user queries in multiple dimensions.
(3) Use multiple retrieval strategies: Using different similarity functions or multiple vector embedding methods can maximize the advantages of existing retrieval technologies. It is usually divided into dense retrieval and sparse retrieval. Among them, dense vector retrieval, that is, calculating semantic similarity based on dense vector embedding (usually using models such as bge to generate dense vector representations, and then using cosine to measure the similarity of text segments), is suitable for finding content with similar semantics but different wording; while sparse retrieval is based on word matching (such as BM25, splade, etc.) and is suitable for accurate keyword matching scenarios. A mixture of the two can achieve better recall results. For example, in a question and answer system in a certain legal field, intensive retrieval can find cases with different text expressions, while sparse retrieval can accurately match a certain legal article or a specific case.
(4) Result fusion: Since multiple retrievers may return different types of information, they need to be fused into a new document set for subsequent sorting and generation. For example, in the scenario where the user queries "the latest progress in AI regulation", retriever 1 returns a fragment of an academic paper on AI ethics, retriever 2 returns a government announcement containing the keyword "AI regulations", and retriever 3 returns a blog summary related to AI regulation. At this time, the system merges all documents to remove duplications and constructs a new document set.
(5) Reordering: Although the similarity score has been calculated in the retrieval stage, the importance of documents returned by different strategies may be different and further reordering is required. Traditional retrieval scores may result in higher scores for irrelevant documents due to word frequency issues, while intensive retrieval may result in the loss of key details due to information compression and the output of rough ranking results. At this time, the role of the reranking model is to use a more powerful Transformer model (such as bge-reranker-large) to recalculate the similarity of the retrieved documents to improve accuracy. For example, in the above example of AI regulatory progress, the reordered order is: the latest report on AI regulatory policy (most relevant), an academic article on AI ethics discussion (relevant), and a blog about the development of AI technology (less relevant). After reordering, the system only retains the documents with the highest scores and proceeds to the next step. It is worth noting here that the results of the QA recall will not participate in the reordering process with other node groups.
(6) Final answer generation: After reordering, the system will select the top K high-scoring documents and input them into the large model together with the user query to generate the final answer. Taking the example of AI supervision mentioned above as an example, the large model accepts the user Query: "Latest progress in AI supervision", and can refer to the following documents: the latest report on AI supervision policy, an academic article on AI ethics discussion, and a blog about the development of AI technology. As input, it summarizes the latest progress in AI supervision based on these three documents and performs summary recovery.
Compared with traditional single-channel retrieval RAG, multi-channel recall RAG uses multiple retrieval strategies, so the system can cover a wider range of information and reduce the possibility of missing key knowledge. Secondly, through multi-granularity retrieval (fine-grained text, abstract, QA peer-to-peer, etc.), different levels of information can be captured, which can improve the comprehensiveness and accuracy of answers. Traditional RAG may have certain limitations in specific fields, while multi-channel recall can combine information from multiple sources to improve the model's adaptability on different tasks. Therefore, users can obtain more complete and logical answers to complex questions instead of relying solely on a single search method.
Actually try various strategies individually on the evaluation set to find the strategy with complementary advantages:

Summarize
This tutorial mainly discusses several methods to improve the recall rate of the RAG retrieval component. First, the evaluation indicators of the RAG system are introduced, including the evaluation indicators recall and Context Relevance of the retrieval component and the evaluation indicators faithfulness and Answer Relevance of the generation component. Then a series of solutions are proposed to improve the index of the RAG retrieval component. From the upstream to the downstream order of the RAG retrieval component, methods for rewriting user queries are first introduced, including common methods such as expansion, synonym replacement, historical information insertion, and sub-question query. Then, for different links in the retrieval strategy, node groups, document representation methods, and multiple similarity calculation methods are introduced. In the node group section, the node group construction method based on blocking and the node group construction method based on semantic extraction are introduced. Developers can choose specific solutions for node group construction for different tasks. In the text representation method section, it introduces original text-based representation and vectorized representation, introduces the traditional bag-of-words model, sentence vectorization and sparse vectors, and introduces the process of document retrieval based on vectorized representation. The principle of retrieval based on similarity function and the three similarity functions of inner product, cosine similarity and bm25 are introduced. A two-stage retrieval method based on the recall rearrangement strategy was introduced, which finally led to the multi-way recall RAG. Although multi-channel retrieval RAG can improve the effectiveness of the RAG system by improving the recall rate of the retrieval component, its computing and storage overhead are relatively high, so issues such as reducing redundant calculations and retrieval scheduling need to be considered during design. In the next lesson, we will take everyone to learn how to improve the performance of the RAG system.
References
RAGAS:https://arxiv.org/pdf/2309.15217
bge-m3: https://arxiv.org/pdf/2402.03216