Chapter 1: Understanding the Principles of RAG — Making Retrieval-Augmented Generation No Longer a Black Box
The article first introduces the basics of large models, including their definition, working principles, and main challenges. It then discusses typical application scenarios and their limitations. After that, it explains the rise of RAG technology and how external knowledge bases can enhance large-model capabilities. The article also describes the RAG workflow, core components, functions, major types, and common variants. Finally, it gives a short preview of the following chapters to help readers form a clear overall framework.
With this structured introduction, the article provides a solid technical foundation and encourages further exploration of large models and RAG.
Basic Concepts of Large Models
Popular models such as DeepSeek and GPT belong to LLMs (Large Language Models). An LLM is a type of model designed to process large amounts of text, including books, articles, and conversations, and learn the statistical patterns that support language understanding and generation.
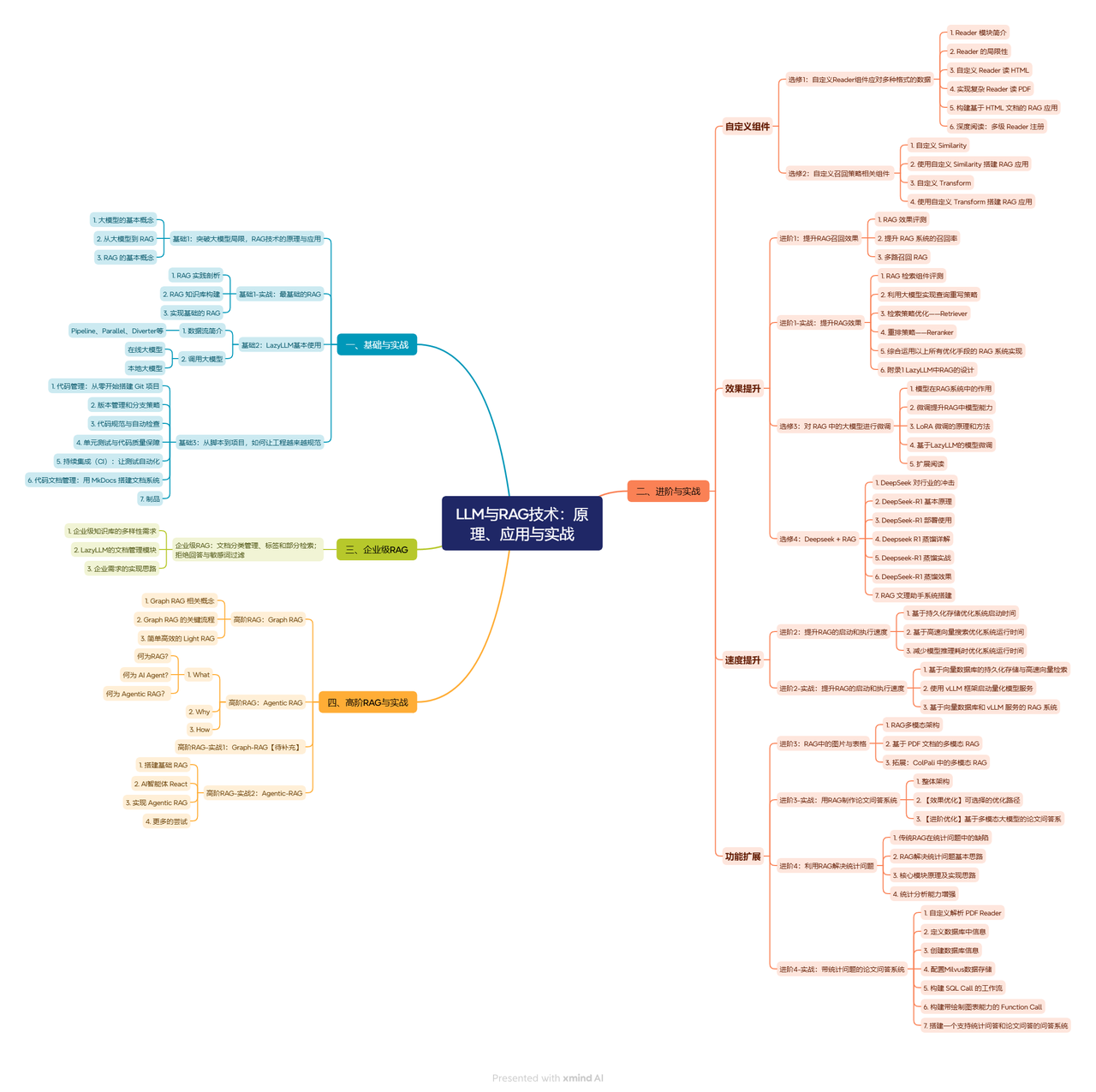
LLMs can capture semantics, context, and basic logical relationships across text. They can continue a story based on a prompt, generate coherent content, and answer questions using the knowledge learned during training. In many scenarios, this process works similarly to a search engine. The model identifies information that is relevant to a user query and produces a concise or insightful response, as shown in the demo video.
Although LLMs are powerful, they are not perfect. They may provide answers that are incomplete or inaccurate, especially when handling complex tasks. As model architectures improve and training data grows, these systems continue to become more capable and more reliable in real-world applications.
A simple example of a model conversation is shown above. In the following sections, we will take a closer look at the core concepts and mechanisms behind large models to help you build a clearer understanding of how these systems work and why they are so powerful.
1. Definition and Key Characteristics
- Definition
A large model is an AI system built on deep learning. It is trained on large collections of text and learns grammar, semantics, and contextual relationships. This enables the model to represent natural language effectively and generate human-like text. With these capabilities, an LLM can perform tasks such as text generation, question answering, and translation.
- Characteristics
Large models typically contain billions or even trillions of parameters. This scale allows them to capture complex language structures and subtle variations in text. They also demonstrate strong capabilities in text generation, comprehension, and basic reasoning.
2. The Nature of Large Models
Generative vs. Discriminative Models
In machine learning, models are often described as either discriminative models or generative models. They differ in objectives and methods. The following analogy offers an intuitive explanation.
Discriminative Model: The Food Judge
Imagine you are a judge in a cooking competition. Your task is to determine whether a dish was prepared by a top chef. You do not need to know the full cooking process. Instead, you evaluate the dish based on characteristics such as taste, appearance, and texture. A discriminative model works in a similar way:
-
Input: Features of the dish such as color, aroma, and texture
-
Output: A decision on whether it was prepared by a top chef or an ordinary chef
-
Process: The model learns to distinguish top-quality dishes from ordinary ones without learning how to cook them
Discriminative models focus on classification and prediction. They excel at identifying patterns and making accurate decisions, which makes them effective for tasks such as spam filtering and image classification. However, they do not generate new data and cannot model how the data itself is produced.
Generative Model: The Recipe Creator
Now imagine you are a chef trying to recreate a top chef’s dish or design a new one. You need to understand ingredients, techniques, and cooking methods so that you can produce a similar or improved dish. A generative model follows this idea:
-
Input: Information about existing dishes such as ingredients and preparation steps
-
Output: A recipe that can be used to produce a comparable dish
-
Process: The model learns from many examples, understands how dishes are composed, and uses that knowledge to create new outputs
Compared with discriminative models, generative models can both identify patterns and produce new data. This makes them suitable for tasks such as text generation and image synthesis. However, they often require very large datasets and substantial computational resources.
Key Differences and Trade-offs
Discriminative models are similar to food judges. They learn to classify and predict outcomes based on observed data, offering clarity and precision but lacking creative ability. Generative models are similar to recipe creators. They can recognize patterns and also create new outputs, allowing them to generalize beyond the training data. Generative modeling is fundamental to modern large models, but it also introduces limitations such as hallucination. Techniques like RAG are designed to mitigate these issues.
Scale of Data and Parameters
Scale is a defining feature of large models. Models with more than one billion parameters are generally considered large. Their training data must also be extensive to reduce the risk of overfitting. For example, GPT-4 is estimated to contain more than 100 trillion parameters, which is hundreds of times larger than GPT-3 with 175 billion parameters. This expanded capacity enables GPT-4 to better understand and generate text across a wide range of tasks.
3. Principles and Architecture
How Large Models Work
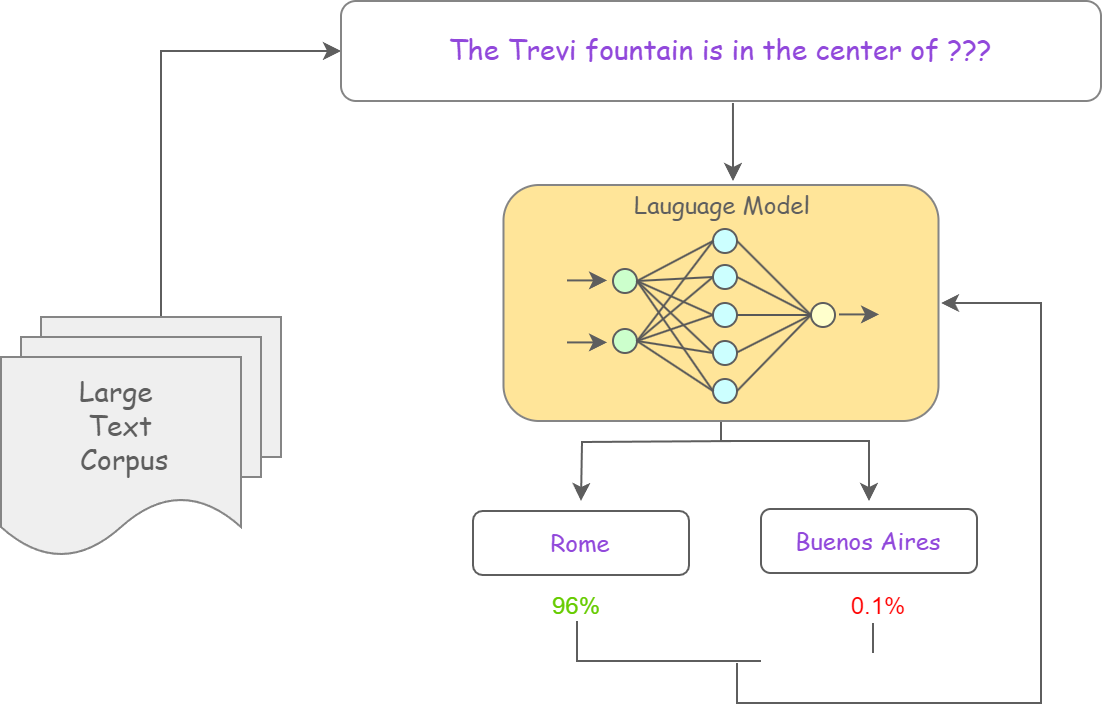
Large models are trained on large collections of text and learn the statistical patterns and regularities of language. During training, the model predicts the probability distribution of the next word or character based on the current context and continuously updates its parameters to minimize prediction error. Over time, this process allows the model to learn grammar, semantic relationships, and contextual dependencies, so it can generate coherent and logically consistent text. These capabilities enable large models to understand and produce natural language and to handle a wide range of complex language tasks.
Model architecture
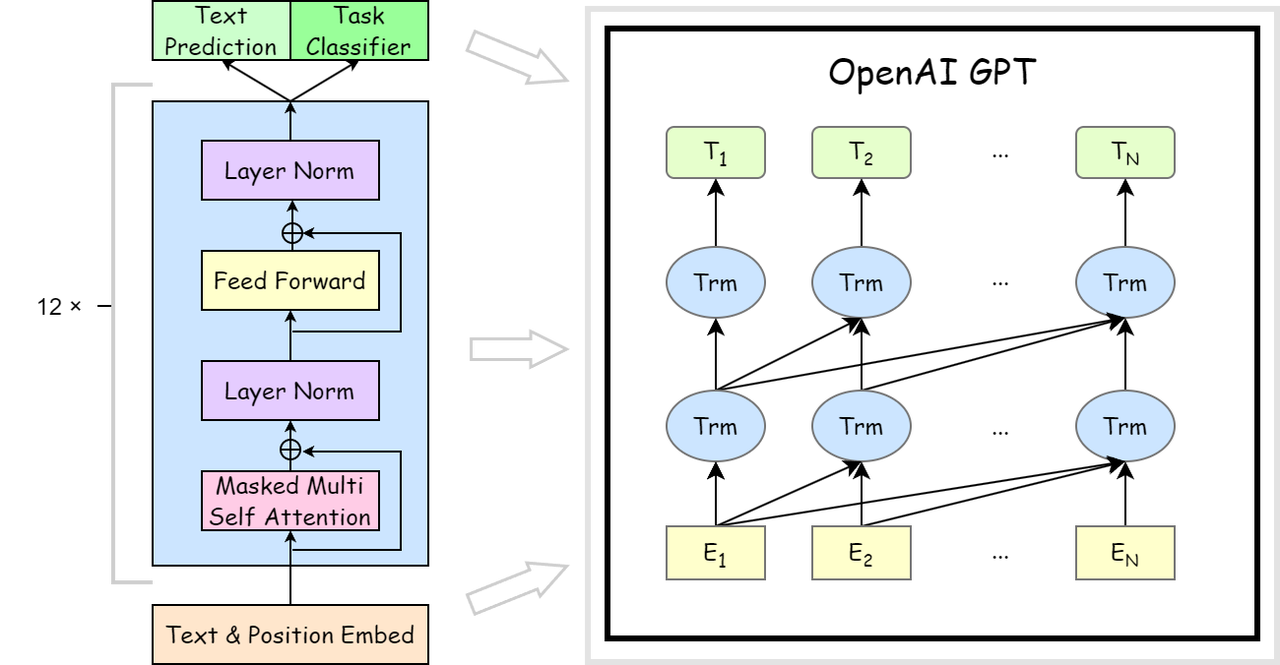
Although the architecture of large models can be complex, it is often described in terms of three main parts: an input layer, a core processing layer, and an output layer. Most mainstream large models today use a decoder-only architecture, such as the GPT family (the architecture of GPT-1 is shown in the figure below). These models are built on the Transformer architecture and use self-attention to process input sequences, capture long-range dependencies, and generate text. BERT also uses a Transformer architecture and pre-training techniques, but it is an encoder-only model designed primarily for understanding tasks rather than large-scale text generation, so it is usually not classified as a large generative model in the strict sense.
-
Input layer: Receives user input text, converts it into token embeddings, and adds positional encodings so the model can interpret the order of tokens in the sequence.
-
Core processing layer: Primarily consists of a Transformer stack, including self-attention and feed-forward networks (FFNs). This layer performs deep processing of the input, captures contextual information, and produces richer representations.
-
Output layer: Maps the processed representations to concrete text outputs, typically through a softmax layer that predicts the next token step by step until the final text is generated.
-
Application scenarios
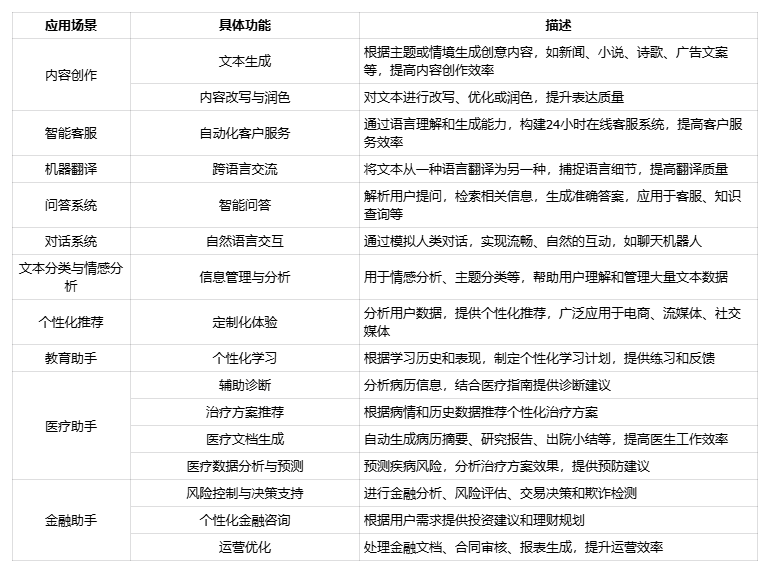
Thanks to their strong natural language processing capabilities, large models are useful in many domains. They can be used for text generation, rewriting, and polishing, as well as for language understanding tasks such as customer support, machine translation, and question answering. In addition, large models are increasingly applied in areas like recommendation systems, education, healthcare, and finance, for example in assisting diagnosis, automating customer service, and supporting financial analysis. As the technology continues to develop, the range of application scenarios for large models will keep expanding and will enable more efficient and intelligent solutions across industries. For further reading, see: Top 10 application scenarios of large models .
In the demo video below, you can see that in a chat-style interface users can ask the AI to select stocks, generate slides, write code, read documents, and more. Large models are already making many day-to-day tasks more convenient.
From large models to RAG
1. Limitations and challenges of large models
Although large models are very capable, they still have clear limitations and face several challenges. Take Doubao as an example. In the chat window, we ask an aeronautics-related question: “What are the main types of flutter?” The question comes from the document 《☆公开☆飞机原理与构造.pdf》, and the standard answer is “bending–torsion flutter of the wing and bending flutter of the aileron.” Without uploading the document, the model’s answer is broad and does not match the correct technical answer. After the file is uploaded and we ask the same question again, the model can now use the content of the document to return the exact correct answer. This illustrates that large models have limitations when dealing with specialized and domain-specific knowledge, especially when deeper technical accuracy is required.
In real-world applications, there are usually many documents, but the context window of a model is limited. RAG addresses this by first retrieving relevant information and then feeding it to the model as external context. Before we examine the benefits of RAG in detail, it is useful to understand the main challenges large models face.
Despite their strong performance across many domains, large models still have important limitations. These issues are closely related to data quality, technical and performance constraints, system integration, and ethical and legal considerations. For a broader overview, see: Limitations and summary of GPT-4.

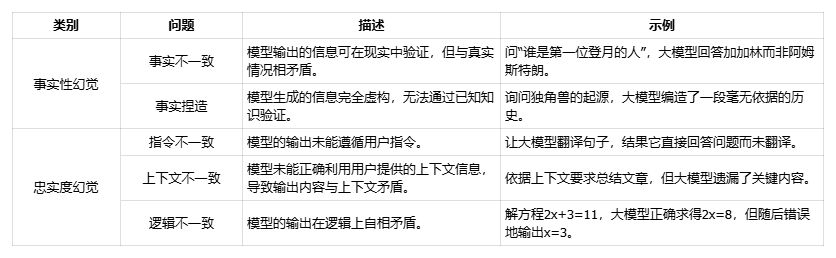
Hallucination is one of the most significant challenges for large models. Hallucinations occur when the model produces content that is factually incorrect, logically inconsistent, or not aligned with user instructions. This often stems from limitations in training data, incomplete context understanding, or weaknesses in the model’s reasoning ability. Hallucinations are commonly discussed in two broad categories: factuality hallucination and faithfulness hallucination.
2. How RAG addresses the limitations of large models
To mitigate issues such as heavy dependence on training data and severe hallucinations, Retrieval-Augmented Generation (RAG) introduces an external knowledge base into the generation process. Instead of relying only on the model’s internal parameters, the system retrieves relevant information and uses it during generation. This helps ground answers in real data, reduces hallucinations, and improves the accuracy of responses. With RAG, large models become more stable and reliable in enterprise and domain-specific scenarios, such as internal knowledge assistants or specialized expert systems. In the following sections, we will examine the basic principles and applications of RAG in more detail.
We can think about the relationship between large models and RAG from several angles. One useful analogy is to imagine a student taking an exam. The large model is like the student, who has acquired knowledge through regular study and can handle many standard questions. However, when the exam includes advanced or cutting-edge problems, the student’s existing knowledge may not be enough. RAG plays the role of a “magic reference book” that the student can consult during the exam. It contains a wide range of up-to-date and niche information and can be updated continuously. When facing a difficult question, the student consults the book, combines it with their own understanding, and produces a more accurate answer.
Under this analogy, the relationship looks like this:
-
Large model (student): Has a certain base of knowledge and problem-solving ability, but that knowledge is limited to what was learned during training. For complex or very new questions, this may not be sufficient.
-
RAG (the “magic” reference book): Provides an external source of knowledge that can be updated and expanded. The large model can query this resource when needed to go beyond its own internal knowledge and access additional information.
When the model encounters a challenging question or needs the latest information, RAG retrieves relevant content from external databases or knowledge bases and passes it to the model. The model then combines this external information with its own learned representations to generate a more accurate and trustworthy answer. Just as a student can perform better with a reference book during an exam, a large model augmented with RAG can achieve significantly better results on knowledge-intensive tasks.
Based on the generative nature and large scale of LLMs, and their close relationship with Retrieval-Augmented Generation, we can summarize the motivation for using RAG from several perspectives:

Combining RAG with large models not only improves accuracy and reliability for knowledge-intensive tasks, but also helps the system work with up-to-date information while enforcing stronger data control and security. This reflects a progression from core modeling techniques, to applied methods, and finally to production systems. In the next sections, we will introduce RAG’s core concepts, workflow, and common variants in more detail.
Basic concepts of RAG
1. Basic workflow of RAG
RAG (Retrieval-Augmented Generation) is a technique that combines information retrieval and text generation to improve the accuracy and usefulness of large language models. Before generating a response, the system retrieves relevant information from an external knowledge base. By incorporating this retrieved information, RAG helps the model answer questions using the most relevant and up-to-date data, which reduces hallucinations and improves both the quality and timeliness of answers.
Online phase
We begin with the key part of RAG in practice: how the system works in the online phase.
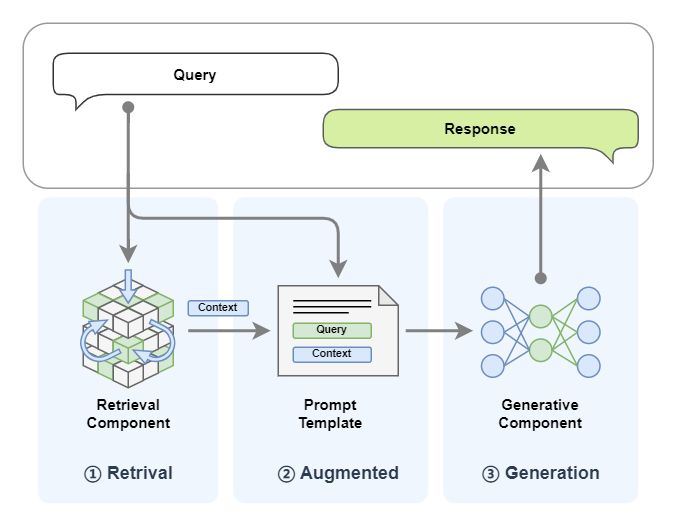
① Retrieval
After the user submits a query, the system searches an external knowledge base or vector database for relevant content. Common techniques include semantic search, BM25, dense retrieval (DPR), and embedding-based retrieval to find the most relevant document chunks.
② Augmented
The retrieved text is then added as extra context and sent to the large model together with the original user query. This stage depends heavily on prompt design so that the model makes effective use of the retrieved information instead of relying only on its internal knowledge.
③ Generation
The large model combines the retrieved context with its pre-trained knowledge to generate the final response. This may involve restructuring, summarizing, or fusing the retrieved content to ensure that the answer is coherent, accurate, and easy to read.
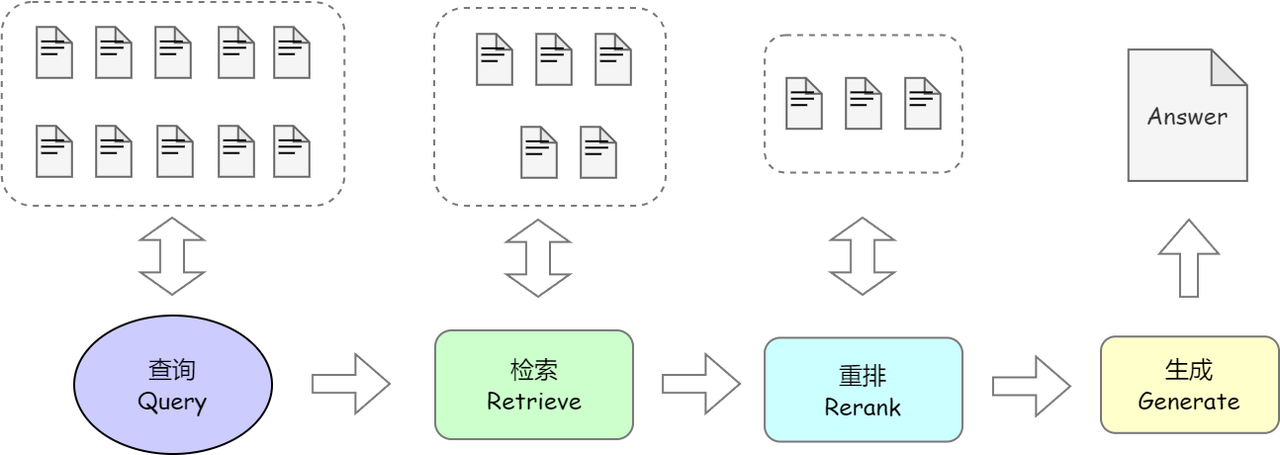
The diagram shows a typical knowledge-base question-answering workflow. The knowledge base contains 10 chunks. In the retrieval step, the system first recalls 5 relevant chunks. After re-ranking, it selects the top 3, which are then passed to the model to generate the final answer. This illustrates the core idea of Retrieval-Augmented Generation: retrieve relevant knowledge first, incorporate it into the prompt, and let the model generate an answer based on that enriched context. Compared with relying solely on the model, RAG combines “retrieval + generation,” uses a vector database to efficiently recall knowledge, and leverages the model for answer generation. This reduces hallucinations, improves knowledge freshness, and lowers the need for frequent fine-tuning.
Text parsing
Next, we focus on text parsing. For the online phase of RAG to work smoothly, upstream data must be prepared carefully, and document ingestion and parsing are critical steps. During data collection, text is gathered from documents, databases, APIs, web pages, and other sources to build a rich knowledge base. These documents often appear in various formats such as PDF, Word, Excel, and PowerPoint, which increases the complexity of data preparation. Robust document reading and parsing methods are therefore essential. The figure below shows a simple example of reading and parsing a PDF document, illustrating the overall pipeline.
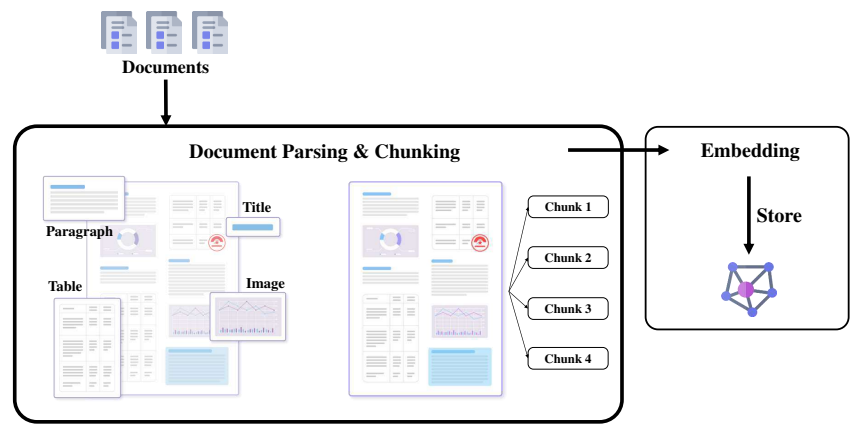
① Document reading and parsing
This is the foundation of the entire pipeline and determines whether the system can reliably extract useful information and convert it into structured data for retrieval. Document reading loads files of various formats into the system for further processing. Common formats include:
-
PDF documents: Tools such as PDFMiner and PyPDF2 can be used to extract text, and OCR techniques can handle scanned documents that contain text as images.
-
Word documents: Libraries such as python-docx can read titles, paragraphs, lists, tables, and other elements and convert them into structured data.
-
Excel and PowerPoint files: Libraries such as openpyxl and python-pptx can be used to read spreadsheet and slide content and extract structured information.
After parsing, document content is converted into a unified JSON representation and further normalized to simplify indexing. To handle the diversity of formats, content complexity, and unstructured data, we can use open source tools such as Apache Tika, integrate OCR, apply deep learning models, and build a unified parsing framework. These approaches help improve both efficiency and accuracy.

② Preprocessing
The collected raw data is then cleaned, deduplicated, chunked, and otherwise preprocessed to remove irrelevant content and noise and to ensure data quality. In this stage, text is also transformed into vector representations so it can be retrieved efficiently. This is typically done using deep learning models or other text encoding methods, such as Word2Vec or BERT, to embed text into a vector space.
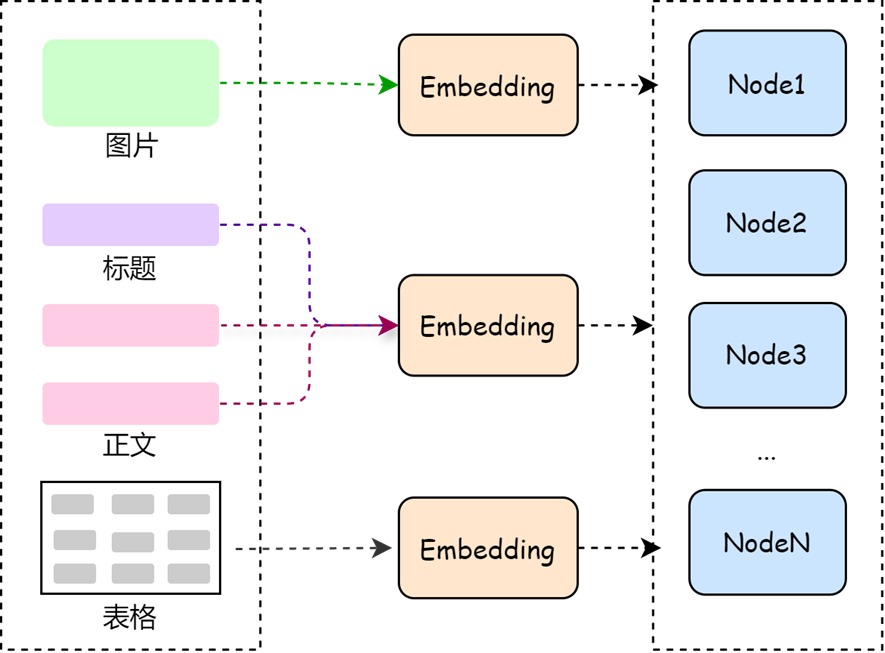
③ Indexing
Vector databases such as FAISS, Weaviate, and Pinecone are then used to index the processed text. These indexes allow the system to quickly locate relevant document chunks for user queries. Parsed document content is stored in the index and updated periodically to ensure that the knowledge base remains fresh.
④ Storage optimization
Finally, the storage layer is optimized to support efficient querying and fast data access. In addition to retrieval performance, storage optimization also considers scalability so the system can continue to operate effectively as data volume grows.
2. Types of RAG
Naive RAG
Naive RAG is the base architecture that combines retrieval and generation to handle tasks such as question answering or content generation.
Workflow
The user submits a query → the retrieval module fetches relevant document chunks from the knowledge base → the query and retrieved context are passed to the generation module → the generation module produces the final response or content based on this combined input.
Advantages
a. Simple and efficient: The modular design is straightforward to implement and debug.
b. Good extensibility: The retrieval and generation modules can be optimized or replaced independently.
Application scenarios
a. Document question answering: Answering user questions based on internal documents or external knowledge bases.
b. Content generation: Producing news, summaries, or other content that needs to incorporate external information.
Retrieve-and-rerank RAG
This is an enhanced version of the basic RAG architecture that introduces a reranking step to select higher-quality context for the generation module. In the reranking stage, a stronger model (often Transformer-based) re-evaluates the initial retrieval results and orders them by relevance to the query, so the model sees the most useful content.
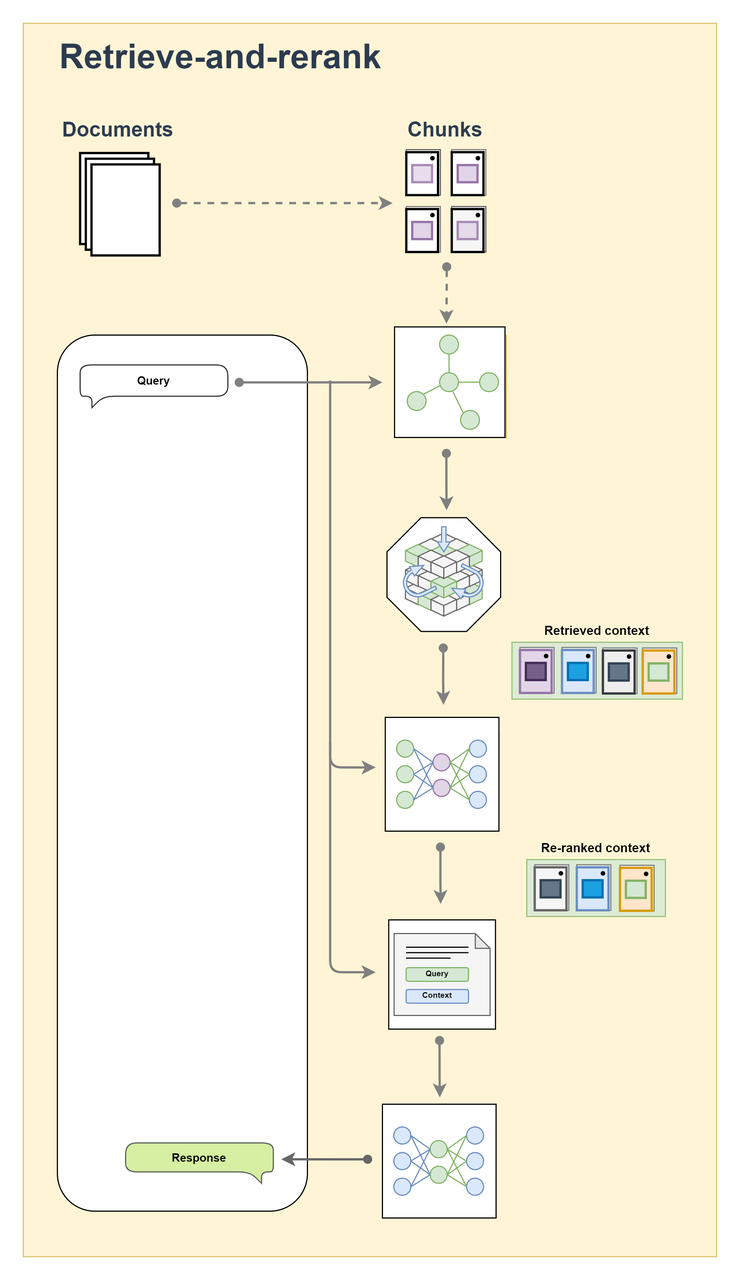
Workflow
The user submits a query → the retrieval module performs an initial, coarse-grained vector search → the reranker reorders the retrieved documents and filters out the most relevant ones → the generation module uses this curated context to generate the final answer.
Advantages
a. Higher retrieval precision: Initial retrieval is fast but approximate; reranking provides more accurate selection of relevant documents.
b. Fewer generation errors: High-quality context reduces the chance that the model will generate answers based on irrelevant or incorrect information.
c. Better handling of long-tail queries: For rare or complex queries, reranking helps refine the results and improve relevance.
Application scenarios
a. Recommendation systems: Reranking can significantly improve the relevance of final recommendations. b. Technical support: Selecting the most relevant support documents to reduce the error rate of generated answers.
Multimodal RAG
Multimodal RAG extends the Naive RAG architecture to support multiple data modalities.
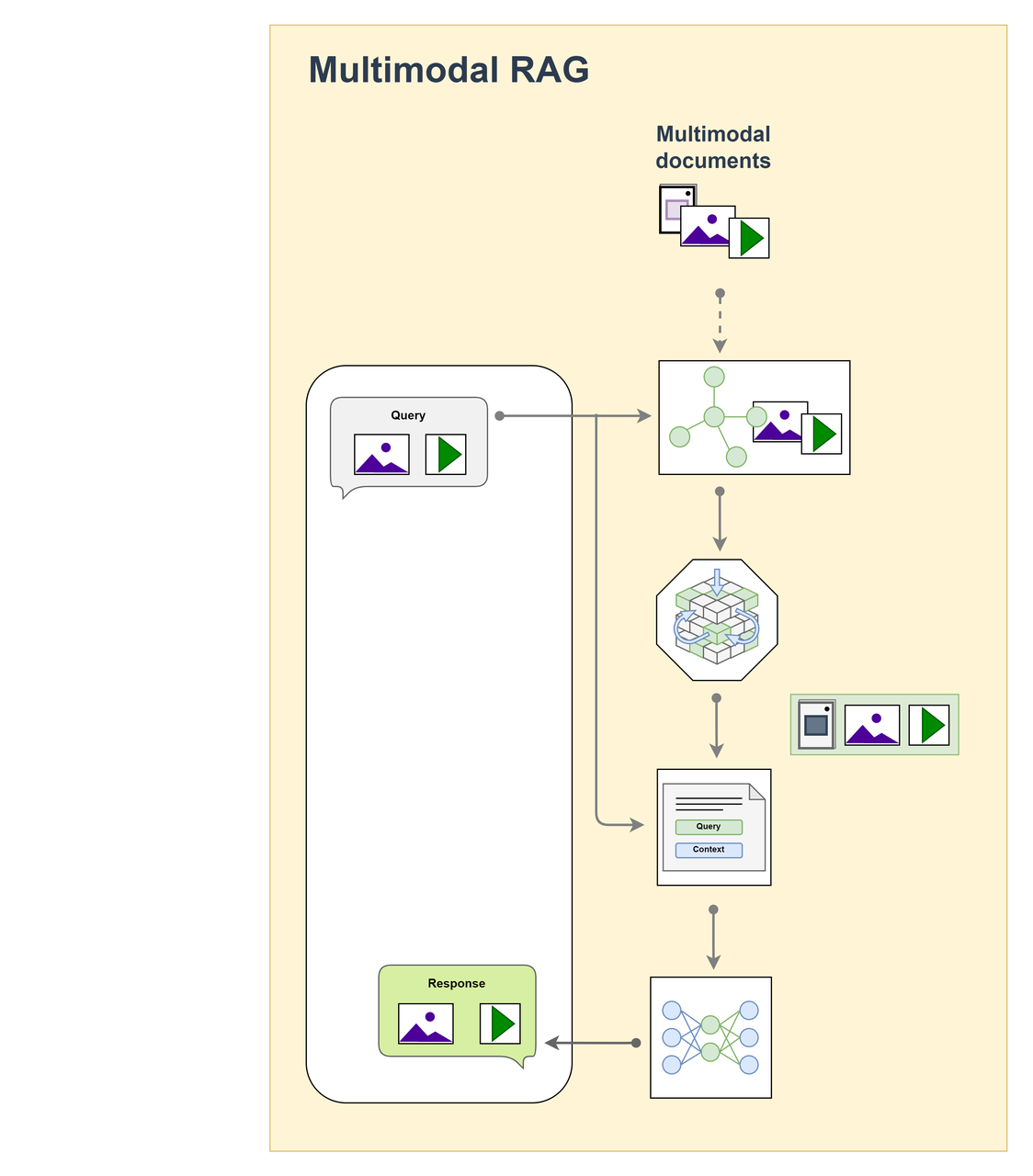
Workflow
The user input can be text or another modality such as an image → the multimodal retrieval module finds multimodal context relevant to the input → the retrieved context is passed to the generation module → the model generates a multimodal response or text that makes use of the combined context.
Advantages
a. Support for multiple input types: In addition to text, the system can process images, videos, and other modalities.
b. Stronger contextual understanding: Combining text and non-text modalities leads to richer and more accurate outputs.
Application scenarios
a. Medical diagnosis: Combining medical text and imaging data to generate diagnostic reports or suggestions.
b. Content generation: Extracting key information from videos or audio and generating summaries or analytical reports.
c. Image captioning: Generating natural language descriptions for images for use in education or assistive tools.
Graph RAG
Graph RAG extends the base RAG architecture by integrating a graph database to better model relationships between concepts and documents.
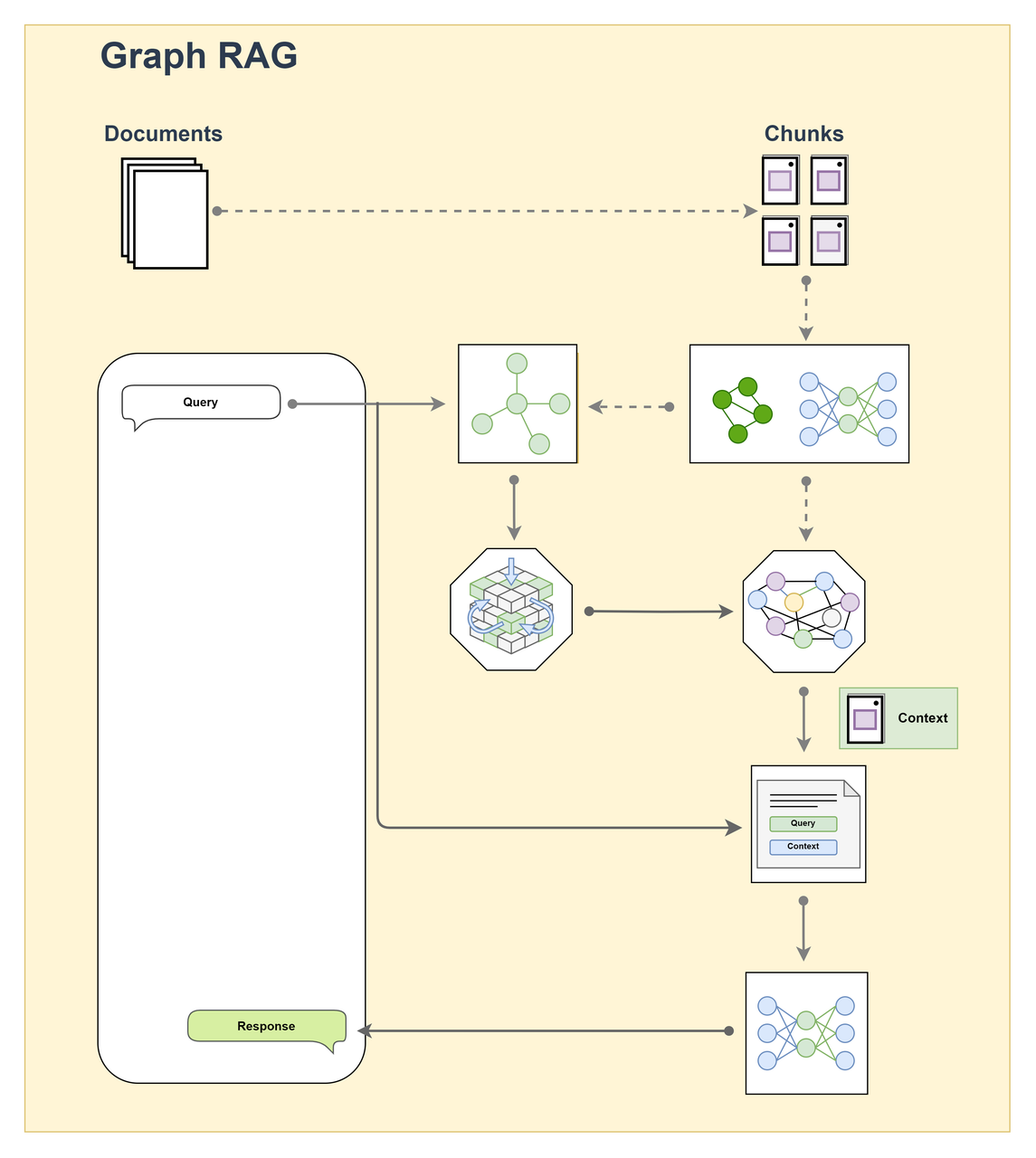
Workflow
Knowledge modeling (extracting entities, relations, and text from a corpus and building a graph) → user query (converting the query into a graph query or structured form) → retrieving a subgraph that is relevant to the query → context expansion (converting the subgraph into textual context and passing it to the generation module) → content generation.
Advantages
a. Rich relational understanding: The graph structure captures complex relationships between documents and knowledge points, such as hierarchy and causality.
b. More precise context expansion: Graph databases can provide more relevant context than vector similarity alone.
c. Enhanced reasoning: Structured graph data supports multi-hop reasoning, such as following several linked entities.
d. Dynamic updates: Graph databases can be updated incrementally, making it easier to maintain relationships as the knowledge base evolves.
Application scenarios
a. Complex question answering and reasoning: Tasks that require cross-document or cross-entity reasoning, such as legal QA or scientific literature analysis.
b. Knowledge management: Managing and querying large collections of related documents or research outputs in enterprises and research institutions.
Hybrid RAG
Hybrid RAG combines multiple retrieval strategies and generation approaches to improve both coverage and accuracy.
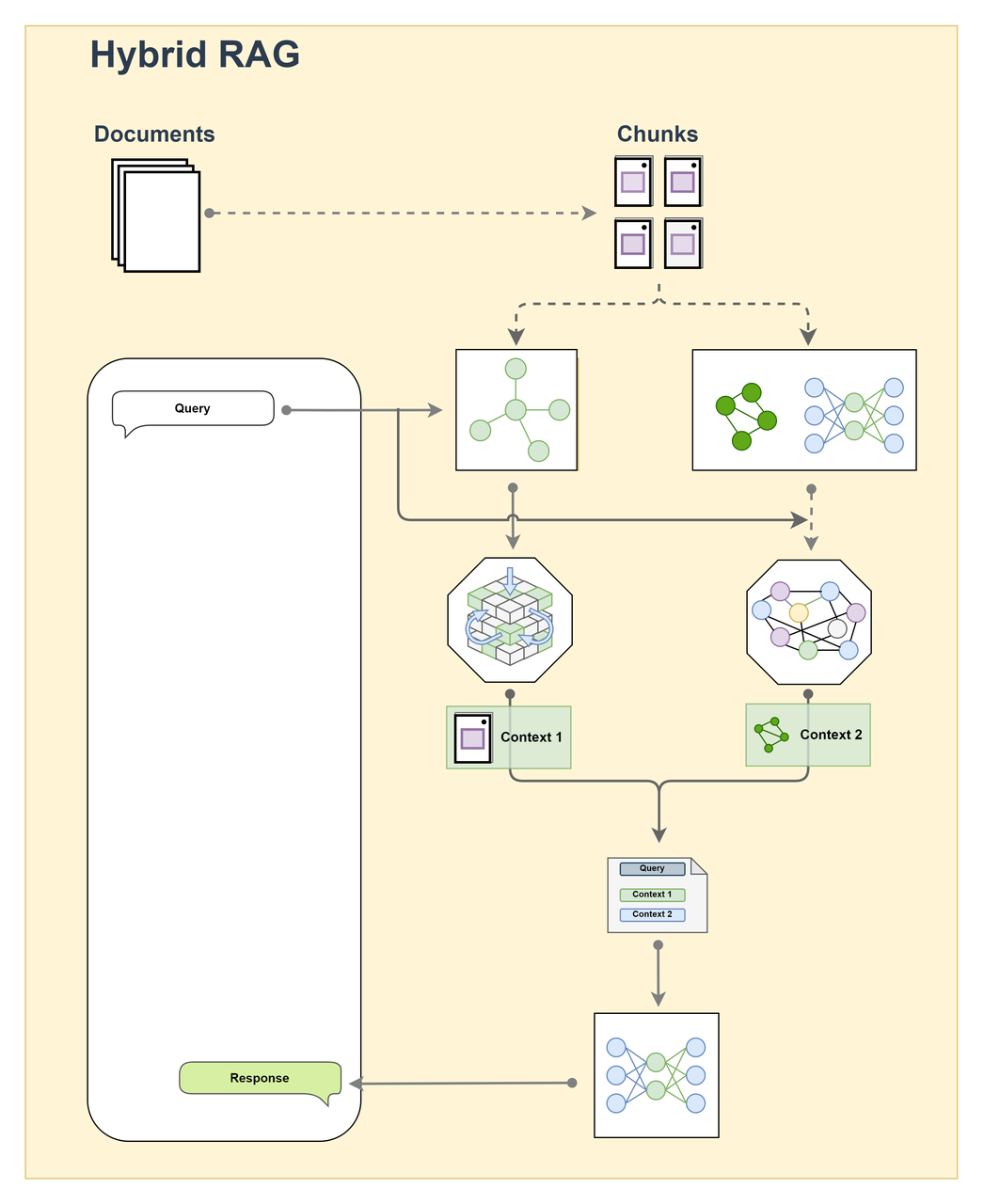
Workflow
Input processing (preprocessing the user query) → combined vector and graph retrieval → fusion of results from different retrieval systems → construction of an augmented prompt that integrates the query and retrieved context → content generation.
Advantages
a. High retrieval coverage: Combining vector retrieval with graph retrieval improves both recall and precision.
b. Stronger contextual connections: Integrating results from different systems yields a deeper understanding of entities and their contexts.
c. Dynamic reasoning: Knowledge graphs can be updated over time, allowing the system to adapt to new information and support dynamic reasoning.
Application scenarios
a. Question answering: Hybrid RAG can power QA systems that retrieve accurate information and generate detailed answers, suitable for help centers, customer support, and similar scenarios.
b. Dialogue systems: It can generate more natural and contextually relevant replies, improving user experience in chatbots and virtual assistants.
c. Document generation: It can produce structured, content-rich documents using both retrieved information and graph-structured knowledge, useful for reports and long-form content.
d. Content recommendation: By analyzing user interests and preferences, it can retrieve and generate personalized recommendations, such as news or product suggestions.
e. Complex question answering: For tasks that require cross-document or cross-entity reasoning, Hybrid RAG can provide accurate answers while maintaining conversational fluency.
Agentic RAG
Agentic RAG is a more advanced RAG architecture that introduces an AI agent as a router. The agent analyzes user queries and dynamically selects the most appropriate processing path or module. This design is especially useful in complex, multi-task scenarios where different queries require different data sources or processing logic.
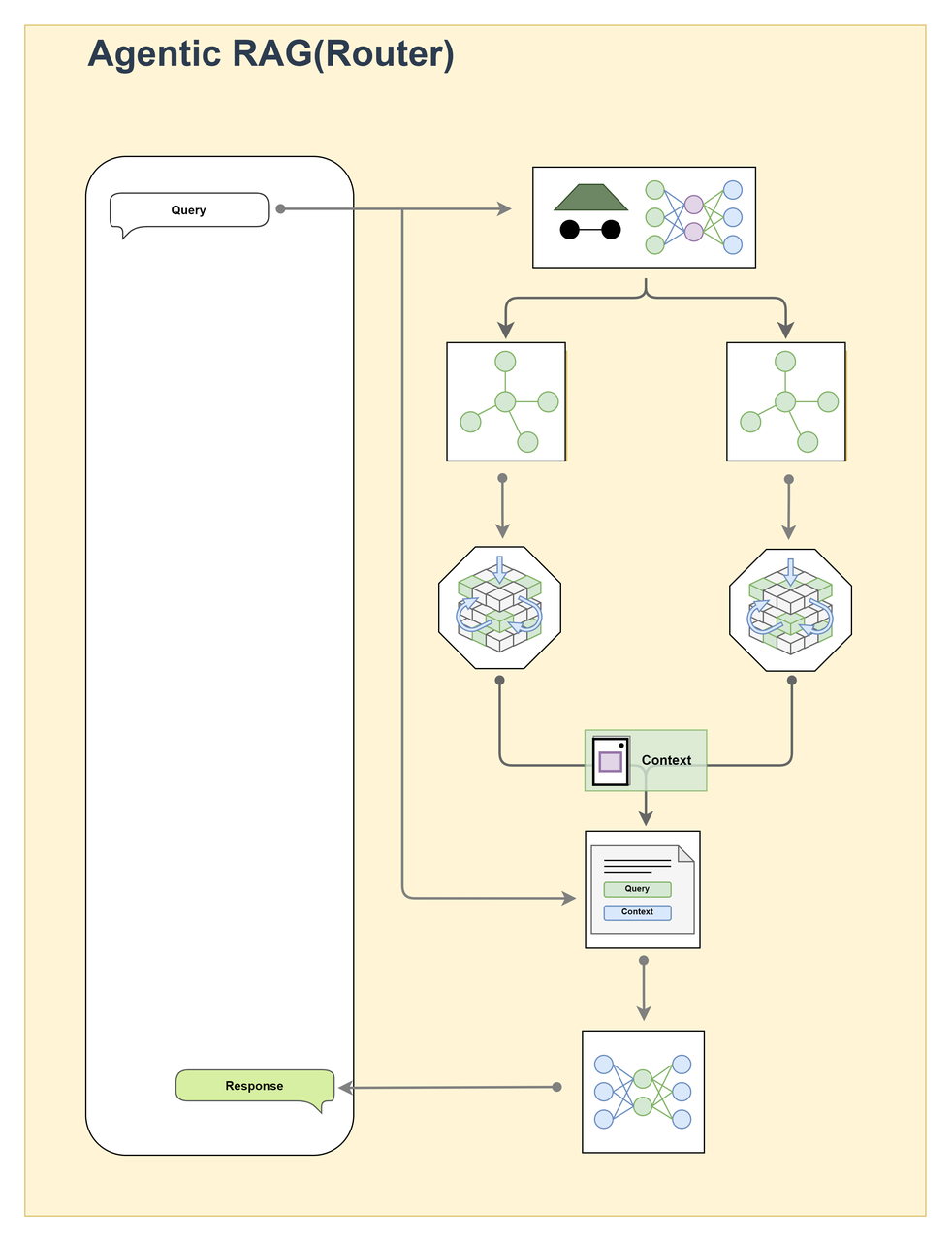
Workflow
The user submits a question or task description → the router analyzes the intent and modality of the query → the agent selects and invokes appropriate modules (such as text retrieval, image retrieval, or multimodal retrieval) → the system generates the final content.
Advantages
a. Query analysis and intelligent reformulation: Agentic RAG can refine ambiguous or complex queries into more precise and retrievable forms and decide when additional data sources are needed.
b. Multi-source retrieval: It can flexibly retrieve information from multiple sources, including user-specific data, internal documents, and external APIs, breaking down data silos.
c. Dynamic answer optimization: Instead of returning a single static answer, the agent can iterate, generate multiple candidate answers, evaluate them, and, if needed, perform further retrieval or adjust the generation strategy.
Application scenarios
a. Medical decision support: Dynamically calling image-analysis modules, literature retrieval, or diagnostic generators.
b. Educational content generation: Selecting appropriate materials and generating explanations tailored to student questions.
c. Automated workflows: Handling complex queries by calling external tools such as calculators, translators, or code executors.
Agentic RAG Multi-Agent
Agentic RAG Multi-Agent is an architecture in which multiple specialized agents work together. Each agent can call different tools, such as vector search, web search, Slack, Gmail, and more, to handle tasks in complex, multi-source data environments.
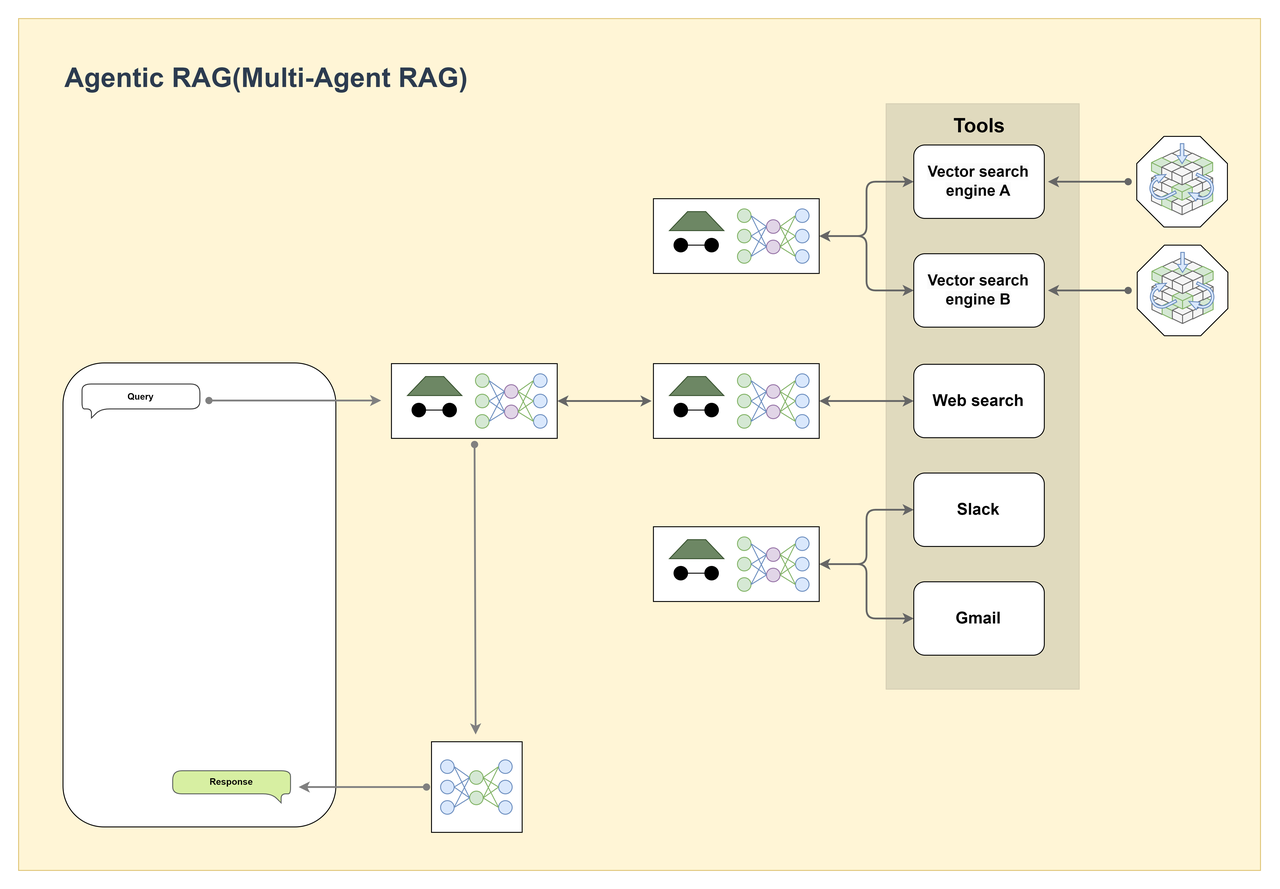
Workflow
The user submits a complex request → a coordinator agent decomposes the request into sub-tasks → the coordinator dispatches sub-tasks to specialized agents, which can run in parallel based on priority → each agent calls the appropriate tools or APIs and returns results → the coordinator aggregates all results and produces a final response for the user.
Advantages
a. Modular design: Each agent operates independently, which simplifies extension and optimization.
b. Parallel multi-task processing: Multiple agents can run concurrently, significantly improving efficiency for complex tasks.
c. Broad tool integration: Agents can call a wide range of tools and APIs, covering retrieval, generation, and task execution end to end.
d. Dynamic task adaptation: The coordinator can adjust execution paths and agent ordering based on the task.
e. Complex task automation: Multi-step workflows across tools and data sources can be automated, from data retrieval to report generation and notifications.
f. Improved accuracy and reliability: Agents can evaluate data quality during retrieval and perform follow-up checks after generation.
g. Good scalability and flexibility: The modular architecture makes it easy to integrate new tools and data sources as requirements grow.
Application scenarios
a. Real-time data analysis: Collecting real-time data from the web and internal databases and generating trend reports.
b. Complex customer support: Combining FAQ retrieval, web search, and live tool calls to provide high-quality support.
c. Content creation and distribution: Retrieving materials from vector databases, generating articles or reports, and distributing them via email or content management systems.
Outline of upcoming tutorials
In this section, we examined the limitations of large models and how RAG helps overcome them by combining retrieval and generation. RAG allows systems to dynamically access new knowledge and incorporate it into the generation process, which significantly improves practical usefulness and accuracy. However, this is only the starting point for RAG. In the upcoming tutorials, we will move into hands-on practice, beginning with a basic RAG implementation and then exploring how to improve retrieval quality, optimize system performance, and handle multimodal data such as images and tables. You will also learn how to build enterprise-scale RAG systems, address complex analytical tasks, and apply advanced techniques such as Graph RAG and Agentic RAG. Whether you are a beginner or a more experienced developer, these materials are intended to help you build more powerful and efficient language-model applications.