语音小助手
本示例展示了如何使用 LazyLLM 快速构建一个具备语音输入与语音输出能力的智能语音助手。
通过本节,您将学习如何构建一个语音交互式智能助手,包括以下要点
- 如何使用 Pipeline 实现多模块的顺序编排与数据流式传递。
- 如何使用 TrainableModule 调用本地语音模型,实现语音与文字的相互转换。
- 如何使用 OnlineChatModule 调用在线大模型,生成自然语言回答。
- 如何使用 WebModule 一键部署语音助手,带来“语音问答”式交互体验。
- 如何设置参数
audio=True进行实时语音输入。
设计思路
首先,要实现一个具备语音输入与语音输出能力的智能助手,我们需要一个能理解自然语言的核心推理模型。这里选择使用 LazyLLM 的 OnlineChatModule 作为语言理解与回答生成的核心引擎。
接着,因为语音助手不仅需要“会思考”,还要“能听懂”和“能说话”,所以我们分别引入两个本地语音模型:
sensevoicesmall:负责将语音识别为文字(Speech-to-Text);ChatTTS-new:负责将模型生成的文字转回语音(Text-to-Speech)。
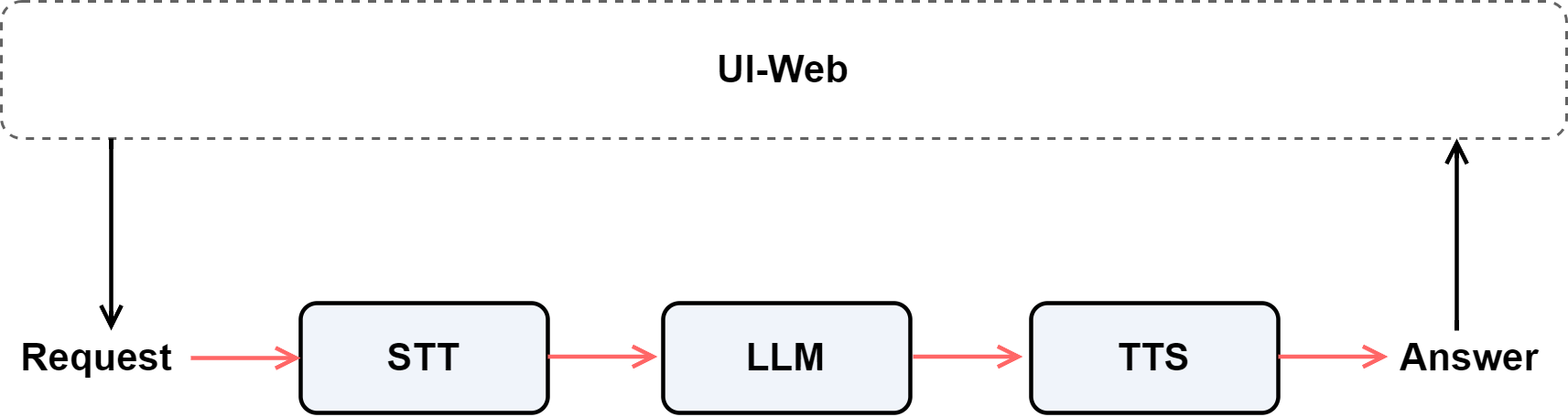
然后,我们使用 Pipeline 将这三个模块(语音识别 → 语言模型 → 语音合成)顺序连接,让数据在模块之间自动流动,形成一个完整的语音交互链路。
最后,通过 WebModule 启动网页端界面,开启 audio=True 选项,让用户能够直接在网页上录制语音提问、听取语音回答,从而实现真正的“语音问答式”智能交互体验。
所以整体设计如下:
环境准备
安装依赖
在使用前,请先执行以下命令安装所需库:
导入依赖包
❗ 注意:在 LazyLLM 中,
Pipeline(大写)与pipeline(小写)是同一个类对象,系统会自动识别并兼容两种写法。
环境变量
在流程中会使用到在线大模型,您需要设置 API 密钥(以 sensenova 为例):
SenseNova API 密钥申请:
- 访问 SenseNova 平台
- 注册并登录您的账户
- 在主页面 → 点击右上角用户图标 → 创建新的『AccessKey 访问密钥』
- 复制生成的 API 密钥并设置到环境变量中
❗ 注意:其他平台的 API_KEY 申请方式参考官方文档。
2. 模型说明
如果需要使用语音识别和语音合成功能,请确保本地或云端环境中已正确配置相关语音模型。本示例中使用的是本地语音模型:
sensevoicesmall:负责语音识别(Speech-to-Text);ChatTTS-new:负责语音合成(Text-to-Speech)。
💡 您也可以根据需要更换模型名称或提供自定义模型路径。
代码实现
以下为完整示例代码,可直接运行:
# 构建语音助手流水线
with pipeline() as ppl:
# 语音转文字
ppl.chat2text = TrainableModule('sensevoicesmall')
# 大模型对话
ppl.llm = OnlineChatModule()
# 文字转语音
ppl.text2chat = TrainableModule('ChatTTS-new')
# 启动网页服务(支持语音输入输出)
WebModule(ppl, port=10236, title='Voice Assistant', audio=True).start().wait()
参数说明
port:指定网页访问端口(可通过浏览器访问 http://127.0.0.1:10236)。title:网页顶部标题,方便展示项目主题。audio:开启语音输入后,Web 界面会自动显示麦克风按钮,实现语音问答交互。
通过 .start().wait() 启动并保持服务运行后,终端会显示本地访问地址(如 http://127.0.0.1:10236)。打开浏览器即可使用语音对话助手,实现“语音问→语音答”的完整交互。
运行效果
下面为示例图:
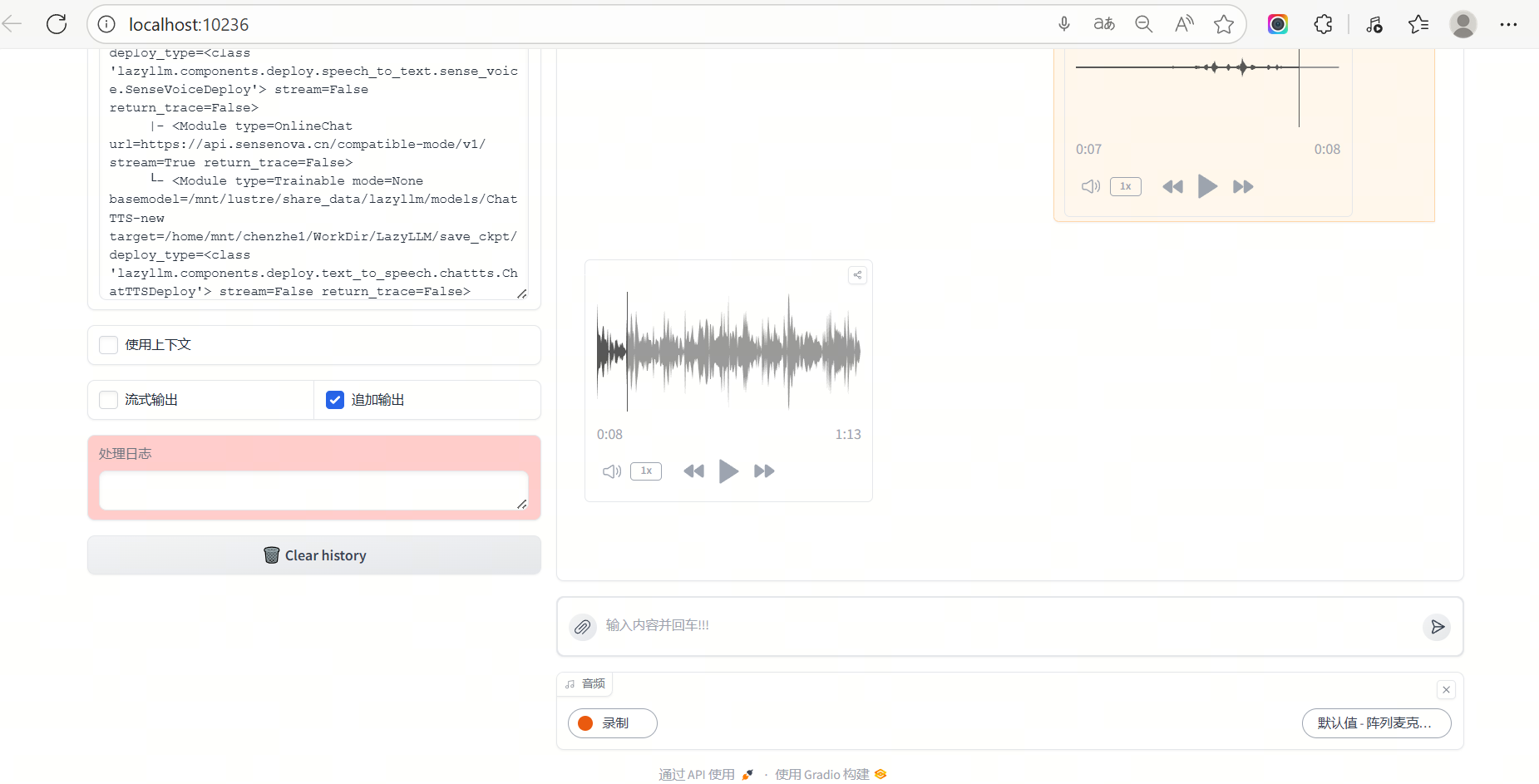
- 打开页面后,点击麦克风图标录制语音;
- 程序会自动识别语音 → 调用大模型生成回答 → 语音播报回复;
- 整个过程在浏览器端实时交互,无需额外配置。