Chapter 17: a full-link solution for permissions, sharing and content security
In the previous tutorial, we mainly discussed the implementation and optimization techniques of personal-level RAG (Retrieval Augmentation Generation) applications. However, in enterprise-level applications, the requirements for knowledge management and intelligent retrieval are more complex, involving multiple departments, each with independent business fields, data storage methods, and algorithm requirements. Therefore, efficiently managing and retrieving knowledge, ensuring flexible access to knowledge bases by different departments, while meeting data isolation, security and sharing mechanisms are the core challenges of enterprise-level knowledge management systems. This chapter will introduce how to use LazyLLM to quickly build enterprise-level database management and retrieval and recall services to meet the above complex requirements.
1. Diversified needs of enterprise-level knowledge bases
In actual enterprise applications, knowledge bases are no longer a simple stack of information, but need to face complex demands from multiple dimensions such as permissions, sharing methods, and security guarantees. Below we start from typical scenarios to systematically elaborate on these diverse needs and their response strategies.
✅ Scenario 1: Knowledge access isolated by department (diversity of permission management)
Customer background: large manufacturing enterprise
The enterprise has multiple functional departments (such as R&D, procurement, and sales), each of which is responsible for information collection and management in different fields. The document content covers supply chain cooperation, cost accounting, product planning, etc. The information is highly sensitive and internal access must be strictly isolated.
- Department-specific knowledge base: Each business unit can independently maintain professional content such as product documents, market analysis, financial reports, etc., and the system automatically isolates unauthorized access.
- Smart label system: Supports professional label systems such as "R&D - Technical White Paper" and "Market - Competitive Product Analysis" to achieve accurate retrieval and controlled sharing.
- Management Cockpit: Senior management can obtain cross-department knowledge summaries through the "Strategic View" tab to ensure decision support while maintaining data security.
✅ Scenario 2: Collaboration needs of multiple sharing methods (diversity of sharing methods)
Customer background: Consulting service company
The company often conducts joint projects with different customers, involving document sharing, stage reports, project materials and algorithm resources, etc. Customers use diverse tools and preferences and require flexible sharing mechanisms to balance business cooperation and document confidentiality.
- Algorithm resource sharing: Supports the sharing and reuse of core components such as llm models, embedding models, and retrieval algorithms within the enterprise.
- Knowledge reuse for differentiated calls: A project knowledge base can serve internal consultants, customer technical teams and third-party analysis agencies at the same time. Different recall rules can be configured to achieve recall decoupling and satisfy multiple roles for accurate access.
✅ Scenario 3: Multiple security strategies to ensure content security (security assurance diversity)
Customer background: Fintech company
The knowledge base contains a large amount of sensitive content, such as user financial behavior analysis, regulatory compliance plans, audit materials, etc., which places extremely high requirements on information security.
Security Requirements:
- Intelligent filtering of sensitive words: Built-in multi-level sensitive word identification strategy, dynamic judgment based on context, automatic prompts, replacement or blocking of output during the question and answer and retrieval process, preventing the leakage of information such as internal blacklists, customer confidentiality, confidential terms, etc.
- Full-link knowledge encryption: Symmetric or asymmetric encryption mechanisms can be enabled in the uploading, parsing, warehousing, transmission and generation stages of knowledge documents to ensure that knowledge is not stolen or tampered throughout the entire life cycle.
- Privatized deployment solution: The platform can be fully deployed on a private server within the enterprise network or a dedicated cloud environment, including knowledge base, vector engine, retrieval module and model inference service, ensuring that knowledge data is not transmitted through the public network. The system can seamlessly integrate enterprise authentication, permissions and log systems to form a closed-loop security protection structure.
Enterprise-level application scenarios put forward more dimensional requirements for knowledge bases. LazyLLM provides solutions for these needs in three aspects: permission management, sharing mode and security assurance.
2. Permission diversity and solutions
1. Permission isolation: Support independent knowledge operations of multiple departments
In large enterprises, each department usually has an independent document system, and these documents may contain sensitive business information, internal operation manuals or key process documents. In order to ensure information security and usage compliance, enterprises have put forward higher requirements for document management capabilities and isolation mechanisms. Common management challenges include:
- How to support high-frequency updates and maintenance of knowledge base?
- If the same document is used by multiple departments, does it need to be stored in the database multiple times? Leading to data redundancy and management difficulties?
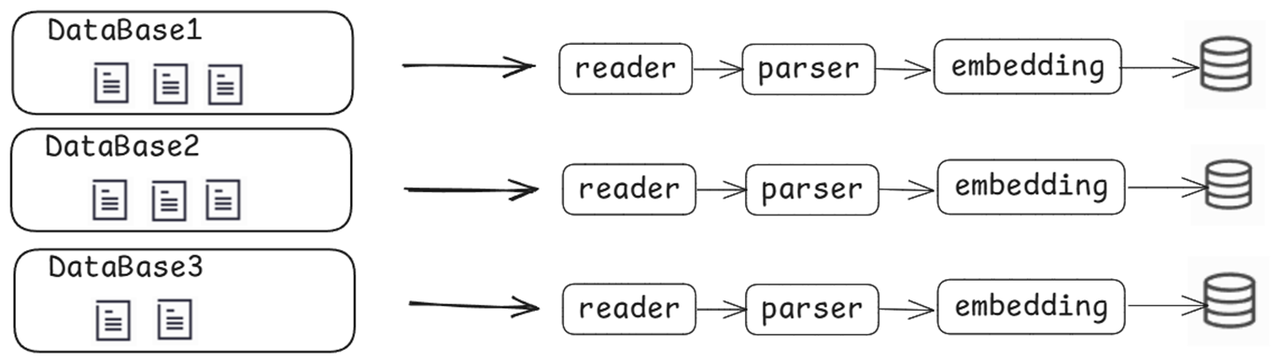
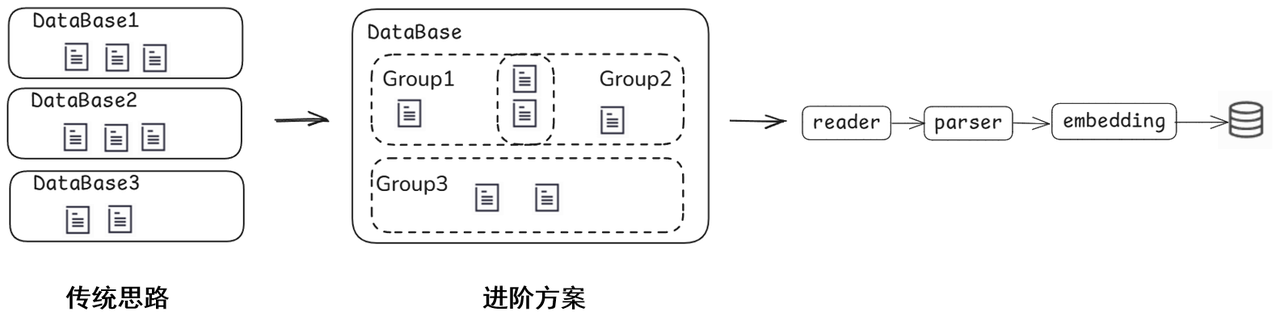
To this end, lazyllm has a built-in flexible document management service and provides a complete set of functions for adding, deleting, modifying, and checking documents. Users can easily add new documents, modify existing content, delete expired documents, and perform searches when needed to ensure that the knowledge base is always up to date. Different knowledge bases are isolated from each other, which can help enterprises flexibly divide knowledge base access boundaries according to departments, positions, projects and other dimensions, and realize a controllable strategy of "who can see, what can be seen, and how much can be seen."
For example, within the same knowledge base storage, the document management group function is supported for group management, and the same document only needs to be parsed once.
Document Management Services
Enabling the document management service is very simple. You only need to set the manager parameter to ui when creating the document object to enable the document management function. For example (code GitHub link):
from lazyllm.tools import Document
import time
path = "path/to/docs"
docs = Document(path, manager='ui')
# Register group
Document(path, name='Legal Document Management Group', manager=docs.manager)
Document(path, name='Product Document Management Group', manager=docs.manager)
# Start service
docs.start()
time.sleep(3600)
The page after startup is as follows:

After the document management service is turned on, you can easily view documents in different groups on the web page, and support quick addition and deletion of documents.
Document management backend API service
The web service has a default front-end interface based on Gradio built-in. If an enterprise needs to customize a more professional front-end interface, it can only start the back-end API service through the manager=True parameter, and then freely develop a personalized front-end based on the interface.
from lazyllm.tools import Document
import time
path = "path/to/docs"
docs = Document(path, manager=True)
# Register group
Document(path, name='Legal Document Management Group', manager=docs.manager)
Document(path, name='Product Document Management Group', manager=docs.manager)
# Start service
docs.start()
time.sleep(3600)
After startup, the Redoc page is as follows, showing the available backend interfaces.
2. Permission diversity: supports more fine-grained access control
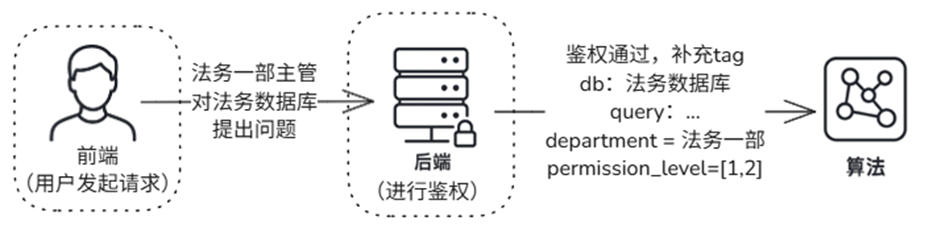
In the actual operation of an enterprise, permission requirements are far more than simply "which department accesses which document". Members of different groups, positions, and even projects often need to share some knowledge while protecting sensitive content from being misread or leaked. In order to meet this complex and changing demand, LazyLLM provides permission control capabilities based on tag retrieval. Enterprises can label documents with multiple labels such as department, position, time, file type, etc., and configure corresponding access rights for different roles to achieve refined management. For example, the marketing department may want to retrieve documents related to "product promotion", while the R&D department may be more interested in documents in the "technical specifications" category. In addition to tag-based filtering requirements, users also want to be able to specify a specific set of documents to query during retrieval, rather than searching the entire knowledge base. For example, a legal department may only want to retrieve contract documents from the most recent year, rather than all historical contracts. Therefore, the system needs to support precise queries for part of the document collection in the knowledge base to improve the accuracy and efficiency of search.
Enterprises need to finely control document access through standardized authentication mechanisms (such as role-based RBAC, attribute-based ABAC, and policy-based PBAC).
❓ How to organize content and set access rights based on standardized authentication mechanisms to ensure compliant use of information?
❓ How to refine access control based on permission levels, such as if different personnel within the same department have different levels of access permissions?
LazyLLM Solution ————Tag-based permission control mechanism:
✅ Each document can be bound to predefined tags (such as department, project, security level) when uploading
✅ Support tag-based filtering during retrieval, and only return content that meets the conditions
🔍 Example: Simulating Role-Based Access Control (RBAC)
Goal: Allow employees of the "Legal Affairs Department" to search only documents of their own department
- Define label field: department
- Specify when uploading documents: department = Legal Affairs Department
- Automatically inject filter conditions during retrieval: filter={"department": "Legal Affairs Department"}
Through this mechanism, role-based isolated access is achieved, which not only ensures data security, but also simplifies the implementation of permission policies.
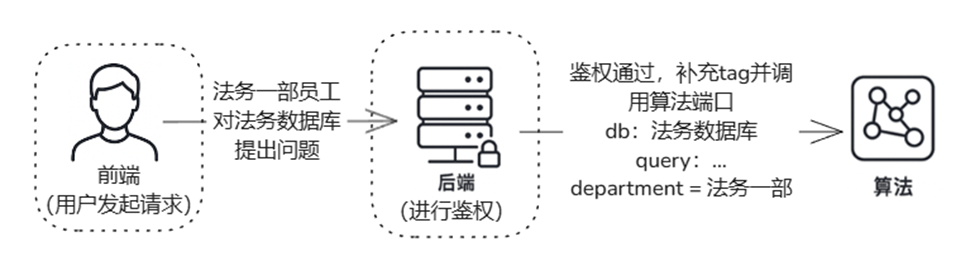
In practical applications, the authentication logic should be managed uniformly by the backend, and the algorithm side should not directly handle authentication. This ensures the centralization and security of permission control and avoids security vulnerabilities caused by bypassing permissions on the algorithm side.
Tag-based access control
We can achieve flexible classification and query functions through metadata management and retrieval filter (filter), which only requires the following two steps:
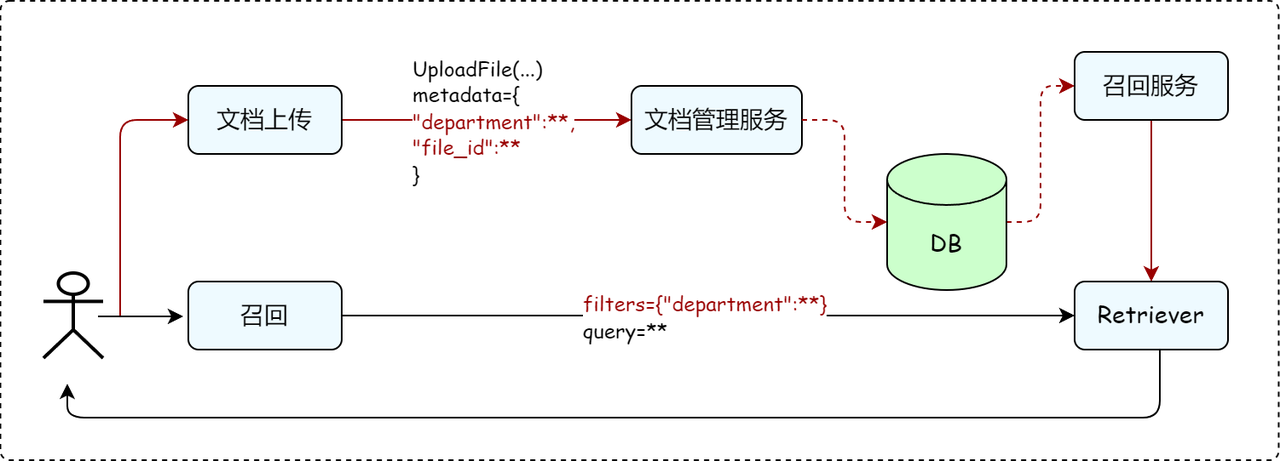
Step one: Metadata addition
To use metadata filtering, you need to specify the milvus database and declare the fields to be specified. Take the department as an example. The example is as follows:
CUSTOM_DOC_FIELDS = {"department": DocField(data_type=DataType.VARCHAR, max_size=65535, default_value=' ')}
milvus_store_conf = {
'type': 'milvus',
'kwargs': {
'uri': os.path.join(db_path, "milvus.db"),
'index_kwargs': [
{
'embed_key': 'bge_m3_dense',
'index_type': 'IVF_FLAT',
'metric_type': 'COSINE',
},
{
'embed_key': 'bge_m3_sparse',
'index_type': 'SPARSE_INVERTED_INDEX',
'metric_type': 'IP',
}
]
},
}
law_knowledge_base = Document(
data_path,
name='Legal knowledge base',
manager="ui",
doc_fields=CUSTOM_DOC_FIELDS, #Specify the fields to filter
store_conf=milvus_store_conf, # Open milvus database
embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
When uploading files through the document management service, users can specify the metadata classification information that needs to be set for the file. For example:
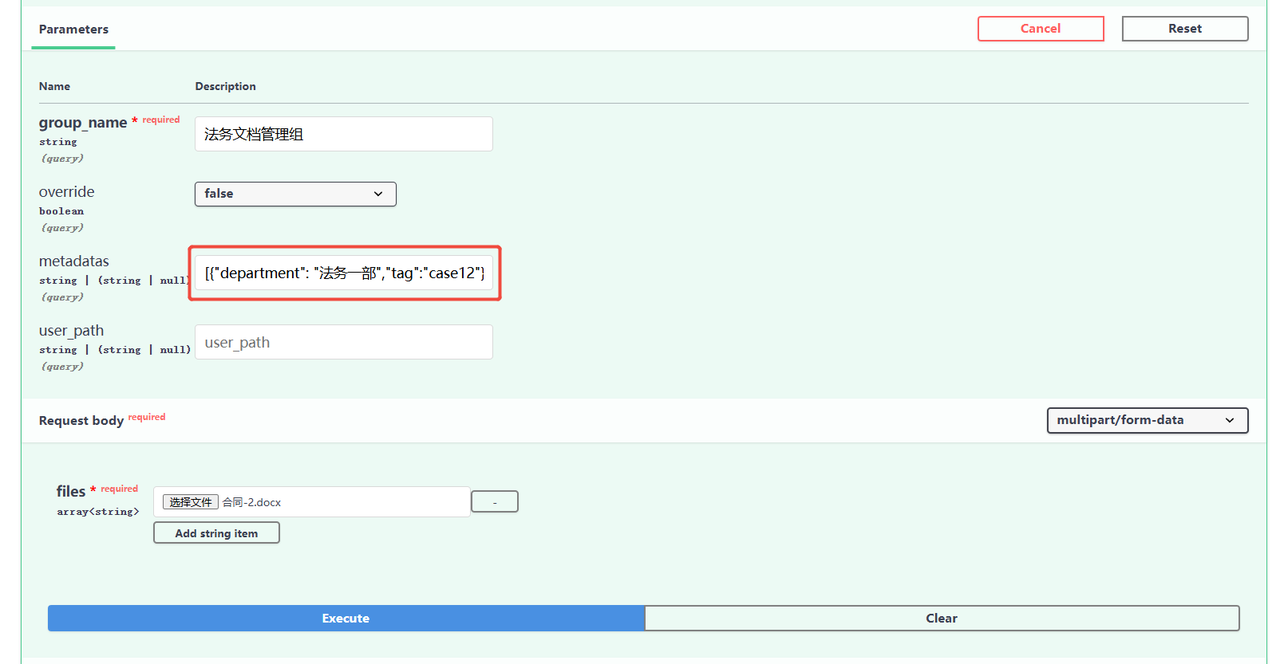
Step 2: Metadata Query
When querying, users can specify the classification information to be filtered through the filter mechanism. You can filter in the following way to retrieve only documents from Legal Affairs 1 and Legal Affairs 2.
retriever_support = Retriever(
[law_knowledge_base, support_knowledge_base],
group_name=...,
similarity=...,
topk=2
)
support_question = "How to handle customer complaints about contracts"
support_res_nodes = retriever_support(
support_question,
filters={'department':['Legal Affairs Department']} # Specify the defined filter conditions
)
By adding Metadata and defining the filter mechanism, multi-permission management of documents is finally achieved.
The following example shows both retrieval methods:
- Use filter (retrieve only "Legal Affairs 1" documents)
- Without filter (retrieve all documents)
This comparison is only for function demonstration purposes in order to understand the filtering mechanism of the system.
In practical applications, the system can implement mandatory binding of filter conditions to ensure that users can only retrieve documents from the departments to which they belong, thereby achieving unification of document isolation and permission control.
📌Advanced: Refined permission level control
- Level 1: Ordinary employees can only view basic financial statements.
- Level 2: Supervisor, able to view department budgets and project expenditures.
- Level 3: Manager and above, with access to financial decisions and sensitive reports.
- Register permission level - permission_level field:
CUSTOM_DOC_FIELDS = {"department": DocField(data_type=DataType.VARCHAR, max_size=32, default_value=''),
"permission_level": DocField(data_type=DataType.INT32, default_value=1)}
- Upload the document and mark the permission level (such as permission_level = 1)
files = [('files', ('Ordinary document.pdf', io.BytesIO(...)),
('files', ('sensitive document.pdf', io.BytesIO(...))]
metadatas=[{"department": "Legal Affairs Department", "permisssion_level": 1},
{"department": "Legal Affairs Department", "permisssion_level": 2}]))
- Specify the permission level when retrieving
nodes = retriever(query, filters={'department': ['Legal Affairs Department'], "permission_level": [1,2]} )
3. Diversity of sharing methods and solutions
In addition to permission control, enterprises also face diverse needs in knowledge sharing: on the one hand, different teams often need to share algorithm resources to improve reuse efficiency; on the other hand, there is also a need for cross-use of knowledge bases between multiple departments to support many-to-many knowledge reuse relationships. These scenarios put forward higher requirements for flexible sharing mechanisms.
1. Sharing flexibility: supports free adaptation of multi-source knowledge and algorithms
In an enterprise, multiple departments may share the same algorithms for data processing, reasoning, and decision-making. However, due to their different business areas, each department usually has an independent knowledge base to store exclusive information in their respective fields. Therefore, the system needs to support the same algorithm can be applied to multiple different knowledge bases to ensure the applicability of the algorithm in different departments.
- 📈 For example, in a financial company, the risk control department and the market analysis department may both use the same text parsing and embedding algorithms to preprocess data, but the risk control department's knowledge base mainly contains historical transactions and customer credit records, while the market analysis department's knowledge base contains market dynamics and competitor intelligence. The system needs to support the reuse of the same data processing algorithms in different knowledge bases.
On the other hand, in some enterprise scenarios, different departments may use their own customized algorithms for data analysis and decision-making, but some departments may need to share the same knowledge base in order to perform differentiated calculations based on unified information sources. The system needs to support different algorithms can be applied to the same knowledge base** to meet this business need.
- ☕ For example, in an e-commerce company, the recommendation system department may use an embedding algorithm based on collaborative filtering to model user behavior, while the search optimization department may use a similarity ranking algorithm based on word vectors to improve the relevance of search results. Both departments may be based on the same user behavior data set, and the system needs to support independent running of different embedding and ranking algorithms in the same knowledge base to generate targeted optimized results.
Next, we will introduce how to use lazyllm to realize the sharing and flexible configuration of algorithm modules in the RAG process.
LazyLLM supports a flexible algorithm plug-in mechanism, providing a basic guarantee for building a pluggable intelligent system. We can pre-define a global algorithm register to uniformly manage commonly used parsers, embedding models and similarity calculation methods, thereby achieving flexible combination and reuse of algorithms when building knowledge bases and retrievers (Retriever).
Note: The following code demo only shows the framework, and the actual algorithm needs to be implemented according to requirements.
class AlgorithmRegistry:
"""Global algorithm register, realizing decoupling and reuse of algorithms and knowledge bases"""
# --------------------------
# Document parsing algorithm pool
# --------------------------
DOC_PARSERS = {
"mineru": MinerUPDFReader(), # Advanced PDF parsing with OCR
"basic_pdf": SimplePDFParser(), # Lightweight PDF parsing
"docx": OfficeParser(), # Strict mode Word parsing
"html": BeautifulSoupParser()
}
# --------------------------
# Node parsing algorithm pool
# --------------------------
NODE_PARSERS = {
"semantic_chunk": SemanticNodeSplitter(), # Semantic chunking
"graph_based": KnowledgeGraphParser() # Financial entity identification
}
# --------------------------
# Embed model pool
# --------------------------
EMBEDDINGS = {
"general": SentenceTransformer(), # General semantics
"finance": FinBERTEMbedding(),# Dedicated to the financial field
"bio": BioClinicalBERT.from_pretrained()
}
# --------------------------
# Similarity calculation strategy
# --------------------------
@staticmethod
@fc_register(name="euclidean")
def euclidean_sim(query, nodes):
pass
@staticmethod
@fc_register(name="ifdif")
def ifdif_sim(query, node):
pass
The previous code example shows how to build an "algorithm pool" that enterprises can expand and maintain according to their own needs. After completing the registration, the system can select appropriate algorithm components as needed based on specific business scenarios to realize the design concept of "Algorithm as a Service".
Take a financial risk control scenario that requires extremely high accuracy as an example:
- Embedding model FinBERT fine-tuned for financial text was selected to obtain more precise semantic encoding;
- Document Parser uses a high-precision PDF parsing tool with OCR capabilities to ensure the structural integrity of complex documents such as contracts;
- Node parsing adopts a semantic segmentation strategy to retain the semantic context of key information and improve recall quality.
The code example is as follows:
# Financial risk control (high-precision orientation)--processing complex PDF contracts, requiring identification of legal entities and financial terms
law_kb = Document("path/to/kb", name='Financial Risk Control Knowledge Base', embed=AlgorithmRegistry.EMBEDDINGS['finance']) # Select the BERT fine-tuning model in the financial field
law_kb.add_reader(AlgorithmRegistry.DOC_PARSERS['mineru']) # Choose to process complex PDF contracts, which require identification of fine legal entities and financial terms.
law_kb.create_node_group(name='semantic_nodes', transform=AlgorithmRegistry.NODE_PARSERS['semantic_chunk']) # Select semantic chunking algorithm
# Define retriever and select node group and similarity calculation method
retriever = Retriever(
group_name="semantic_nodes",
similarity="cosine",
topk=1
)
✅ The application scenarios of the same set of algorithms in multiple knowledge bases have been discussed in the previous permissions section.
📌 Next, we implement the scenario of diversifying algorithms through different document groupings in the same knowledge base.
docs = Document(path, manager=True, embed=OnlineEmbeddingModule())
# Register group
Document(path, name='Legal Document Management Group', manager=docs.manager)
Document(path, name='Product Document Management Group', manager=docs.manager)
# Simulate document upload
docs.start()
files = [('files', ('Product Documentation.txt', io.BytesIO("This is information about the product. This document is written by the product department.\nFrom the Product Documentation Management Group".encode("utf-8")), 'text/plain'))]
files = [('files', ('Legal Document.txt', io.BytesIO("This is a description of legal affairs. This document is organized by the Legal Department.\nFrom the Legal Document Management Group".encode("utf-8")), 'text/plain'))]
…
# Set the segmentation method for the product document management group to segment by paragraph.
doc1 = Document(path, name='Product Document Management Group', manager=docs.manager)
doc1.create_node_group(name="block", transform=lambda s: s.split("\n") if s else '')
retriever1 = Retriever([doc1], group_name="block", similarity="cosine", topk=3)
# Set the segmentation method for the legal document management group to segment by sentence
doc2 = Document(path, name='Legal Document Management Group', manager=docs.manager)
doc2.create_node_group(name='line', transform=lambda s: s.split("。") if s else '')
retriever2 = Retriever([doc2], group_name="line", similarity="cosine", topk=3)
2. Recall decoupling: Support flexible collaboration between knowledge base and recall service
In order to cope with complex knowledge sharing and reuse requirements, enterprises increasingly need flexible and efficient knowledge organization structures and management capabilities:
Requires many-to-many knowledge organization structure
- Enterprises often hope to centrally manage multiple knowledge bases through a unified document management service, which not only supports the independent maintenance of knowledge content by each business department, but also ensures controlled sharing when needed.
- The same knowledge base can also be called by multiple RAG recall systems, realizing knowledge reuse across business systems and improving the coverage and intelligent capabilities of model services.
Requires knowledge reuse capabilities in multiple business scenarios
- Facing diversified business needs such as customer service, compliance, risk control, and market, companies must ensure that knowledge can be efficiently reused, and at the same time, it can be independently updated and adapted flexibly according to scenarios.
In order to meet the above needs, LazyLLM not only provides a flexible document management module, but also completely decouples document management and RAG recall services to meet the diversity of enterprise knowledge management and recall needs. The benefits of this are specifically reflected in:
- Many-to-many management mode: One document management service can manage multiple knowledge bases at the same time, supporting the knowledge storage needs of different business departments.
- Multiple RAG Adaptation: The same Knowledge Base can be applied to Multiple RAG Recall Services, and one RAG Recall Service can retrieve data from multiple Knowledge Bases.
Thanks to this decoupling design, it is ensured that enterprises can dynamically adjust the binding relationship between the knowledge base and the RAG recall service in different business scenarios to meet personalized knowledge management needs.
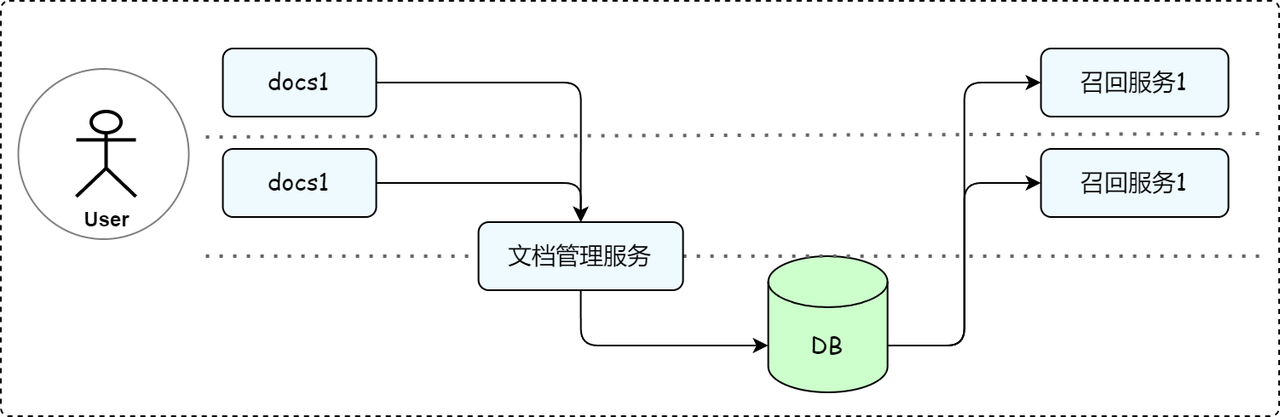
In specific implementation, only the following two steps are needed to build a multi-knowledge base management and recall process.
1.Initialize knowledge base
There are two ways to initialize the knowledge base:
- Path definition method: If you already have organized knowledge base documents, you can directly define the knowledge base by specifying the file path.
- Dynamic management method: If the knowledge base needs to be dynamically adjusted, you can upload, delete and manage it by starting the knowledge base service.
Note: The method of uploading documents by starting the service can only bind one path. If there are multiple databases with different paths, it is recommended to use the path definition method; flexibly register different algorithms for different knowledge bases, but the name of the node group needs to be kept consistent for subsequent joint recall.
from lazyllm.tools import Document
from lazyllm import OnlineEmbeddingModule
import time
# =============================
# Method 1. By defining the path
# =============================
law_data_path = "path/to/docs/law"
product_data_path = "path/to/docs/product"
support_data_path = "path/to/docs/support"
law_knowledge_base = Document(law_data_path, name='Legal Knowledge Base', embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
product_knowledge_base = Document(product_data_path,name='Product Knowledge Base', embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
support_knowledge_base = Document(support_data_path,name='Customer Service Knowledge Base', embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
# =============================
# Method 2. Through document uploading
# =============================
data_path = "path/to/docs"
law_knowledge_base = Document(data_path, name='Legal Knowledge Base', manager="ui", embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
# Share the manager through the manager of the legal knowledge base
product_knowledge_base = Document(
data_path,
name='Product Knowledge Base',
manager=law_knowledge_base.manager,
)
law_knowledge_base.start()
#... Manually add or delete files after the service is started... #
2.Enable RAG recall service
After the knowledge base is defined, recall services can be flexibly configured for different knowledge bases as needed. Just pass the document management object into the defined Retriever. For details on how to use Retriever, please refer to the previous eighth tutorial [Elective 2: Customized Recall Strategy Related Components]. Enterprises can configure data processing algorithms through business requirements, register them as node_group, and use them when recalling.
from lazyllm import Retriever, SentenceSplitter
# Configure and define data processing algorithms, which can be customized according to business needs
Document.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
# Combine legal affairs + product knowledge base to handle product-related legal issues
retriever_product = Retriever(
[law_knowledge_base, product_knowledge_base],
group_name="sentences", # Group name (selected based on business requirements)
similarity="cosine", # Similarity parameter (according to model configuration)
topk=2 # Recall the top 2 most relevant results
)
product_question = "A product functional parameters and product compliance statement"
product_res_nodes = retriever_product(product_question)
# Combine legal affairs + customer knowledge base to handle customer support related issues
retriever_support = Retriever(
[law_knowledge_base, support_knowledge_base],
group_name="sentences",
similarity="cosine",
topk=2
)
support_question = "How to handle customer complaints and the legal issues that may result"
support_res_nodes = retriever_support(support_question)
...
An example of the search results is as follows. When searching for the question "A product functional parameters and product compliance statement", the product parameter content in the product knowledge base and the relevant terms in the regulatory knowledge base can be retrieved at the same time:
print(f"query: {product_question }")
print("retrieve nodes:")
for node in product_res_nodes :
print(node.text)
print()
"""
query: A product function parameters and product compliance statement
retrieve nodes:
Functional parameters of A intelligent management system
3.1 System performance
Concurrent processing capability: Supports high concurrent access to meet enterprise-level application requirements.
Response Time: Maintain low latency response under high load conditions.
Data throughput: Supports fast reading, writing and processing of large-scale data.
3.2 Compatibility
Operating system support: compatible with Linux and Windows operating systems.
Database compatibility: Supports mainstream databases such as MySQL and PostgreSQL.
3.3 Security
Data encryption: Supports encryption of static data and transmitted data.
Access control: role-based permission management to ensure data security.
1. Product Conformity Statement
The company strictly abides by the following laws and regulations during product design, development, production and sales:
"Product Quality Law" - ensures that products comply with national quality standards and do not contain false propaganda.
"Consumer Rights and Interests Protection Law" - protects the legitimate rights and interests of users in the process of using products.
"Data Security Law" - Strictly protect users' personal information and shall not disclose it to third parties without authorization.
2. Intellectual property rights and legal liability
All codes, algorithms and technologies involved in the company's products are protected by the Copyright Law and the Patent Law.
Users may not modify, copy or distribute any components of the Company's products without authorization.
If the user suffers losses due to product defects, the company is responsible for repairs, but the company is not responsible for losses caused by improper use or failure to comply with product instructions.
3. Responsibility for contract performance
The company clearly stipulates product functions, delivery standards and service periods in the contract.
If the content of the contract is not fulfilled due to the company's reasons, the user has the right to require the company to bear liability for breach of contract according to the terms of the contract.
If a user embeds or calls plug-ins, script tools or unauthorized APIs in the product, the company reserves the right to terminate the service and reserves the right to pursue legal liability.
"""
Through flexible knowledge base configuration and controllable RAG recall service, LazyLLM can realize the diversity of sharing methods.
4. Dialogue management and solutions
In the actual business of enterprises, the dialogue system needs to be able to remember the user's previous chat content and better understand the user's current needs based on historical dialogue. For example, the customer service robot needs to know what questions the user has asked before to avoid repeated answers; or the AI assistant can combine previous chat content to optimize the current question and make the answer more accurate.
At the same time, the system must support simultaneous use by multiple users to ensure that conversations between different users do not interfere with each other. For example, user A is chatting with the robot about order issues, and user B is consulting product information. The system must be able to distinguish their conversation records without confusion. In addition, real-time streaming output must be supported, allowing users to see replies step by step like a normal chat, instead of waiting for all to be generated before displaying.
In order to realize these functions, lazyllm provides a unified configuration center globals, which manages the conversation history, contextual information, etc. of different users, and automatically cleans up unnecessary data after the conversation ends to avoid wasting resources. Through globals, the system can isolate the conversation history and context of different sessions to avoid data interference, and at the same time, centrally save user conversation parameters, incoming file paths, and intermediate results generated during the conversation for subsequent processing. This design ensures data consistency and efficient flow between services.
Next, we will introduce how to implement historical conversation management and multi-user concurrent conversation management through globals.
1. Historical dialogue management
First, we combine the globals configuration center to implement a dialogue process that supports historical context and streaming output. lazyllm.OnlineChatModule(stream=True) initializes a large language model that supports streaming output, and uses ThreadPoolExecutor to establish a thread pool to support up to 50 concurrent requests. Each request is allocated a free position in slots to ensure that the set maximum number of connections is not exceeded at the same time.
- Each time a new session is started,
init_session_configwill combine the default few-shot prompts and user-defined historical conversations, and uniformly initialize them into theglobalsspace under the correspondingsession_idto ensure that each session has an independent context. - In order to safely manage the model inference process in a multi-threaded environment, the
respond_streammethod usescontextvarsto copy the current context when submitting inference tasks to avoid concatenation of context variables between different sessions. During the entire response process, the streaming effect of generating and outputting is achieved throughFileSystemQueue, and after the inference is completed, the latest user input and assistant reply are appended to the session history.
In order to conveniently manage the session life cycle, the system provides the with_session decorator to automatically complete context switching, and the handle_request function serves as a unified entrance and can initiate a new streaming conversation based on the incoming session_id and historical records. This mechanism not only realizes multi-user isolation and historical memory management, but also ensures stability and consistency in high concurrency scenarios, providing basic support for subsequent access to more complex interactions.
from lazyllm import globals
llm = lazyllm.OnlineChatModule(stream=True)
threadPool = ThreadPoolExecutor(max_workers=50)
slots = [0] * 50
# public few shot history
DEFAULT_FEW_SHOTS = [
{"role": "user", "content": "Who are you?"},
{"role": "assistant", "content": "I am your smart assistant."}
]
class ChatHistory(BaseModel):
user: str
assistant: str
class ChatRequest(BaseModel):
user_input: str
history: Optional[List[ChatHistory]] = None
def allocate_slot():
for idx, val in enumerate(slots):
if val == 0:
slots[idx] = 1
return idx
return -1
def release_slot(session_id):
if 0 <= session_id < len(slots):
slots[session_id] = 0
globals.pop(session_id)
def init_session_config(session_id, user_history=None):
globals._init_sid(session_id)
if user_history is not None:
history = []
# Merge few-shot + user history
history.extend(DEFAULT_FEW_SHOTS)
for h in user_history:
history.append({"role": "user", "content": h.user})
history.append({"role": "assistant", "content": h.assistant})
globals["global_parameters"]["history"] = history
else:
if "history" not in globals["global_parameters"]:
globals["global_parameters"]["history"] = copy.deepcopy(DEFAULT_FEW_SHOTS)
def with_session(func):
def wrapper(session_id, *args, **kwargs):
globals._init_sid(session_id)
return func(session_id, *args, **kwargs)
return wrapper
class SessionResponder:
def __init__(self):
pass
def respond_stream(self, session_id, model_in, user_history=None):
init_session_config(session_id, user_history)
print("[Respond Stream] Current SID:", globals._sid)
history = globals["global_parameters"]["history"]
print("history", history)
ctx = contextvars.copy_context()
func_future = threadPool.submit(lambda: ctx.run(llm, model_in, llm_chat_history=history))
response = ''
while True:
assert session_id == globals._sid, f"\nSession ID mismatch: expected {session_id}, got {globals._sid}"
if message := FileSystemQueue().dequeue():
msg = "".join(message)
response += msg
yield msg
elif func_future.done():
break
model_out = func_future.result()
assert session_id == globals._sid, f"Session ID mismatch after LLM: expected {session_id}, got {globals._sid}"
# Update history
globals["global_parameters"]["history"].append({
"role": "user",
"content": model_in
})
globals["global_parameters"]["history"].append({
"role": "assistant",
"content": model_out
})
return model_out
@with_session
def handle_request(session_id: str, user_input: str, user_history: Optional[List[ChatHistory]] = None):
chat = SessionResponder()
for chunk in chat.respond_stream(session_id, model_in=user_input, user_history=user_history):
print(chunk, end='', flush=True)
Overall, this code relies on globals to achieve:
- Flexible loading and isolation management of historical conversations of different users;
- Supports few-shot examples preset within the system to guide the model to better understand the task;
- Summarize, rewrite and generate new dialogue content or questions based on historical context.
Let's take a look at the execution effect:
###################################
# Use historical conversations
###################################
history = [
ChatHistory(
user="What is banana in English?",
assistant="The English word for banana is banana"
),
ChatHistory(
user="What about Apple?",
assistant="Apple in English is apple"
)
]
user_input = "What about the oranges?"
response = ""
for chunk in respond_stream(session_id, user_input, history):
response += chunk
# >>> The English word for orange is orange.
#####################################
# Internal preset few-shot example
#####################################
DEFAULT_FEW_SHOTS = [
{"user": "Please help me rephrase: 'This report is not bad.'",
"assistant": "The overall performance of this report is good, but there is still room for improvement."},
{"user": "Please help me optimize: 'Our sales performance is good.'",
"assistant": "Our sales performance was outstanding and we met our expectations."},
]
user_input = "Please help me rewrite: 'Customer feedback that our service attitude is very good.'"
# >>> Customers have given positive comments on our service attitude.
#####################################
# Summarize historical examples
#####################################
history = [
ChatHistory(
user="What is machine learning?",
assistant="Machine learning is the science of developing algorithms and statistical models that computer systems use to perform tasks without explicit instructions, relying on established patterns and reasoning"
),
ChatHistory(
user="Application scenarios of machine learning?",
assistant="Machine learning is widely used in recommendation systems, such as product recommendations on e-commerce websites, content recommendations on social media, etc. By analyzing users' historical behaviors and preferences, machine learning algorithms can predict content that users may be interested in and provide personalized recommendations. Natural language processing: Natural language processing is another important application area of machine learning, including speech recognition, machine translation, sentiment analysis, Spam filtering, etc. Machine learning algorithms can help computers understand and generate human language and realize intelligent human-computer interaction. Image recognition and processing: Machine learning also plays an important role in image recognition and processing, such as face recognition, license plate recognition, image retrieval, object recognition, etc. By training a large amount of image data, machine learning algorithms can learn and identify features in images, thereby achieving intelligent processing of images."
)
]
user_input = "Summary of this conversation"
# >>> This conversation mainly revolves around machine learning. It first explains the definition of machine learning, which is to use algorithms and statistical models to allow computer systems to complete tasks based on existing patterns and reasoning without explicit instructions. Then the application scenarios of machine learning were discussed, including recommendation systems (such as personalized recommendations for e-commerce and social media), natural language processing (such as speech recognition, machine translation, sentiment analysis, etc.), and image recognition and processing (such as face recognition, object recognition, etc.). Finally, the important role of machine learning in intelligent tasks is summarized.
- In the first request, only "orange" is entered, and the system normally generates the answer "orange" related to oranges according to the historical context.
- The third request is to input "summarize this conversation", and the system successfully outputs the conversation summary based on the complete history.
- and pre-assigned conversations are also in ChatHistory.
2. Multi-user concurrent conversation management
Also based on the above design, the following code further improves the multi-user session management and historical conversation tracking mechanism based on globals. The system initializes a streaming reasoning module lazyllm.OnlineChatModule(stream=True), and supports up to 50 concurrent requests through ThreadPoolExecutor. At the same time, it manages connection resources through the slots array to ensure that different user sessions do not interfere with each other.
- Whenever a new request arrives, the
init_session_configmethod initializes the context environment under the correspondingsession_idbased on the incoming user history. If there is no history, a blank conversation history is assigned by default to ensure that each session track is independent. To simplify context switching for multiple session calls, thewith_sessiondecorator automatically binds the correctsession_idbefore executing the function. - During actual reasoning, the
SessionResponderclass is responsible for initiating streaming conversations, and usescontextvarsinternally to capture the current context, ensuring that correct session isolation can be maintained even when inference tasks are performed in the thread pool. The system implements streaming output throughFileSystemQueue, and returns the generated content in real time during the reasoning process. After the reasoning is completed, the current round of dialogue is completely appended to the history record for subsequent continuous dialogue use.
Finally, an external example shows how to use the handle_request function to initiate multiple rounds of dialogue. The system can correctly maintain independent and continuous dialogue flows between multiple users, ensuring that the historical contexts of different users are not confused, laying a good foundation for supporting application scenarios with high concurrency and strong context coherence.
llm = lazyllm.OnlineChatModule(stream=True)
threadPool = ThreadPoolExecutor(max_workers=50)
slots = [0] * 50
DEFAULT_FEW_SHOTS = []
class ChatHistory(BaseModel):
user: str
assistant: str
class ChatRequest(BaseModel):
user_input: str
history: Optional[List[ChatHistory]] = None
def allocate_slot():
for idx, val in enumerate(slots):
if val == 0:
slots[idx] = 1
return idx
return -1
def release_slot(session_id):
if 0 <= session_id < len(slots):
slots[session_id] = 0
globals.pop(session_id)
llm = lazyllm.OnlineChatModule(stream=True)
def init_session_config(session_id, user_history=None):
globals._init_sid(session_id)
# if globals._sid not in globals._Globals__data:
# globals._Globals__data[globals._sid] = copy.deepcopy(globals.__global_attrs__)
if user_history is not None:
globals["global_parameters"]["history"] = user_history
else:
if "history" not in globals["global_parameters"]:
globals["global_parameters"]["history"] = []
def with_session(func):
"""Decorator that automatically binds session_id"""
def wrapper(session_id, *args, **kwargs):
globals._init_sid(session_id)
return func(session_id, *args, **kwargs)
return wrapper
class SessionResponder:
def __init__(self):
pass
def respond_stream(self, session_id, model_in, user_history=None):
init_session_config(session_id, user_history)
print("[Respond Stream] Current SID:", globals._sid)
history = globals["global_parameters"]["history"]
print("history", history)
# Capture the current context (make sure tasks submitted by the thread pool also have context)
ctx = contextvars.copy_context()
func_future = threadPool.submit(lambda: ctx.run(llm, model_in, llm_chat_history=history))
response = ''
while True:
assert session_id == globals._sid, f"\nSession ID mismatch: expected {session_id}, got {globals._sid}"
if message := FileSystemQueue().dequeue():
msg = "".join(message)
response += msg
yield msg
elif func_future.done():
break
model_out = func_future.result()
assert session_id == globals._sid, f"Session ID mismatch after LLM: expected {session_id}, got {globals._sid}"
# globals["global_parameters"]["history"].append(model_out)
globals["global_parameters"]["history"].append({
"role": "user",
"content": model_in
})
globals["global_parameters"]["history"].append({
"role": "assistant",
"content": model_out
})
return model_out
#External usage example
@with_session
def handle_request(session_id: str, user_input: str):
chat = SessionResponder()
for chunk in chat.respond_stream(session_id, model_in=user_input):
print(chunk, end='', flush=True)
if __name__ == "__main__":
handle_request("user321", "What is Apple in English!")
print("\n\n")
handle_request("user123", "What is machine learning")
print("\n\n")
handle_request("user321", "Where's the banana")
print("\n\n")
handle_request("user123", "What is it used for?")
Effect example:
- When user
id1asks "Apple in English" and then "Banana", the model can remember that the current session is a translation task. - After user
id2asks "What is machine learning?" and then asks "What does it do?", the model can correlate the context to explain the application scenario.
The two dimensions of historical dialogue are independent and do not affect each other.
❗Note that to implement the above functions, you need to use the redis database to implement file system output management. The setting method is:
export LAZYLLM_DEFAULT_FSQUEUE=SQLITE
export LAZYLLM_FSQREDIS_URL=redis://[user name]:[password]@[host]/[port]
5. Security requirements and solutions
Finally, in the process of building a knowledge base, enterprises must not only ensure internal information security, but also pay attention to external security when facing the public to prevent data leakage, information abuse and potential compliance risks.
1.Enterprise Security
In the construction of enterprise knowledge base, security is always the primary consideration. Especially when the knowledge base contains highly sensitive or private data such as company policies, financial statements, customer contracts, etc., any information leakage may result in serious legal liability and business losses. For this reason, the system needs to have a complete protection mechanism.
(1) Encryption
- Private Data Protection: Through the data isolation mechanism, ensure data isolation between different businesses or departments to prevent data leakage.
- Knowledge Encryption: Full-link encryption of documents during storage and transmission to ensure data confidentiality and integrity.
- Model Encryption: Supports data encryption during model calling to avoid leakage of sensitive information.
(2)Private deployment
- Localized model inference engine: The core components are deployed in the intranet environment to ensure data security.
- Local data processing: Ensure that knowledge data is completed within the enterprise to avoid leakage.
- Enhanced access control: Combines network isolation and multi-factor authentication to achieve secure access.
(3)Xinchuang
In order to ensure that the core technology is independent and controllable, the system is fully compatible with software and hardware products in the National Information Innovation Directory.
- Domestic CPU: Kunpeng, Loongson, etc., providing high-performance computing support.

- Domestic operating systems: Kirin, Tongxin UOS, etc., ensuring the underlying security of the system.
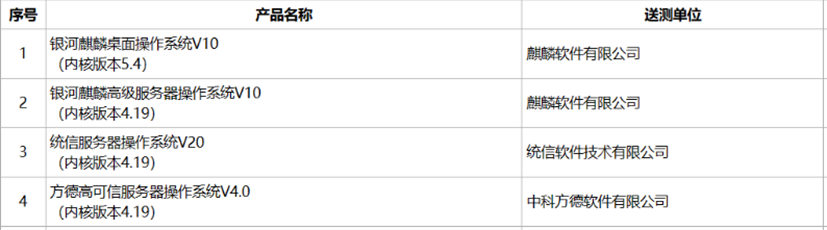
- Domestic databases: Dameng, Renmin University of Finance and Economics, etc., where sensitive data can be stored with greater confidence.

- Full-link compliance: From chips (such as Kunpeng/Feiteng) to software, all comply with Xinchuang standards and pass national information security certification.
2. Public safety
In an enterprise-level RAG system, public safety is not only related to the company's own reputation and compliance risks, but also to the impact of model output on social public opinion, information security and even national security. The system should have the following capabilities to ensure that the content generated by the model does not breach the bottom line of public safety:
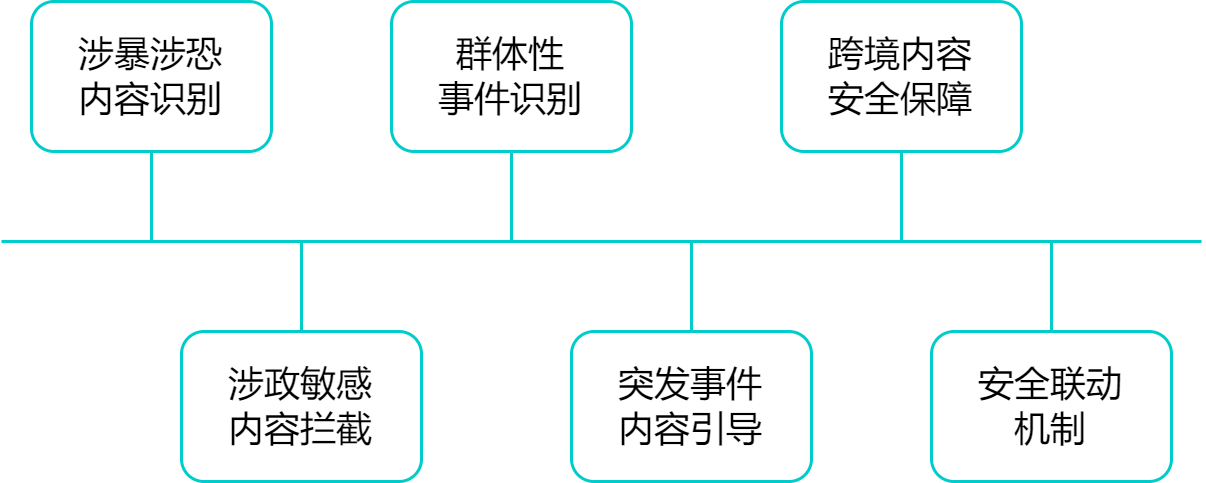
- Identification of violence-related and terrorism-related content: Automatically detect content related to violence, terrorism, and extremist speech to prevent the model from becoming a channel for the dissemination of illegal information.
- Interception of politically sensitive content: Accurately identify and block separatist speech, illegal organization propaganda, rumor and incitement, etc. to avoid the risk of political sensitivity.
- Mass incident identification: Identify content in model output that may incite public gathering, confrontation or panic to prevent public opinion from fermenting and escalating.
- Emergency content guidance: When major disasters, public health or social events occur, provide a proven information output mechanism to reduce the risk of false content spread.
- Cross-border content security: In foreign-related output scenarios, it supports configuring identification strategies for sensitive countries/regions, organizations and diplomatic events to ensure that external stance is legal and compliant.
- Security linkage mechanism: Supports connection with enterprise security systems, supervision platforms or emergency response mechanisms to achieve real-time discovery and rapid response to content risks.
Through the construction of public safety modules, enterprises can effectively prevent and control social risks that may be caused by large models in the process of generating content, improve their digital governance capabilities, and fulfill platform responsibilities.
How to maintain public safety?
During the knowledge base management and retrieval process, some sensitive information or illegal content may be involved, such as personal privacy, legal compliance terms, etc. Therefore, the system needs to have a comprehensive filtering mechanism to automatically identify and block sensitive words during the data upload, storage and retrieval stages to prevent the misuse or leakage of sensitive information. LazyLLM supports flexible custom rule configuration. Administrators can dynamically maintain sensitive word lists based on the actual needs of the enterprise, and combine word segmentation, regular expressions, DFA (Deterministic Finite Automaton) and other algorithms to achieve precise filtering. Next, let’s look at how to connect the DFA algorithm, a typical algorithm for sensitive word filtering, to lazyllm to implement sensitive word filtering.
Step 1: Implement the definition of the DFA algorithm by defining the lazyllm module, and package it into a component that can be connected to lazyllm. For details, see [Elective 2: Custom Recall Strategy Related Components] - Class-based custom Transform algorithm.
from lazyllm.tools.rag import DocNode, NodeTransform
from typing import List
#Define DFA algorithm
class DFAFilter:
def __init__(self, sensitive_words):
self.root = {}
self.end_flag = "is_end"
for word in sensitive_words:
self.add_word(word)
def add_word(self, word):
node = self.root
for char in word:
if char not in node:
node[char] = {}
node = node[char]
node[self.end_flag] = True
def filter(self, text, replace_char="*"):
result = []
start = 0
length = len(text)
while start < length:
node = self.root
i = start
while i < length and text[i] in node:
node = node[text[i]]
if self.end_flag in node:
# Match the sensitive word and replace it with the specified character
result.append(replace_char * (i - start + 1))
start = i + 1
break
i += 1
else:
# No sensitive words are matched, keep the original characters
result.append(text[start])
start += 1
return ''.join(result)
# Register as transform
class DFATranform(NodeTransform):
def __init__(self, sensitive_words: List[str]):
super(__class__, self).__init__(num_workers=num_workers)
self.dfafilter = DFAFilter(sensitive_words)
def transform(self, node: DocNode, **kwargs) -> List[str]:
return self.dfafilter.filter(node.get_text())
def split_text(self, text: str) -> List[str]:
if text == '':
return ['']
paragraphs = text.split(self.splitter)
return [para for para in paragraphs]
Step 2, register the defined DFAFilter as the node group of the document service. We also use the search question of "A product functional parameters and product compliance statement" in the previous section. Assuming that the word [contract] is blocked, we only need to register DFAFilter as a new node and inherit the processing method of the previous step through parent="sentences".
from lazyllm import Retriever, SentenceSplitter
# Define business sensitive words
sensitive_words = ['contract']
# Embed sensitive word filtering algorithm into business logic
Document.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=128, chunk_overlap=10)
Document.create_node_group(name="dfa_filter", parent="sentences", transform=DFATranform(sensitive_words))
# Combine legal affairs + product knowledge base to handle product-related legal issues
retriever_product = Retriever(
[law_knowledge_base, product_knowledge_base],
group_name="dfa_filter", # Specify dfa_filter
similarity="cosine",
topk=2
)
product_question = "A product functional parameters and product compliance statement"
product_res_nodes = retriever_product(product_question)
As you can see, the output has replaced "sensitive words" and "contract" with asterisks. In enterprise application scenarios, sensitive lexicon can be customized according to business needs to enhance data security.
Before blocking:

After blocking:

Full-process sensitive word filtering In practical applications, in addition to filtering sensitive words on the original document content, we also need to perform the same processing on user input and large model output.
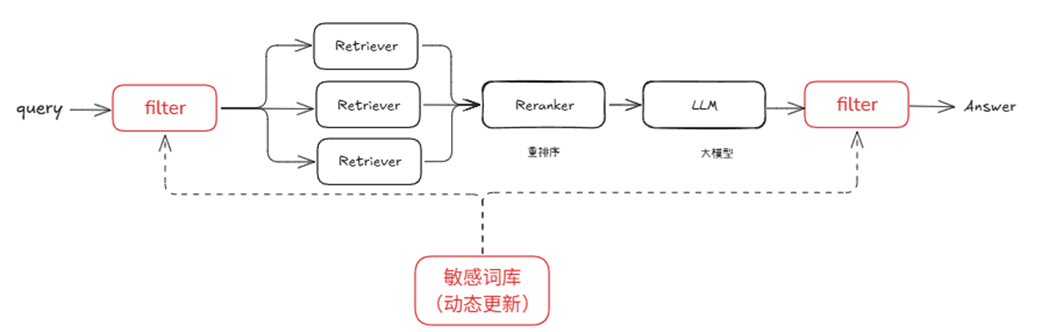
with pipeline() as ppl:
ppl.query_filter = lambda x: DFAFilter(sensitive_words).filter(x)
ppl.retriever = Retriever(...)
ppl.reranker = ...
ppl.llm = ...
ppl.output_filter = lambda x: DFAFilter(sensitive_words).filter(x)
For enterprise-level needs, lazyllm provides flexible document management and recall services. By configuring different algorithms and knowledge bases, the system can meet cross-department data processing and precise recall needs in different business scenarios. With the help of database management functions, the system realizes data isolation and authority control, effectively ensuring the security of private data. At the same time, the system supports tag retrieval and sensitive word filtering to further improve the accuracy and compliance of retrieval, helping enterprises to efficiently manage and utilize knowledge bases in complex data environments.
6. Overall implementation idea of enterprise-level RAG
In the previous article, we analyzed in detail the core needs and challenges faced by the enterprise-level RAG system in the actual implementation process from multiple dimensions such as permission control, sharing methods, and security assurance. Next, we will integrate the above elements and propose a fully functional and implementable enterprise-level RAG construction idea.
1. Architecture diagram
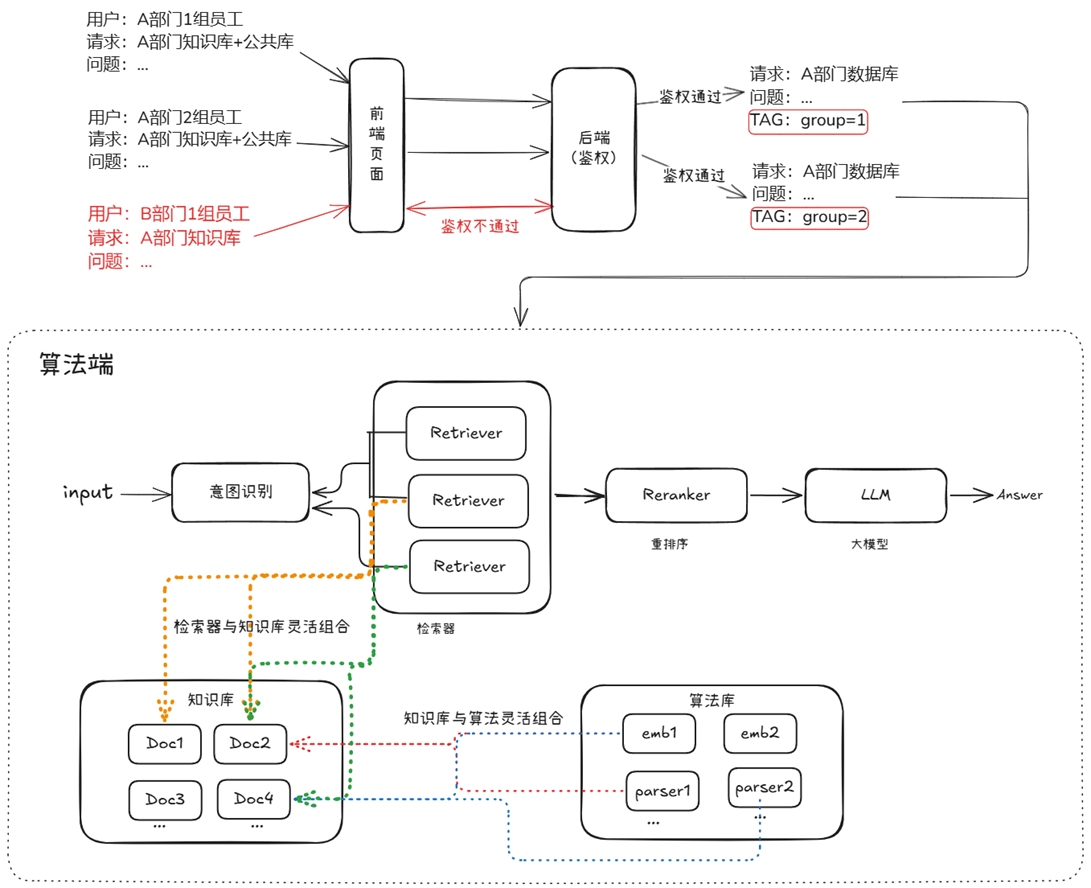
This enterprise-level RAG system is mainly composed of user access, intent recognition, searcher, knowledge base, algorithm library, resequencer and large model modules. Users submit queries through the access module, and the request first passes through the intent recognition module, which determines the query intent and dynamically determines subsequent retrieval strategies. The retriever module is composed of multiple Retrievers and can flexibly call different knowledge bases and algorithm libraries to complete retrieval tasks with multiple strategies and multiple data sources. The knowledge base is used to store various structured or unstructured documents, and the algorithm library contains a variety of vectorization tools and parsers to support the encoding and processing of knowledge data. Both can be flexibly combined as needed. After the retrieval is completed, the candidate results are optimized for relevance by the re-ranking module, and then generated by a large language model (LLM) based on the optimized content, and finally output answers that meet user needs. The entire system design emphasizes module decoupling, flexible strategies, and enhanced generation, adapting to the needs of multi-user, high-concurrency, and multi-scenario enterprise applications.
2. Code implementation
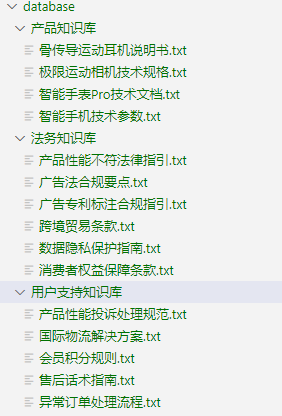
Next, taking an e-commerce scenario as an example, we will build a RAG question and answer system with the above functions. A total of three knowledge bases are used in this example. The data preparation is as shown in the figure. The database construction method has been introduced in detail in Chapter 2 and will not be repeated here.
We jointly search the product knowledge base and the legal knowledge base to handle product and legal related issues; at the same time, we combine the legal knowledge base and the user support knowledge base to deal with user support issues. To do this, first build two independent RAG pipelines.
with pipeline() as product_law_ppl:
product_law_ppl.retriever = retriever = Retriever(
[doc_law, doc_product],
group_name="dfa_filter",
topk=5,
embed_keys=['dense'],
)
product_law_ppl.reranker = Reranker(name="ModuleReranker",
model=OnlineEmbeddingModule(type='rerank'),
topk=2, output_format="content", join=True) | bind(query=product_law_ppl.input)
product_law_ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=product_law_ppl.input)
product_law_ppl.llm = OnlineChatModule().prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
with pipeline() as support_law_ppl:
support_law_ppl.retriever = retriever = Retriever(
[doc_law, doc_support],
group_name="dfa_filter",
topk=5,
embed_keys=['dense'],
)
support_law_ppl.reranker = Reranker(name="ModuleReranker",
model=OnlineEmbeddingModule(type='rerank'),
topk=2, output_format="content", join=True) | bind(query=support_law_ppl.input)
support_law_ppl.formatter = (lambda nodes, query: dict(context_str=nodes, query=query)) | bind(query=support_law_ppl.input)
support_law_ppl.llm = OnlineChatModule().prompt(lazyllm.ChatPrompter(prompt, extra_keys=["context_str"]))
To provide users with a unified Q&A entrance and achieve seamless switching between different knowledge bases, we introduced a user intent recognition module that can automatically select the appropriate RAG pipeline for processing based on the query content.
def build_ecommerce_assistant():
llm = OnlineChatModule(source='qwen', stream=False)
intent_list = [
"Product Legal Issues",
"User support issues",
]
with pipeline() as ppl:
ppl.classifier = IntentClassifier(llm, intent_list=intent_list)
with lazyllm.switch(judge_on_full_input=False).bind(_0, ppl.input) as ppl.sw:
ppl.sw.case[intent_list[0], product_law_ppl]
ppl.sw.case[intent_list[1], support_law_ppl]
return ppl
In order to implement multi-user concurrent session requests and maintain independent contexts, we encapsulated EcommerceAssistant through the globals manager to ensure the isolation of user questions and answers.
def init_session(session_id, user_history: Optional[List[ChatHistory]] = None):
globals._init_sid(session_id)
if "global_parameters" not in globals or "history" not in globals["global_parameters"]:
globals["global_parameters"]["history"] = []
if not globals["global_parameters"]["history"]:
# Initialize to default few-shot
globals["global_parameters"]["history"].extend(DEFAULT_FEW_SHOTS)
if user_history:
for h in user_history:
globals["global_parameters"]["history"].append({"role": "user", "content": h.user})
globals["global_parameters"]["history"].append({"role": "assistant", "content": h.assistant})
def build_full_query(user_input: str):
"""Generate full query text with history based on the history in globals"""
history = globals["global_parameters"]["history"]
history_text = ""
for turn in history:
role = "user" if turn["role"] == "user" else "assistant"
history_text += f"{role}: {turn['content']}\n"
full_query = f"{history_text}user: {user_input}\nAssistant:"
return full_query
class EcommerceAssistant:
def __init__(self):
self.main_pipeline = build_ecommerce_assistant()
def __call__(self, session_id: str, user_input: str, user_history: Optional[List[ChatHistory]] = None):
init_session(session_id, user_history)
full_query = build_full_query(user_input)
# Input the query with history into the main pipeline
response = self.main_pipeline(full_query)
# Update history to globals
globals["global_parameters"]["history"].append({"role": "user", "content": user_input})
globals["global_parameters"]["history"].append({"role": "assistant", "content": response})
return response
Now run the entire code to see the effect.
3. Result analysis
Running log:
==================== user1: User support issues ====================
User user1 asked:
"A user complained that the battery life of a certain smart watch did not meet the advertised effect. How to deal with it?"
Assistant replied:
When users complain that smart watch battery life does not meet the advertised effect, we need to handle it according to the three-level response mechanism:
1. **Technical Verification**: Please provide the device serial number and battery life test video (need to show the complete charge and discharge cycle). We will internally compare the promotional parameters through the tool [PERF_CHECK_V3].
2. **Legal Assessment**: Trigger the legal system to automatically generate a "Parameter Difference Analysis Report", refer to case FC-2024-021 for detailed comparison.
3. **Solution**:
- If the difference is ≤15%: We will give the user a 1-year extended warranty (service code SV-228).
- If the difference is >15%: According to Article 23 of the Consumer Rights Protection Law, we will provide replacement or triple the price difference.
Communication skills: "We attach great importance to the accuracy of product parameters and will entrust a third-party organization (such as SGS) to conduct retesting and give you a formal reply within 3 working days."
According to Article 23 of the "Consumer Rights Protection Law", the difference between the actual performance of the product and the advertised parameters exceeds the allowable error range of the industry standard (electronic equipment battery life error ±15%), which constitutes false advertising. Reference case FC-2024-021: A certain brand was sentenced to triple compensation for falsely marking the battery life of a smartwatch by 28%, and received an administrative penalty of 500,000 yuan from the Market Supervision Administration.
It is recommended that the technical department establish a standard process for battery life testing (which must comply with the GB/T 35143-2023 standard), and all promotional data must be accompanied by a description of the test environment (such as continuous use at 25°C in a laboratory environment).
============================================================
====================user2: Product legal issues (with historical dialogue) ====================
Conversation history for user user2:
1. User: "Hello"
Assistant: "Hello!"
2. User: "I would like to inquire whether the promotional content of the headphones is compliant."
Assistant: "Of course, please describe your promotional copy in detail."
New question from user user2:
"Bone conduction headphones do not display patent numbers"
Assistant replied:
According to the information provided, if the promotion of bone conduction headphones involves applied or authorized patented technology (such as bone conduction vibrator technology), but the patent number and patent type (invention, utility model or design) are not clearly marked, this may violate the requirements of Article 12 of the Advertising Law and relevant implementation rules.
The following is a specific analysis:
1. **Patent number marking problem**
- According to legal regulations, when mentioning patented technology in advertising, the patent number and patent type must be fully indicated. For example: "This product uses bone conduction vibrator technology, patent number: ZL2024XXXXXXX, utility model patent."
- If it only mentions "patent applied for" without specifying the specific patent number, it is illegal. Referring to the penalty case No. AD-2024-017, a technology company was fined 876,000 yuan for failing to indicate a patent number.
2. **Cross-border advertising requirements**
- If the headset is promoted in cross-border markets (such as exported to other countries), the patent authorization country code (such as CN/EP/US) must also be marked simultaneously. For example: "Patent number: ZL2024XXXXXXX, CN utility model patent."
3. **Technical Exclusivity Statement Compliance**
- Promotional copywriting must follow the "three no's principles":
- Do not imply technological monopoly (avoid using absolute terms such as "only" and "exclusive").
- Do not expand the scope of protection (ensure strict correspondence with the patent claims).
- Do not conceal changes in patent status (if the patent is declared invalid, promotional materials must be updated within 3 working days).
### suggestion
- **Add patent information immediately**: clearly indicate the patent number and type in the promotion. If a patent application is pending, it should be noted as "patent pending" rather than directly stating "patent applied for".
- **Avoid absolute terms**: Do not use expressions such as "world-leading" or "unique" to avoid the risk of false propaganda.
- **Regularly check patent status**: Ensure that the promotional content is consistent with the actual patent status and updated in a timely manner.
If you are unable to provide a specific patent number or patent type, it is recommended to adjust the promotional copy first to avoid penalties for violations. For example, functional features could be described instead, such as "Advanced bone conduction technology is used to achieve IPX7 waterproof performance."
============================================================
====================user1: User support issue follow-up ====================
User user1 continues to ask:
"Are there any risks with this way of handling complaints?"
Assistant replied:
Although this processing method complies with laws, regulations and industry standards, it may still have the following potential risks:
1. **User trust is damaged**: If the battery life of the user's device varies greatly but does not exceed 15%, only providing extended warranty service may not be able to completely repair the user experience, thereby affecting brand faithfulness.
2. **Test environment controversy**: Promotional data are usually based on laboratory conditions (such as continuous use at 25°C), while actual usage scenarios are complex and changeable (high temperature, low temperature, high load, etc.). If the user does not understand or agree with the test environment instructions, it may lead to further complaints.
3. **Expanded legal risks**: If some products have false claims of battery life exceeding 15% and involve a large user group, they may be deemed to be systemic false propaganda and face class action lawsuits or more severe administrative penalties.
4. **Technical verification efficiency issues**: Comparison through the tool [PERF_CHECK_V3] takes a certain amount of time. If the response speed is too slow, user dissatisfaction may escalate into a public opinion incident.
### Risk avoidance suggestions:
- **Proactive optimization of publicity strategy**: Clearly indicate the battery life test environment (such as "continuous use at 25°C in a laboratory environment") on the product page and packaging, and add an explanation of possible differences in actual use.
- **Establish a rapid response mechanism**: For battery life complaints, set up a special customer service team to ensure that preliminary assessments are completed and solutions are provided to users within 48 hours.
- **Strengthen internal process control**: The technical department needs to regularly update the battery life test standard process to ensure compliance with the requirements of GB/T 35143-2023, and synchronize the test results with market promotions.
- **Provide additional compensation measures**: For users whose battery life difference is close to a critical value, consider giving away accessories (such as chargers) or extending the warranty period to improve user satisfaction.
The ultimate goal is to minimize potential risks through transparent communication and proactive response, while maintaining brand image and user trust.
According to the above log, we achieved:
- Automatic intent recognition
Through the intent recognition function, the RAG system can automatically analyze the user's questions and select the appropriate processing process (Pipeline). For example, when it receives user support questions, it combines the "three-level response mechanism" of the user support library to propose communication skills, and combines it with Article 23 of the "Consumer Rights and Interests Protection Act" of the regulations library to propose targeted legal regulations; when it receives product regulatory questions, it retrieves content related to bone conduction vibrator technology from the product library, and combines the technology exclusivity statement compliance-related content of the regulations library.
This intent recognition function enables the system to respond to different types of problems more efficiently, and by automatically selecting the appropriate Pipeline, users' needs are quickly and accurately met, reducing the need for manual intervention and improving the overall response speed and service quality.
- Joint retrieval of multiple knowledge bases
In the assistant's answers, we can see the joint application of content from different knowledge bases. First of all, regarding complaints about smart watch battery life, the assistant not only provided specific test methods based on technical documents, but also quoted clauses and relevant cases in legal knowledge base, comprehensively covering multi-dimensional information such as product quality and consumer rights.
Similarly, for headphone promotion compliance issues, the assistant combines content from the Advertising Law and Patent Law knowledge bases to provide detailed legal analysis and compliance suggestions. This demonstrates the flexibility and efficiency of RAG's capabilities in handling complex problems, providing precise answers through joint knowledge bases across multiple fields.
- Separation of user history conversations
Introduce the user's historical conversations and separate them in your answers. For user user2's additional question (complaint handling method), by quoting historical conversations, the background understanding of the user's previous questions is ensured, and the accuracy and coherence of the answer are ensured.
- Specify historical conversations
A user's historical conversations can be explicitly specified to provide more personalized and granular responses. For example, when user2 inquires about headphone patent issues, the assistant provides relevant legal compliance answers based on the previous consultation content "Is the promotional content of the headset compliant?" and by introducing historical conversation data to ensure the pertinence and hierarchy of the answer, avoid repetitive answers, and strengthen the problem-solving path through suggestions such as "supplementary patent information".