多源数据加载与智能 SQL 查询处理
LazyLLM 不仅能处理自然语言与图像数据,还提供了强大的结构化数据处理能力。通过内置的 SimpleDirectoryReader、SqlManager 和 SqlCall 等工具,开发者可以轻松实现从多源数据文件(如 CSV、Excel等)到数据库查询与智能问答的一体化流程。
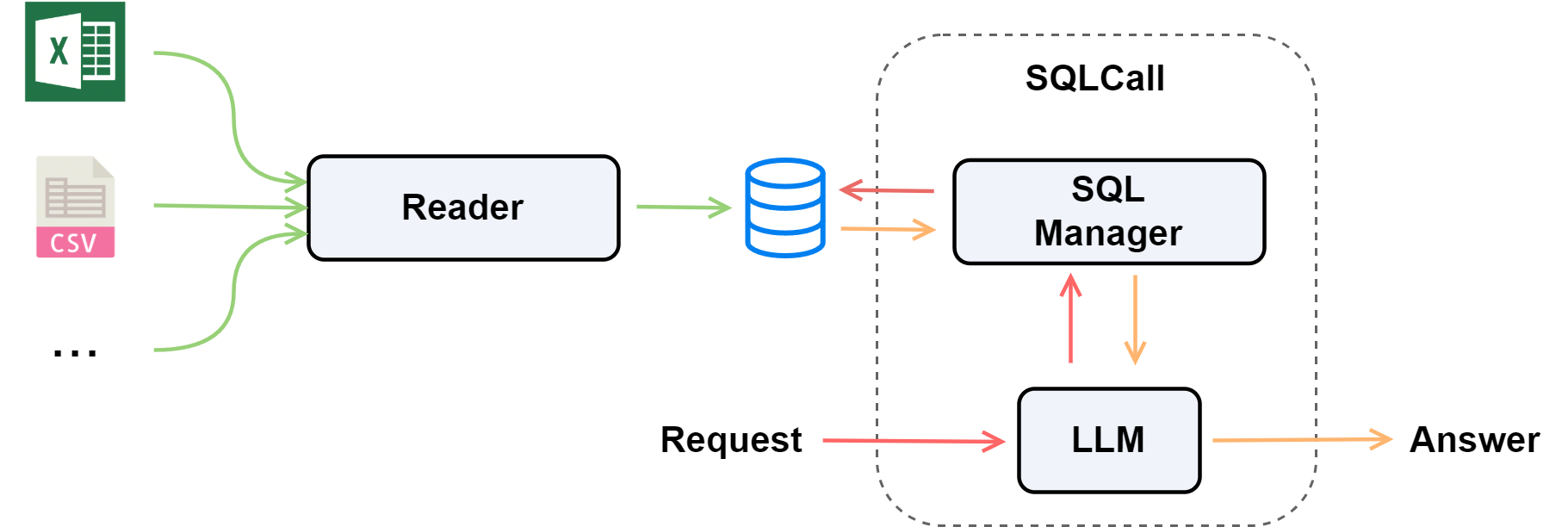
本教程展示如何使用 LazyLLM 实现“从文件到数据库”的完整路径:系统首先自动加载并解析本地多源数据文件,然后初始化数据库,将数据写入其中;最后,结合大语言模型(LLM)执行智能 SQL 查询,实现自然语言到数据库查询的自动映射。
这种能力使得 LazyLLM 能够胜任从商业报表分析、学术数据管理到企业知识图谱构建等多种结构化数据场景。
通过本节您将学习到 LazyLLM 的以下要点:
- 如何使用 SimpleDirectoryReader 自动加载多源数据文件(CSV、Excel)。
- 如何通过 [PandasCSVReader][lazyllm.tools.rag.readers.PandasCSVReader] 自定义文件解析格式。
- 如何使用 SqlManager 快速初始化与管理 SQLite 数据库。
- 如何借助 SqlCall 结合 LLM 执行自然语言驱动的 SQL 查询。
- 如何将数据加载与智能查询整合为可复用的自动化流程。
设计思路
首先要实现多源数据加载,我们需要一个能自动识别文件类型、结构化读取内容的“数据入口”,这里选择使用 SimpleDirectoryReader 作为通用文件加载器,它可以同时处理 CSV、Excel 等多种格式;
然后,为了让这些文件能被统一管理和查询,我们设计了一个自动建表与数据插入模块。该模块会根据文件名匹配目标表(如 students、employees),并通过 SQLite 数据库建立本地结构化数据仓库;
接着,在查询阶段,我们引入 SqlManager 模块,对表结构进行描述与管理,并支持执行标准 SQL 语句,从而在统一接口下进行数据查询与展示;
最后,为了让数据库能够“理解问题、自动生成查询语句”,我们使用 OnlineChatModule 与 SqlCall 组合,让语言模型具备智能 SQL 生成与结果解释能力,实现从自然语言问题到结构化结果的自动转换。
整体流程如下图所示:
环境准备
安装依赖
在使用前,请先执行以下命令安装所需库:
环境变量
在流程中会使用到在线大模型,您需要设置 API 密钥(以 Qwen 为例):
❗ 注意:平台的 API_KEY 申请方式参考官方文档。
导入依赖包
import os
import chardet
import sqlite3
from lazyllm import OnlineChatModule
from lazyllm.tools import SqlManager, SqlCall
from lazyllm.tools.rag.dataReader import SimpleDirectoryReader
from lazyllm.tools.rag.readers import PandasCSVReader
代码实现
准备数据
定义数据文件路径与数据库名称:
❗ 注意:模拟的数据文件可根据后续运行结果结合表结构自行创建。
文件编码检测
在处理 CSV/Excel 文件前,可以先检测文件编码:
def detect_file_encoding(file_path):
with open(file_path, 'rb') as f:
return chardet.detect(f.read())
# 示例
encoding_info = detect_file_encoding(csv_path)
print('文件编码信息:', encoding_info)
多源数据加载
CSV + Excel 一次性加载
使用 SimpleDirectoryReader 可以一次性加载多个文件:
loader = SimpleDirectoryReader(
input_files=[csv_path, xlsx_path],
exclude_hidden=True,
recursive=False
)
# 示例
for doc in loader():
print(doc.text)
运行结果如下:
1001, Linda Zhang, 20, Female, Computer Science, 2022/9/1, 3.85, 60, Active
1002, Kevin Lee, 21, Male, Mechanical Engineering, 2021/9/1, 3.6, 90, Active
1003, Sophia Wang, 19, Female, Economics, 2023/9/1, 3.92, 30, Active
1004, Jason Chen, 22, Male, Electrical Engineering, 2020/9/1, 3.45, 110, Graduated
1005, Emily Liu, 20, Female, Design, 2022/9/1, 3.78, 58, Active
1006, Tom Davis, 23, Male, Business Administration, 2019/9/1, 3.25, 120, Graduated
1 John Doe Engineer
2 Jane Smith Analyst
3 Alice Johnson Manager
4 Bob Lee Engineer
CSV 文件自定义加载
通过 file_extractor 可以自定义 CSV 解析方式,如行列拼接等:
loader = SimpleDirectoryReader(
input_files=[csv_path],
recursive=True,
exclude_hidden=True,
num_files_limit=10,
required_exts=['.csv'],
file_extractor={
'*.csv': PandasCSVReader(
concat_rows=False,
col_joiner=' | ',
row_joiner='\n\n',
pandas_config={'sep': None, 'engine': 'python', 'header': None}
)
}
)
# 示例
for doc in loader():
print(doc.text)
运行结果如下:
StudentID | Name | Age | Gender | Major | Enrollment Date | GPA | Credits | Status
1001 | Linda Zhang | 20 | Female | Computer Science | 2022/9/1 | 3.85 | 60 | Active
1002 | Kevin Lee | 21 | Male | Mechanical Engineering | 2021/9/1 | 3.6 | 90 | Active
1003 | Sophia Wang | 19 | Female | Economics | 2023/9/1 | 3.92 | 30 | Active
1004 | Jason Chen | 22 | Male | Electrical Engineering | 2020/9/1 | 3.45 | 110 | Graduated
1005 | Emily Liu | 20 | Female | Design | 2022/9/1 | 3.78 | 58 | Active
1006 | Tom Davis | 23 | Male | Business Administration | 2019/9/1 | 3.25 | 120 | Graduated
参数详解
input_files:指定要读取的文件路径列表;recursive:是否递归遍历子目录中的文件;exclude_hidden:是否排除隐藏文件;num_files_limit:限制最大读取文件数量;required_exts:指定允许加载的文件类型;file_extractor:定义不同类型文件的解析方式。
💡 提示:这里对
*.csv文件使用PandasCSVReader进行读取。更多详情参考 API 官网。
数据库初始化
创建数据库及表结构,并批量插入 SimpleDirectoryReader 中读取的示例 CSV 和 Excel 数据:
def init_example_db(db_path=db_path, file_paths=[csv_path, xlsx_path]):
'''从多个文件路径批量读取数据(支持 CSV、Excel 等),
使用预定义表结构创建数据库并插入数据。
'''
if file_paths is None:
raise ValueError('请传入 file_paths 参数(文件路径列表)')
os.makedirs(os.path.dirname(db_path), exist_ok=True)
conn = sqlite3.connect(db_path)
cur = conn.cursor()
# === 建表语句 ===
cur.execute('''
CREATE TABLE IF NOT EXISTS employees (
EmployeeId INTEGER PRIMARY KEY,
FirstName TEXT,
LastName TEXT,
Title TEXT
);
''')
cur.execute('''
CREATE TABLE IF NOT EXISTS students (
StudentID INTEGER PRIMARY KEY,
Name TEXT,
Age INTEGER,
Gender TEXT,
Major TEXT,
EnrollmentDate TEXT,
GPA REAL,
Credits INTEGER,
Status TEXT
);
''')
# === 遍历文件并插入数据 ===
for file_path in file_paths:
table_name = os.path.splitext(os.path.basename(file_path))[0].lower()
loader = SimpleDirectoryReader(
input_files=[file_path],
recursive=False,
exclude_hidden=True,
required_exts=['.csv', '.xlsx']
)
docs = loader()
all_rows = []
for doc in docs:
lines = [line.strip() for line in doc.text.strip().split('\n') if line.strip()]
if not lines:
continue
for row in lines:
# 支持逗号分隔或空格分隔
if ',' in row:
values = [v.strip() for v in row.split(',')]
else:
values = [v.strip() for v in row.split()]
all_rows.append(values)
if not all_rows:
continue
# === 匹配表名插入数据 ===
if table_name == 'students':
insert_sql = '''
INSERT OR REPLACE INTO students
(StudentID, Name, Age, Gender, Major, EnrollmentDate, GPA, Credits, Status)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?);
'''
elif table_name == 'employees':
insert_sql = '''
INSERT OR REPLACE INTO employees
(EmployeeId, FirstName, LastName, Title)
VALUES (?, ?, ?, ?);
'''
else:
print(f'⚠️ 未识别的表名:{table_name},跳过文件 {file_path}')
continue
cur.executemany(insert_sql, all_rows)
print(f'✅ 已插入表 {table_name},共 {len(all_rows)} 行。')
conn.commit()
conn.close()
print(f'🎉 数据库初始化完成:{db_path}')
SQL 查询与表结构管理
使用 SqlManager 管理数据库表结构,并执行查询:
def query_database(db_name):
tables_info = {
'tables': [
{
'name': 'employees',
'comment': 'Employee information',
'columns': [
{'name': 'EmployeeId', 'data_type': 'Integer', 'is_primary_key': True},
{'name': 'FirstName', 'data_type': 'String'},
{'name': 'LastName', 'data_type': 'String'},
{'name': 'Title', 'data_type': 'String'}
]
},
{
'name': 'students',
'comment': 'Student records',
'columns': [
{'name': 'StudentID', 'data_type': 'Integer', 'is_primary_key': True},
{'name': 'Name', 'data_type': 'String'},
{'name': 'Age', 'data_type': 'Integer'},
{'name': 'Gender', 'data_type': 'String'},
{'name': 'Major', 'data_type': 'String'},
{'name': 'EnrollmentDate', 'data_type': 'String'},
{'name': 'GPA', 'data_type': 'Float'},
{'name': 'Credits', 'data_type': 'Integer'},
{'name': 'Status', 'data_type': 'String'}
]
}
]
}
sql_manager = SqlManager(
'sqlite', None, None, None, None,
db_name=db_name, tables_info_dict=tables_info
)
print('=== Schema Description ===')
print(sql_manager.desc)
print('=== employees ===')
print(sql_manager.execute_query('SELECT * FROM employees;'))
print('=== students ===')
print(sql_manager.execute_query('SELECT * FROM students;'))
return sql_manager
💡 说明:
SqlManager管理数据库和表信息。对于远程数据库,如 PostgreSQL/MySQL,需要填写 user、password、host 和 port。此处示例为本地数据库,填 None 即可。
如果运行上述代码,运行结果如下所示:
=== Schema Description ===
The tables description is as follows
Table employees
(
EmployeeId INTEGER,
FirstName TEXT,
LastName TEXT,
Title TEXT
);
COMMENT ON TABLE "employees": Employee information
COMMENT ON COLUMN "employees.EmployeeId":
COMMENT ON COLUMN "employees.FirstName":
COMMENT ON COLUMN "employees.LastName":
COMMENT ON COLUMN "employees.Title":
Table students
(
StudentID INTEGER,
Name TEXT,
Age INTEGER,
Gender TEXT,
Major TEXT,
EnrollmentDate TEXT,
GPA REAL,
Credits INTEGER,
Status TEXT
);
COMMENT ON TABLE "students": Student records
COMMENT ON COLUMN "students.StudentID":
COMMENT ON COLUMN "students.Name":
COMMENT ON COLUMN "students.Age":
COMMENT ON COLUMN "students.Gender":
COMMENT ON COLUMN "students.Major":
COMMENT ON COLUMN "students.EnrollmentDate":
COMMENT ON COLUMN "students.GPA":
COMMENT ON COLUMN "students.Credits":
COMMENT ON COLUMN "students.Status":
=== employees ===
[{"EmployeeId": 1, "FirstName": "John", "LastName": "Doe", "Title": "Engineer"}, {"EmployeeId": 2, "FirstName": "Jane", "LastName": "Smith", "Title": "Analyst"}, {"EmployeeId": 3, "FirstName": "Alice", "LastName": "Johnson", "Title": "Manager"}, {"EmployeeId": 4, "FirstName": "Bob", "LastName": "Lee", "Title": "Engineer"}]
=== students ===
[{"StudentID": 1001, "Name": "Linda Zhang", "Age": 20, "Gender": "Female", "Major": "Computer Science", "EnrollmentDate": "2022/9/1", "GPA": 3.85, "Credits": 60, "Status": "Active"}, {"StudentID": 1002, "Name": "Kevin Lee", "Age": 21, "Gender": "Male", "Major": "Mechanical Engineering", "EnrollmentDate": "2021/9/1", "GPA": 3.6, "Credits": 90, "Status": "Active"}, {"StudentID": 1003, "Name": "Sophia Wang", "Age": 19, "Gender": "Female", "Major": "Economics", "EnrollmentDate": "2023/9/1", "GPA": 3.92, "Credits": 30, "Status": "Active"}, {"StudentID": 1004, "Name": "Jason Chen", "Age": 22, "Gender": "Male", "Major": "Electrical Engineering", "EnrollmentDate": "2020/9/1", "GPA": 3.45, "Credits": 110, "Status": "Graduated"}, {"StudentID": 1005, "Name": "Emily Liu", "Age": 20, "Gender": "Female", "Major": "Design", "EnrollmentDate": "2022/9/1", "GPA": 3.78, "Credits": 58, "Status": "Active"}, {"StudentID": 1006, "Name": "Tom Davis", "Age": 23, "Gender": "Male", "Major": "Business Administration", "EnrollmentDate": "2019/9/1", "GPA": 3.25, "Credits": 120, "Status": "Graduated"}]
使用 LLM 进行智能问答
结合 SqlCall 和 OnlineChatModule,可以用自然语言直接提问数据库:
# 初始化数据库
init_example_db()
# SQL 查询
sql_manager = query_database(db_path)
llm = OnlineChatModule()
sql_call = SqlCall(llm=llm, sql_manager=sql_manager, use_llm_for_sql_result=True)
question = 'List all students who have a GPA greater than 3.8.'
answer = sql_call(question)
print('Question:', question)
print('Answer:', answer)
运行结果如下:
Question: List all students who have a GPA greater than 3.8.
Answer: The students who have a GPA greater than 3.8 are:
1. Linda Zhang, Majoring in Computer Science, with a GPA of 3.85.
2. Sophia Wang, Majoring in Economics, with a GPA of 3.92.
完整代码
完整代码如下所示:
点击展开完整代码
import os
import chardet
import sqlite3
from lazyllm import OnlineChatModule
from lazyllm.tools import SqlManager, SqlCall
from lazyllm.tools.rag.dataReader import SimpleDirectoryReader
from lazyllm.tools.rag.readers import PandasCSVReader
csv_path = 'data/students.csv'
xlsx_path = 'data/employees.xlsx'
db_path = 'data/example.db'
def detect_file_encoding(file_path):
with open(file_path, 'rb') as f:
return chardet.detect(f.read())
loader = SimpleDirectoryReader(
input_files=[csv_path, xlsx_path],
exclude_hidden=True,
recursive=False
)
for doc in loader():
print(doc.text)
loader = SimpleDirectoryReader(
input_files=[csv_path],
recursive=True,
exclude_hidden=True,
num_files_limit=10,
required_exts=['.csv'],
file_extractor={
'*.csv': PandasCSVReader(
concat_rows=False,
col_joiner=' | ',
row_joiner='\n\n',
pandas_config={'sep': None, 'engine': 'python', 'header': None}
)
}
)
for doc in loader():
print(doc.text)
def init_example_db(db_path=db_path, file_paths=[csv_path, xlsx_path]):
'''从多个文件路径批量读取数据(支持 CSV、Excel 等),
使用预定义表结构创建数据库并插入数据。
'''
if file_paths is None:
raise ValueError('请传入 file_paths 参数(文件路径列表)')
os.makedirs(os.path.dirname(db_path), exist_ok=True)
conn = sqlite3.connect(db_path)
cur = conn.cursor()
# === 建表语句 ===
cur.execute('''
CREATE TABLE IF NOT EXISTS employees (
EmployeeId INTEGER PRIMARY KEY,
FirstName TEXT,
LastName TEXT,
Title TEXT
);
''')
cur.execute('''
CREATE TABLE IF NOT EXISTS students (
StudentID INTEGER PRIMARY KEY,
Name TEXT,
Age INTEGER,
Gender TEXT,
Major TEXT,
EnrollmentDate TEXT,
GPA REAL,
Credits INTEGER,
Status TEXT
);
''')
# === 遍历文件并插入数据 ===
for file_path in file_paths:
table_name = os.path.splitext(os.path.basename(file_path))[0].lower()
loader = SimpleDirectoryReader(
input_files=[file_path],
recursive=False,
exclude_hidden=True,
required_exts=['.csv', '.xlsx']
)
docs = loader()
all_rows = []
for doc in docs:
lines = [line.strip() for line in doc.text.strip().split('\n') if line.strip()]
if not lines:
continue
for row in lines:
# 支持逗号分隔或空格分隔
if ',' in row:
values = [v.strip() for v in row.split(',')]
else:
values = [v.strip() for v in row.split()]
all_rows.append(values)
if not all_rows:
continue
# === 匹配表名插入数据 ===
if table_name == 'students':
insert_sql = '''
INSERT OR REPLACE INTO students
(StudentID, Name, Age, Gender, Major, EnrollmentDate, GPA, Credits, Status)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?);
'''
elif table_name == 'employees':
insert_sql = '''
INSERT OR REPLACE INTO employees
(EmployeeId, FirstName, LastName, Title)
VALUES (?, ?, ?, ?);
'''
else:
print(f'⚠️ 未识别的表名:{table_name},跳过文件 {file_path}')
continue
cur.executemany(insert_sql, all_rows)
print(f'✅ 已插入表 {table_name},共 {len(all_rows)} 行。')
conn.commit()
conn.close()
print(f'🎉 数据库初始化完成:{db_path}')
def query_database(db_name):
tables_info = {
'tables': [
{
'name': 'employees',
'comment': 'Employee information',
'columns': [
{'name': 'EmployeeId', 'data_type': 'Integer', 'is_primary_key': True},
{'name': 'FirstName', 'data_type': 'String'},
{'name': 'LastName', 'data_type': 'String'},
{'name': 'Title', 'data_type': 'String'}
]
},
{
'name': 'students',
'comment': 'Student records',
'columns': [
{'name': 'StudentID', 'data_type': 'Integer', 'is_primary_key': True},
{'name': 'Name', 'data_type': 'String'},
{'name': 'Age', 'data_type': 'Integer'},
{'name': 'Gender', 'data_type': 'String'},
{'name': 'Major', 'data_type': 'String'},
{'name': 'EnrollmentDate', 'data_type': 'String'},
{'name': 'GPA', 'data_type': 'Float'},
{'name': 'Credits', 'data_type': 'Integer'},
{'name': 'Status', 'data_type': 'String'}
]
}
]
}
sql_manager = SqlManager(
'sqlite', None, None, None, None,
db_name=db_name, tables_info_dict=tables_info
)
print('=== Schema Description ===')
print(sql_manager.desc)
print('=== employees ===')
print(sql_manager.execute_query('SELECT * FROM employees;'))
print('=== students ===')
print(sql_manager.execute_query('SELECT * FROM students;'))
return sql_manager
def ask_llm_question(sql_manager):
llm = OnlineChatModule()
sql_call = SqlCall(llm=llm, sql_manager=sql_manager, use_llm_for_sql_result=True)
question = 'List all students who have a GPA greater than 3.8.'
answer = sql_call(question)
print('Question:', question)
print('Answer:', answer)
if __name__ == '__main__':
init_example_db()
sql_manager = query_database(db_path)
ask_llm_question(sql_manager)
总结
通过本示例,我们展示了如何使用 LazyLLM 构建一个具备多源数据加载与智能 SQL 查询能力的系统。整个流程从数据读取、数据库初始化,到自然语言驱动的查询执行,都只需极少量代码即可完成。
在这里:
SimpleDirectoryReader负责从多个文件源(如 CSV、Excel)中读取数据;SqlManager负责维护数据库结构与执行 SQL 语句;SqlCall则将语言模型与数据库连接起来,使 LLM 能“理解问题”并自动生成查询语句;OnlineChatModule提供了自然语言到 SQL 的智能转换与结果解释。
这种设计使开发者能够轻松实现从文件 → 数据库 → 智能查询的完整闭环,构建可理解自然语言、可直接操作数据库的 AI 数据助手。
想了解更多 LazyLLM 的高级特性与使用案例,请参考 官方文档。