LazyLLM 观测系统
1. 观测的定义和背景
在构建和部署大模型应用时,系统内部的“黑盒”属性往往会给开发和排障带来巨大挑战。可观测性(Observability)的核心目的,是通过收集系统运行时的各种真实信号,帮助开发者随时看清系统的内部状态与运行逻辑。
在传统的简单应用中,排查问题往往只需要关注单点函数的输入输出。但 LazyLLM 面对的通常是高度复杂的交互场景,零散的事件记录已无法还原请求执行的全貌。因此,LazyLLM 引入观测系统,为每一次真实请求建立统一、结构化且可深度分析的执行视图。
1.1 观测系统解决的问题
对于大模型应用而言,真正的挑战通常不在于“是否能够把链路跑通”,而在于“为什么结果不对”“为什么响应特别慢”,或“为什么修改提示词后整体效果退化”。观测系统的核心价值,在于把这些依赖人工经验的排查过程转化为可定位、可比较、可统计的标准流程。
LazyLLM 的观测系统主要解决以下问题:
-
复杂链路的单点诊断与拆解(如 RAG/Agent)
当系统的最终输出不符合预期时,开发者需要明确问题根源。例如在
Retriever -> Reranker -> LLM的 RAG 流程中,观测系统能将结果拆解,帮助判断是“未召回正确知识”还是“模型未能正确利用上下文”;在 Agent 场景中,观测能串联模型输出、工具调用和状态回填,精准定位是决策偏差、错误调用工具还是陷入了无效循环。 -
性能瓶颈的精准定位
一次请求变慢,原因可能来自大模型推理、检索等待,甚至某个控制流节点的异常膨胀。观测系统通过节点级时延瀑布图(Waterfall),将“整体响应慢”直观拆解为“具体哪一层慢”,从而快速锁定性能瓶颈。
-
批量聚合与宏观模式分析
当系统进入真实环境后,观测系统通过结合会话、用户等维度标签,支持对线上数据进行聚合。开发者不仅能排查单次异常,还能分析某一批请求是否存在共同的失败模式或高频错误链路。
-
版本对比与实验回归
在流程改动、Prompt 优化或底层模型切换后,观测系统提供的完整执行证据,可以有效支撑不同版本间的链路回放与效果对比,帮助开发者量化改动带来的实际影响。
1.2 观测的数据范围
为了实现上述诊断能力,LazyLLM 的观测系统记录的是与链路分析强相关的执行事实,强调结构化与统一语义,避免无边界复制带来的数据噪音。观测系统重点捕获以下核心信息:
-
请求上下文与拓扑结构 (Context & Trace Structure)
系统会记录全局上下文(如
trace_id、session_id、request_tags等)以绑定同次请求的跨组件行为。同时,详细记录该请求经过的所有节点以及嵌套的父子调用关系,构建出完整的 Trace 拓扑结构。 -
执行流转数据与状态 (I/O & Execution Status)
精确记录每个节点实际接收的输入(Input)与生成的输出(Output),是否保留完整输入输出内容取决于运行时的 Tracing 配置。同步记录节点的执行状态(成功/失败)及异常栈信息,保障排障链路的完整性。
-
节点语义与扩展配置 (Semantics & Configurations)
为了让观测结果成为“带语义的实体”,系统会为节点标记统一的角色标签(如区分
llm、retriever、rerank、tool或agent)。同时附带记录关键配置属性,如模型名称、Top-K 召回条数、重排分数或控制流决策结果,便于上层分析平台理解节点业务含义。 -
资源用量与性能数据 (Usage & Performance)
记录每个节点的绝对耗时,以及典型的大模型资源消耗(如
prompt_tokens、completion_tokens等),作为后续系统吞吐分析与推理成本核算的重要基础数据。
1.3 为什么使用 Tracing
常见的观测系统实现方案包括日志(Logging)、指标(Metrics)与追踪(Tracing)。虽然三者都服务于系统的监控与诊断,但它们的观测视角与所解决的问题层次存在本质差异:
-
日志(Logging)偏向“离散的局部事件” 日志的优势在于细粒度与即时性,通常用于回答“代码是否执行到了某一行”、“某个分支是否被命中”或“在此处抛出了什么异常”。它是一条条独立的文本流,适合开发调试阶段的单点排查,但在多组件协作时容易失去上下文。
-
指标(Metrics)偏向“宏观的聚合趋势” 指标的优势在于极低的存储成本与直观的统计视图,通常用于回答“系统当前的 QPS 是多少”“P99 响应延迟是否飙升”或“大模型 Token 的总体消耗速率如何”。Metrics 能较快反映系统是否出现异常或性能退化,但无法直接回答“到底是哪一次具体请求、在哪个环节导致了问题”。
-
追踪(Tracing)偏向“统一的请求视图” 在 LazyLLM 这种复杂系统中,Tracing 是唯一能还原整体执行逻辑的手段。它的核心价值在于回答“这次请求途经了哪些节点”、“节点间的父子调用关系如何”、“哪一层真正决定了最终结果”。
在排查问题时,仅靠日志,开发者只能看到“发生过哪些事件”;仅靠指标,开发者只能看到“系统整体表现如何”。因此,LazyLLM 选择将 Tracing 作为观测体系的核心骨架。以 Tracing 为载体,局部日志(如某个工具节点的执行报错)和关键指标(如某次 LLM 调用的耗时与 Token 消耗)都可以挂载到结构化的调用链(Trace)上,从而形成完整的请求视图。
2. LazyLLM观测系统使用指南
LazyLLM 的观测能力不绑定单一后端,观测数据的写入目标由具体的后端配置决定。通过统一的后端抽象与接口约定,开发者可以在无需修改核心业务代码的前提下,将观测数据接入不同的存储或分析系统,从而灵活适配各类基础设施环境。
2.1 前置准备
当前以 Langfuse 作为观测后端为例说明完整接入流程,首先准备一个 Langfuse 项目:
- 打开 Langfuse 官方入门文档:
https://langfuse.com/docs/observability/get-started - 登录或创建 Langfuse 账号,创建一个项目。
- 进入项目设置页面,创建或查看该项目的 API Key。
 API Key 位置可参考 Langfuse 官方 FAQ:
API Key 位置可参考 Langfuse 官方 FAQ:
https://langfuse.com/faq/all/where-are-langfuse-api-keys
获取以下三个值:
LANGFUSE_BASE_URLLANGFUSE_PUBLIC_KEYLANGFUSE_SECRET_KEY
若使用 Langfuse Cloud,LANGFUSE_BASE_URL 的常见写法如下:
# EU 区域
export LANGFUSE_BASE_URL="https://cloud.langfuse.com"
# US 区域
# export LANGFUSE_BASE_URL="https://us.cloud.langfuse.com"
在本地环境中安装 Tracing 依赖:
# 安装 LazyLLM 本体,以及 Langfuse + OpenTelemetry 相关依赖
pip install lazyllm \
langfuse \
opentelemetry-api \
opentelemetry-sdk \
opentelemetry-exporter-otlp-proto-http
随后完成 LazyLLM Tracing 的运行配置:
# Langfuse 项目凭证
export LANGFUSE_PUBLIC_KEY="pk-lf-..."
export LANGFUSE_SECRET_KEY="sk-lf-..."
# LazyLLM tracing 默认开关
export LAZYLLM_TRACE_ENABLED="ON"
export LAZYLLM_TRACE_BACKEND="langfuse"
export LAZYLLM_TRACE_CONTENT_ENABLED="ON"
其中:
LAZYLLM_TRACE_ENABLED:是否默认开启 TracingLAZYLLM_TRACE_BACKEND:当前使用哪个观测后端LAZYLLM_TRACE_CONTENT_ENABLED:是否默认记录输入输出内容
2.2 LazyLLM默认的观测能力
如果现有代码已经使用 LazyLLM 编排业务流程,那么在配置好观测后端(例如 Langfuse)之后,直接运行代码即可生成新的 Trace,不需要额外设置 Tracing。
2.2.1 RAG示例
下面这段代码保持了 RAG 骨架的核心结构:Document -> Retriever -> formatter -> LLM -> Pipeline。
RAG 代码示例来自:https://docs.lazyllm.ai/zh-cn/stable/Learn/learn/#4-rag
import lazyllm
from lazyllm import bind
# 文档库负责构建可检索的知识源
documents = lazyllm.Document(dataset_path="./docs")
prompt = "下面是一个问题,运用所学知识来正确回答提问."
llm = lazyllm.OnlineChatModule(
source="sensenova",
model="SenseNova-V6-5-Pro",
)
# LLM 额外接收 context_str,用于承接检索结果
llm.prompt(lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
# Retriever 从文档库中召回候选片段
retriever = lazyllm.Retriever(
doc=documents,
group_name="CoarseChunk",
similarity="bm25_chinese",
topk=3,
)
with lazyllm.pipeline() as rag_ppl:
rag_ppl.retriever = retriever
# formatter 把召回节点整理成 prompt 所需的上下文字段
rag_ppl.formatter = (
lambda nodes, query: dict(
context_str='\n\n'.join([n.get_content() for n in nodes]),
query=query,
)
) | bind(query=rag_ppl.input)
rag_ppl.llm = llm
question = "什么是夜来香?"
answer = rag_ppl(question)
print(answer)
运行这段代码后,可以先根据本地执行结果确认流程是否执行成功,再到 Langfuse 中确认观测链路是否已经生成。
终端输出结果:
QUESTION: 什么是夜来香?
ANSWER: 夜来香是一种常见的观赏植物,属于茄科夜香树属(或萝藦科夜来香属,不同分类系统可能有所差异)。它的学名为*Cestrum nocturnum*(夜香树)或*Telosma cordata*(夜来香),具体种类因语境而异。夜来香最显著的特点是花朵在夜间散发出浓郁的花香,因此得名。
它通常作为园艺植物种植,具有攀援或灌木状的生长习性,叶片呈心形或椭圆形,花朵为黄绿色或白色,簇生于枝头。这种植物原产于热带美洲或亚洲部分地区,如今在世界各地的温暖地区都有栽培。需要注意的是,夜来香并非可食用植物,其花香虽宜人,但长时间处于浓郁花香环境中可能导致部分人感到不适,因此不适合室内密闭空间大量摆放。
Langfuse 实测结果:
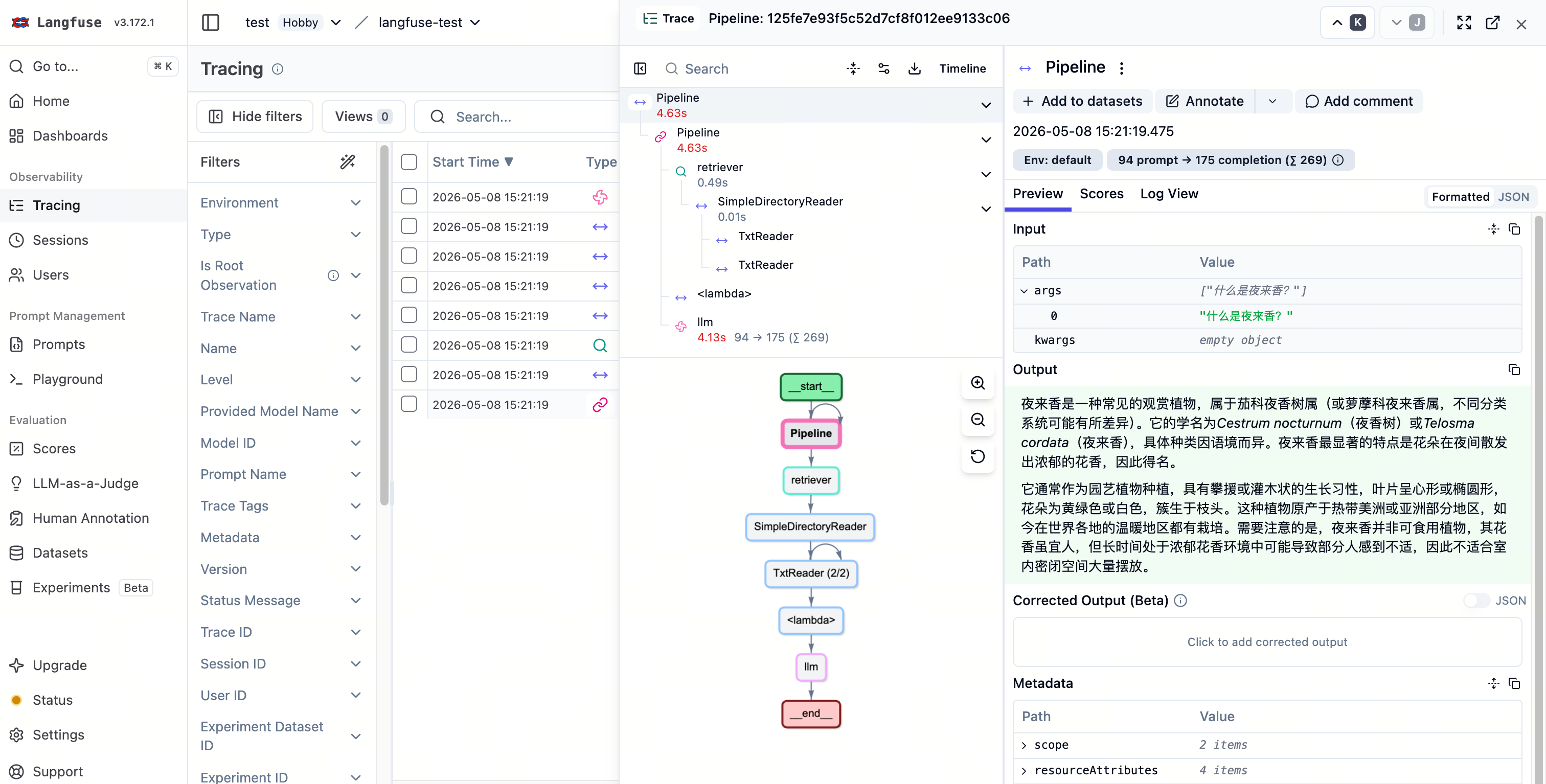
- Trace 名称为
Pipeline - 关键节点包括
Pipeline、retriever、llm、<lambda>以及文档读取相关的TxtReader - 其中
llm的 observation type 为GENERATION,模型名为SenseNova-V6-5-Pro retriever的 observation type 为RETRIEVER
页面中的字段和链路结构如何进一步阅读,可参考 2.6 Langfuse 页面介绍。
2.3 手动补充上下文信息:set_trace_context(...)
set_trace_context(...) 的作用是:在真正执行 LazyLLM 工作流之前,先写入这次请求的上下文信息。 它本身不会主动创建 Trace,也不会单独创建观测节点;后续仍然需要配合一次真正的 LazyLLM 调用一起使用。这是一种请求级控制方式,适合在不改变调用结构的前提下补充或修改当前请求的信息。
2.3.1 适用场景
当 Trace 已经能够正常生成,而当前需要为这次请求补充或修改信息时,可考虑使用这一方式。典型场景包括:
- 这条请求属于哪个会话
- 这条请求来自哪个用户
- 这条请求属于哪一类场景,例如
rag、agent、demo - 这条请求需要续接到一条已有 Trace
- 这条请求需要临时控制采集行为
- 业务调用方式不希望改动
2.3.2 示例:
from lazyllm import LazyTraceContext, set_trace_context
# 基于 2.2.1 中已经构建好的 rag_ppl 和 question
set_trace_context(
LazyTraceContext(
session_id="demo-session",
user_id="demo-user",
request_tags=["rag", "context-demo"],
)
)
answer = rag_ppl(question)
print(answer)
在这个例子中,真正的业务调用方式并没有变化,变化只发生在调用前:先设置 LazyTraceContext,再执行原有的 rag_ppl(question)。
这里需要注意:
如果只是单独调用 set_trace_context(...),而后面没有真正执行 LazyLLM 工作流,那么不会自动生成新的 Trace。这种使用方式本质上是请求级上下文控制 API,既可以配合默认观测能力使用,也可以与后续的显式入口控制配合使用;但在与 enable_trace(...) 组合使用时,应以 enable_trace(...) 传入的 Tracing 参数为准。
2.4 手动声明观测入口 enable_trace(...)
enable_trace(...) 的作用是:在真正执行某一次调用之前,先显式为这次调用建立一个观测入口。 它不是只补充请求信息,而是会直接管理这次调用如何进入观测。这是一种调用级入口控制方式,适合在需要明确入口边界、集中设置入口级 Tracing 信息时使用。
这里需要区分两种情况:
- 如果包装的是 LazyLLM 内部的工作流对象(例如 Flow)或功能组件(例如 Module),enable_trace(...) 会先准备上下文,再交给框架已有的默认观测能力去创建节点
- 如果 enable_trace(...) 直接包装的是一个独立的普通 Python callable,并且当前没有活动父节点,也没有显式传入 trace_id / parent_span_id,则会为这次调用创建一个根节点;如果该 callable 已作为 LazyLLM 工作流中的步骤执行,或者显式提供了父链路信息,那么它作为子节点被挂载到完整的 Trace 链路中
2.4.1 作为 Wrapper 使用
对某一次调用显式开启 Tracing 时,wrapper 是最直接的方式。
from lazyllm import enable_trace
# 基于 2.2.1 中已经构建好的 rag_ppl 和 question
answer = enable_trace(
rag_ppl,
question,
session_id="demo-session",
user_id="demo-user",
request_tags=["rag", "wrapper-demo"],
)
print(answer)
这里需要注意:
enable_trace(...) 中的 Tracing 专用参数,例如 session_id、request_tags 等,会被 Tracing 逻辑先消费掉,不会再继续透传给后续业务函数。
2.4.2 作为 Decorator 使用
当某个函数作为可复用入口存在时,decorator 往往更自然。
from lazyllm import enable_trace
# 基于 2.2.1 中已经构建好的 rag_ppl
@enable_trace(session_id="demo-session", request_tags=["rag", "decorator-demo"])
def run_once(question):
return rag_ppl(question)
answer = run_once(question)
print(answer)
这种写法的特点是:
- Tracing 入口与函数定义绑定
- 适合服务入口、统一 API 封装、长期存在的调用边界
- 相比 wrapper,更适合“反复调用同一种入口”的场景
2.4.3 适用场景
enable_trace(...) 适合手动为某一次调用建立明确的观测入口。典型场景包括:
- 脚本里有多个步骤,但只想从某个函数开始算观测入口
- 服务里有统一的请求处理函数,想把它作为稳定入口
- 需要在入口处集中设置
session_id、user_id、request_tags等信息 - 有一个普通 Python 函数不属于 LazyLLM 默认工作流,但也想把它纳入观测
- 需要把当前调用显式续接到上游 Trace
- 需要为测试、调试或一次性验证建立明确入口
2.5 常见字段与采集配置
LazyLLM 的请求级 Tracing 信息统一收敛在 LazyTraceContext 中。
其中一部分字段用于控制“请求的观测采集范围”,另一部分字段用于标识“请求的归属问题”。
2.5.1 全局采集开关
全局采集开关决定的是默认观测行为。
| 配置项 | 作用 | 常见示例 |
|---|---|---|
LAZYLLM_TRACE_ENABLED |
是否默认开启 Tracing | "ON" |
LAZYLLM_TRACE_CONTENT_ENABLED |
是否默认记录输入输出内容 | "ON" / "OFF" |
LAZYLLM_TRACE_BACKEND |
当前使用哪个观测后端 | "langfuse" |
2.5.2 请求级采集控制
当默认配置已经生效,但某一次请求需要临时覆盖默认行为时,可通过 set_trace_context(...) 设置以下控制字段:
| 字段 | 作用 | 常见示例 | 常用配置方式 |
|---|---|---|---|
enabled |
显式控制当前请求是否开启 Tracing | True / False |
set_trace_context(...) |
sampled |
控制本次请求是否参与采样上报 | True / False |
set_trace_context(...) |
debug_capture_payload |
强制控制是否记录输入输出内容 | True / False |
set_trace_context(...) |
module_trace |
运行时按模块关闭部分采集 | {"by_name": {"llm": False}} |
set_trace_context(...)、enable_trace(...) |
示例 1:关闭单次请求的输入输出内容采集
from lazyllm import LazyTraceContext, set_trace_context
# 基于 2.2.1 中已经构建好的 rag_ppl 和 question
set_trace_context(
LazyTraceContext(
debug_capture_payload=False,
)
)
answer = rag_ppl(question)
print(answer)
这次请求仍会生成 Trace,但不再默认保留完整的输入输出内容。
示例 2:临时关闭某类模块的采集
from lazyllm import LazyTraceContext, set_trace_context
# 基于 2.2.1 中已经构建好的 rag_ppl 和 question
set_trace_context(
LazyTraceContext(
module_trace={"by_name": {"llm": False}},
)
)
answer = rag_ppl(question)
print(answer)
这次请求中 llm 模块的观测会被关闭,其他默认开启的节点仍可继续记录。
使用规则:
- 需要修改整个进程的默认行为时,优先使用
2.1中的环境变量配置 - 只想影响单次请求时,优先使用
set_trace_context(...) - 只想明确入口边界时,使用
enable_trace(...),不要把它当作采集配置入口
2.5.3 请求级上下文字段
这类字段主要用于请求归属、筛选分组和链路续接:
| 字段 | 作用 | 常见示例 | 常用配置方式 |
|---|---|---|---|
session_id |
标识一次会话或一组关联请求 | "chat-session-001" |
set_trace_context(...)、enable_trace(...) |
user_id |
标识请求属于哪个用户 | "user-42" |
set_trace_context(...)、enable_trace(...) |
request_tags |
给请求打标签,便于筛选、分组和对比 | ["rag", "ab-test"] |
set_trace_context(...)、enable_trace(...) |
trace_id |
把当前调用续接到已有 Trace | "trace-abc123" |
set_trace_context(...)、enable_trace(...) |
parent_span_id |
指定当前调用挂载到哪个父节点下 | "span-root-001" |
set_trace_context(...)、enable_trace(...) |
2.6 Langfuse页面介绍
完成接入后,可在 Langfuse 的 Tracing 页面查看 Trace 结果。Langfuse 将一次完整请求记录为 Trace,并将其中的各个步骤记录为 Observation。Session 用于聚合同一会话下的多条 Trace,Scores 用于展示评测结果或人工反馈。
2.6.1 页面布局
Langfuse 的 Tracing 页面通常由三部分组成:
- 导航区:进入
Tracing、Sessions、Scores等模块 - 主视图区:展示
Trace列表,或在单条Trace内展示链路树和时间线 - 详情区:展示当前选中
Trace或Observation的详细信息
页面阅读通常遵循固定顺序:先定位目标 Trace,再查看链路结构,最后读取节点详情。
2.6.2 Trace 列表页
Trace 列表页主要用于筛选和定位目标请求。页面通常提供搜索、时间范围和属性过滤。常见信息包括:
- 名称或标题:识别业务入口或流程类型
- 时间:确认是否为目标请求
- 状态:快速识别失败或异常请求
Latency:识别慢请求Cost/Token usage:识别高成本请求Session/User/Tags/Environment/Release:按会话、用户、版本、环境或业务标签分组和对比
2.6.3 Trace 详情页
打开单条 Trace 后,页面通常包含两个核心区域:
- 链路结构区:展示一次请求的执行结构。根节点表示整条
Trace,子节点表示各个Observation。常见类型包括GENERATION、RETRIEVER、TOOL和普通SPAN - 节点详情区:展示当前选中节点的
input、output、metadata、usage、scores等信息。部分页面支持Formatted/JSON切换,用于不同的排查场景
Trace 级摘要信息通常位于页面顶部或详情区上方,常见字段包括:
Trace ID:用于跨系统定位同一次请求Session/User:用于确认请求归属Tags/Environment/Release:用于版本、环境和业务维度的过滤与对比Latency/Cost/Token usage:用于性能和成本分析
2.6.4 推荐查看顺序
- 在
Trace列表页通过时间、标签、会话或用户定位目标请求 - 打开
Trace后先查看摘要信息,确认状态、耗时、成本、环境和版本 - 再查看链路结构,优先关注失败节点、最慢节点和关键模型节点
- 最后读取选中节点的
input、output、metadata和usage,确认问题发生在哪一步 - 如需横向分析,再回到列表页比较同类请求、同版本请求或同一会话下的其他
Trace
3. LazyLLM 观测系统的设计与关键实现
第 3 章从分层设计和关键实现两个角度说明 LazyLLM 的观测系统
3.1 总体架构与核心对象
3.1.1 分层总览
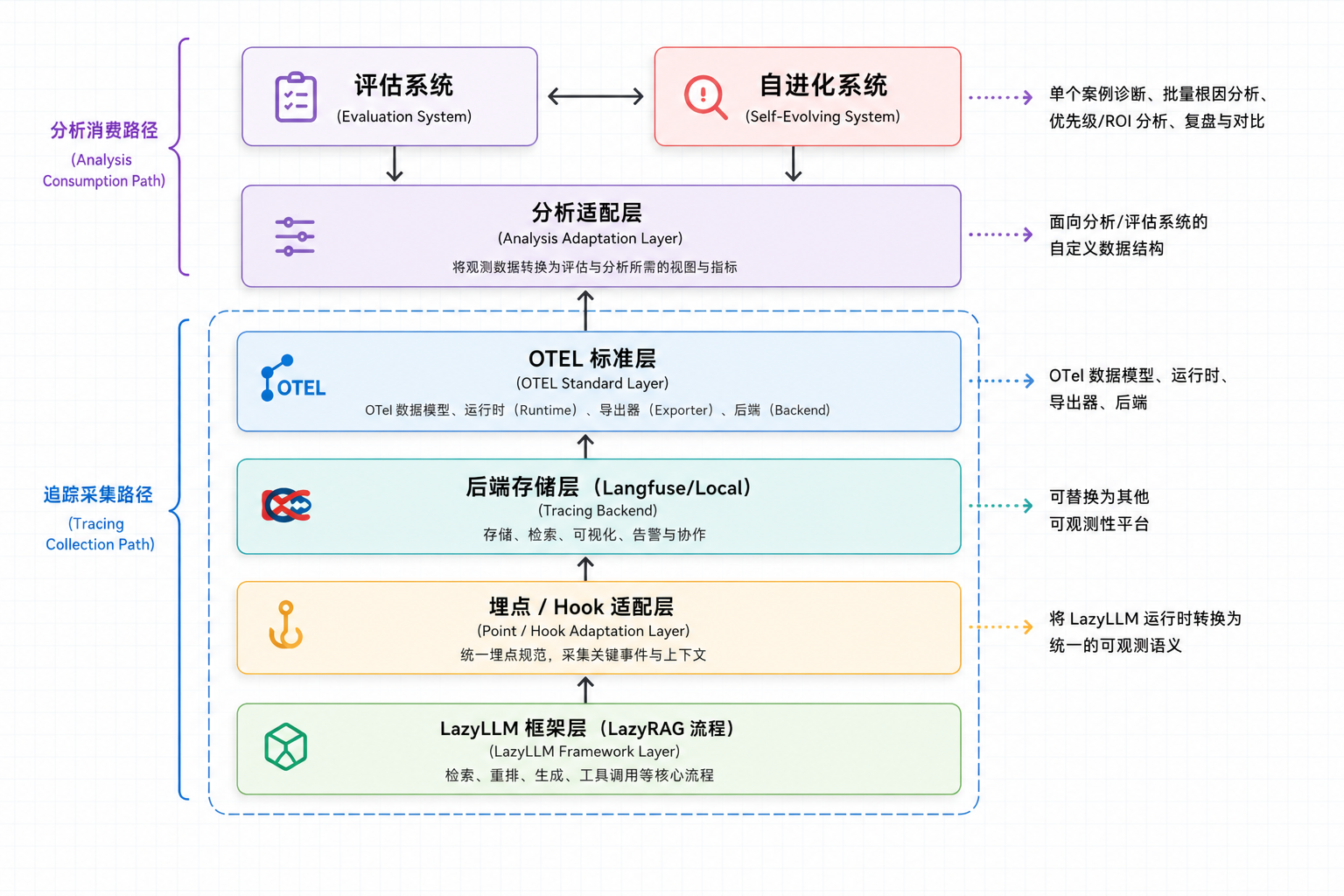
图中上半部分是分析消费路径:分析适配层从 Tracing Backend 读取 Trace 数据,将其转换为评估系统、自进化系统等上层系统可直接使用的数据结构。后续小节围绕采集路径展开关键实现,分析适配层只作为系统边界说明。
图中下半部分是 Tracing 采集路径:LazyLLM 运行层产生真实执行过程,埋点 / Hook 适配层将运行时事件转换为统一观测语义,OTEL 标准层维护 span 生命周期、父子关系和上下文传播,Tracing Backend 负责存储、检索和展示。
结合上图,LazyLLM 观测系统的各层职责可以概括为:
| 层 | 主要职责 | 关键代码 |
|---|---|---|
| LazyLLM 运行层 | 执行 Flow、Module、callable,形成真实业务调用链 |
lazyllm/flow/flow.py、lazyllm/module/module.py |
| 埋点适配层 | 决定默认接入方式、采集策略、语义补全和结构化输出属性 | lazyllm/hook.py、lazyllm/tracing/collect/hook.py、lazyllm/tracing/collect/trace_config.py、lazyllm/tracing/collect/output_attrs.py |
| OTEL 标准层 | 管理 span 生命周期、上下文传播、父子关系和请求级聚合状态 |
lazyllm/tracing/collect/runtime.py、lazyllm/tracing/collect/context.py、lazyllm/tracing/collect/span.py |
| Tracing Backend 底座层 | 构造 exporter,把 OTel spans 写入后端存储 | lazyllm/tracing/backends/langfuse/* |
| 分析适配层 | 从 Tracing Backend 读取数据,转换为上层分析系统的数据结构 | - |
3.1.2 核心对象
观测系统内部同时存在传播、节点描述和请求聚合三类状态,因此 LazyLLM 观测系统没有把它们压缩到同一个对象中,而是拆成三类长期协作的核心对象:轻量请求上下文、节点级对象和请求级聚合对象。
下面的代码片段只保留理解模型所需的关键字段,并非完整源码定义。完整实现可参考 lazyllm/tracing/collect/context.py 和 lazyllm/tracing/collect/span.py。
# 简化示意:轻量上下文保存请求级传播所需的 tracing 信息
@dataclass
class LazyTraceContext:
enabled: Optional[bool] = None
trace_id: Optional[str] = None
parent_span_id: Optional[str] = None
session_id: Optional[str] = None
user_id: Optional[str] = None
request_tags: List[str] = field(default_factory=list)
module_trace: Optional[Dict[str, Any]] = None
sampled: Optional[bool] = None
debug_capture_payload: Optional[bool] = None
# 简化示意:节点快照描述单个 observation 的身份、输入输出和附加属性
@dataclass
class LazySpan:
name: str = ''
span_kind: str = ''
semantic_type: Optional[str] = None
trace_id: Optional[str] = None
span_id: Optional[str] = None
parent_span_id: Optional[str] = None
input: Optional[Any] = None
output: Optional[Any] = None
status: str = 'ok'
error: Optional[Exception] = None
config: Dict[str, Any] = field(default_factory=dict)
output_attrs: Dict[str, Any] = field(default_factory=dict)
usage: Optional[Dict[str, Any]] = None
# 简化示意:请求级聚合对象维护整条 trace 的总体状态
@dataclass
class LazyTrace:
trace_id: str
root_span_id: Optional[str] = None
session_id: Optional[str] = None
user_id: Optional[str] = None
request_tags: List[str] = field(default_factory=list)
start_time: float = field(default_factory=time.time)
end_time: Optional[float] = None
is_reconstructed: bool = False
status: str = 'ok'
metadata: Dict[str, Any] = field(default_factory=dict)
LazyTraceContext负责承载请求级轻量上下文,重点解决传播问题LazySpan负责描述单个观测节点的运行快照,重点表达节点级输入输出、状态和附加属性LazyTrace负责维护请求级聚合状态,重点解决整条 Trace 的统计与结束状态更新问题
3.2 LazyLLM 运行层
3.2.1 请求如何进入统一执行链
运行层要解决的问题是:在不改变现有业务调用方式的前提下,把 Tracing 能力稳定接入真实执行链。LazyLLM 的设计选择不是再增加一套专门的观测入口,而是复用已经存在的统一调用骨架。以 LazyLLM 的 Flow 和 Module 为例,它们都在自己的调用入口统一接入 execution_with_hooks(...),因此 Tracing 能力天然附着在既有执行框架上。
class LazyLLMFlowsBase(FlowBase, metaclass=LazyLLMRegisterMetaClass):
def __init__(...):
...
# Flow 初始化时就挂上默认 hook 集合
self._hooks = []
register_hooks(self, resolve_builtin_hooks(self))
# Flow 的统一调用入口在这里接入 hook 和调用栈
@execution_with_hooks
def __call__(self, ...):
# stack_enter 让运行时能够感知当前 Flow 的调用层级
with globals.stack_enter(self.identities):
output = self._run(...)
return self._post_process(output)
# Module 同样复用 execution_with_hooks,只是把真实执行委托给 _call_impl
def __call__(self, ...):
return execution_with_hooks(self, ...)(self._call_impl)(...)
这两段代码对应同一设计:一方面,Flow 在初始化阶段就解析并挂载默认 hooks;另一方面,Flow 和 Module 的真实调用都统一进入 execution_with_hooks(...)。因此,默认观测能力并不依赖新的业务 API,而是直接附着在运行层已有的执行链上。
3.3 埋点适配层
3.3.1 默认接入:Hook 选择与挂载
埋点适配层首先要解决的问题是:默认情况下,哪些对象应当进入观测。如果把 Tracing 判断分散到每个业务类中,接入范围会难以维护。LazyLLM 的设计选择是把这类判断收敛为内置 hook provider,在对象构造阶段统一决定是否挂 LazyTracingHook。
# 默认 provider 容器
_builtin_hook_providers = []
def resolve_builtin_hooks(...):
hooks = []
for provider in _builtin_hook_providers:
hooks.extend(provider(obj) or [])
return hooks
def register_hooks(...):
...
# tracing provider 只负责判断当前对象是否默认进入观测
def resolve_tracing_hooks(...):
if not config['trace_enabled']:
return []
subject = _unwrap_trace_subject(obj)
if hasattr(subject, '_module_id') and not resolve_default_module_trace(...):
return []
return [LazyTracingHook]
register_builtin_hook_provider(resolve_tracing_hooks)
这两段代码对应了两层分工:resolve_builtin_hooks(...) 负责汇总所有 provider 的判断结果,resolve_tracing_hooks(...) 则只回答当前对象是否应当默认进入 Tracing。默认接入的核心作用,是在对象构造阶段把观测能力附着到后续调用上。
3.3.2 节点观测:LazyTracingHook
这个部分要解决的问题是:一段普通调用如何被组织成一个 observation 的完整生命周期。LazyLLM 的做法是把“统一调度”和“Tracing 语义”分开:hook_execution(...) 提供通用的 hook 调度骨架,LazyTracingHook 则负责具体的 Tracing 行为。
# 通用 hook 调度器:统一组织成功、失败和结束三个分支
@contextmanager
def hook_execution(obj, ...):
hook_objs = tuple(prepare_hooks(obj, ...))
def hooked_call(fn, ...):
try:
result = fn(...)
except Exception as e:
run_hooks(hook_objs, 'on_error', e)
raise
else:
run_hooks(hook_objs, 'post_hook', result)
return result
try:
yield hooked_call
finally:
# finalize 无论成功还是失败都会执行,保证结束处理一致
run_hooks(hook_objs, 'finalize')
# tracing hook:调用前建句柄,调用后回写,最后统一结束
class LazyTracingHook(LazyLLMHook):
def pre_hook(...):
trace_cfg = globals.get('trace', {})
if trace_cfg.get('enabled') is False or trace_cfg.get('sampled') is False:
return
self._span = start_span(self._trace_target(), ...)
if self._span:
install_post_process_probe(self._obj)
def post_hook(...):
if not self._span:
return
set_span_output(self._span, ...)
...
set_span_attributes(self._span, ...)
def on_error(...):
if self._span:
set_span_error(self._span, ...)
def finalize(...):
remove_post_process_probe(self._obj)
if self._span:
finish_span(self._span)
hook_execution(...) 负责统一调度,LazyTracingHook 负责 Tracing 的编排:pre_hook(...) 决定是否进入观测,并在需要时创建节点句柄;post_hook(...) 在成功路径回写输出、usage 与结构化属性;on_error(...) 在异常路径记录错误;finalize(...) 则无论成功还是失败,都会统一触发节点结束处理。对于 retriever、reranker 这类节点,部分关键结果会在后处理阶段才出现,因此需要提前安装 probe 补充采集。节点级观测之所以能够保持稳定,依赖的正是这种统一的阶段划分。
3.3.3 采集控制策略
采集控制策略要解决的问题是:系统既要默认具备观测能力,又要能够控制采集范围、采集成本和敏感信息暴露。LazyLLM 的做法是把这类控制拆成“全局默认 + 模块级规则 + 请求级覆盖”三层开关,让系统在没有额外干预时仍有稳定默认行为,同时允许单次请求临时调整采集范围,而不必改动整个进程的配置。
# 默认规则定义进程级采集行为和模块级自动接入范围
config.add('trace_enabled', bool, True, 'TRACE_ENABLED')
config.add('trace_content_enabled', bool, True, 'TRACE_CONTENT_ENABLED')
DEFAULT_MODULE_TRACE_CONFIG = {
'default': True,
'by_name': {'retriever': True, 'reranker': True, 'llm': True},
'by_class': {'OnlineModule': True},
}
def resolve_default_module_trace(...):
...
def resolve_runtime_module_trace_disabled(...):
...
# 节点创建前看是否允许采集;节点创建后再看是否保留 payload
def pre_hook(self, ...):
trace_cfg = globals.get('trace', {})
trace_enabled = trace_cfg.get('enabled')
if trace_enabled is None:
trace_enabled = config['trace_enabled']
if not trace_enabled or trace_cfg.get('sampled') is False:
return
if hasattr(t, '_module_id') and resolve_runtime_module_trace_disabled(...):
return
def _capture_payload_enabled(...):
if ctx.debug_capture_payload is not None:
return bool(ctx.debug_capture_payload)
return bool(config['trace_content_enabled'])
这两段代码对应的是一个固定的生效顺序:先判断这次请求是否允许创建节点,再判断当前模块是否允许被记录,最后才决定是否保留输入输出内容。把“是否生成 Trace”和“是否保留输入输出内容”拆开处理,是因为前者解决可观测性是否存在,后者解决记录粒度、成本和敏感信息范围。
3.3.4 配置、语义与结构化补全
这个部分要解决的问题是:如果 observation 只记录 input/output,后续分析仍然难以判断节点在业务上扮演什么角色。为此,埋点适配层还需要把 LazyLLM 的业务语义补充进节点。LazyLLM 当前做了三类补全:
- 配置补全:模型、相似度、Top-K、控制流结构等
- 语义补全:
llm、retriever、rerank、tool等 - 输出属性补全:检索分数、重排分数、分支命中信息、循环实际迭代次数
# 这一段负责把组件配置和语义类型补成节点属性
def collect_trace_config(...):
cfg = _collect_private_trace_config(target)
if _looks_like_online_module(target):
cfg.update(_collect_llm_trace_config(target, ...))
elif _looks_like_retriever(target):
cfg.update(_collect_retriever_trace_config(target))
elif _looks_like_reranker(target):
cfg.update(_collect_reranker_trace_config(target))
elif _is_flow_target(target):
cfg.update(_collect_flow_trace_config(target))
return normalize_trace_entity_config(cfg)
def resolve_semantic_type_for_target(...):
if span_kind == 'flow':
return SemanticType.WORKFLOW_CONTROL
...
这段代码是补全和语义补全的入口:不同类型的目标对象会补入不同的组件配置,并进一步解析成统一的语义类型。输出属性补全会继续把 retriever 分数、reranker 分数、分支命中信息和循环次数这类结构化结果挂到节点上。这样后续分析看到的不再只是“执行过什么代码”,而是“这个节点在业务上完成了什么动作”。
3.4 OTEL 标准层
3.4.1 轻量上下文与运行时状态
OTEL 标准层首先要解决的问题是:哪些状态需要跨调用传播,哪些状态需要描述当前请求,哪些状态又必须跟随运行时调用栈。LazyLLM 的设计选择是把轻量上下文、请求级聚合状态和 active span 明确分开维护:
globals['trace']只保存轻量、可序列化的 Tracing 信息- 当前活动
Trace存在_current_trace这个ContextVar中 - 当前活动
span由 OTel active context 维护,不放进globals
# globals['trace'] 只保存轻量、可传播的 tracing 信息
class Globals(metaclass=SingletonABCMeta):
__global_attrs__ = ThreadSafeDict(trace={})
def __init__(self):
self.__sid = contextvars.ContextVar('local_var')
# _current_trace 保存当前上下文里的请求级聚合状态
_current_trace: contextvars.ContextVar[Optional[LazyTrace]] = contextvars.ContextVar(
'_lazyllm_current_trace', default=None
)
def get_trace_context() -> LazyTraceContext:
return LazyTraceContext.from_dict(llm_globals.get('trace', {}))
这两段代码对应了三类状态的分工:globals['trace'] 负责保存轻量、可传播的请求级状态;_current_trace 负责保存当前请求的聚合状态;active span 仍交由 OTel context 跟随调用栈维护。这种拆分同时满足了跨边界传播、请求级聚合和运行时嵌套三类需求。
3.4.2 节点生命周期
这个部分要解决的问题是:一个 LazyLLM 观测节点如何被转换成标准的 OTel span。LazyLLM观测系统把这一过程拆成创建和收尾两个阶段,分别由 start_span(...) 和 finish_span(...) 承载。
def start_span(self, ...):
ctx = get_trace_context()
if not self._trace_enabled(ctx) or not self._ensure_runtime():
return None
parent_context = None
# 优先复用当前活跃 span,避免打断已有父子链路
if self._trace_api.get_current_span().get_span_context().is_valid:
parent_context = opentelemetry.trace.set_span_in_context(...)
elif ctx.trace_id and ctx.parent_span_id:
# 没有活跃 span 时,再按轻量上下文重建父链路
parent_context = opentelemetry.trace.set_span_in_context(...)
...
otel_span = self._tracer.start_as_current_span(span_name, context=parent_context).__enter__()
# 新 span 生成后,把标识回写到轻量上下文
ctx.trace_id = ...
ctx.parent_span_id = ...
set_trace_context(ctx)
def finish_span(...):
otel_span = span._otel_span
# 先写回标准属性,再统一处理异常和关闭句柄
for k, v in self._backend.map_attributes(self._build_otel_attributes(span, trace=_current_trace.get())).items():
otel_span.set_attribute(k, v)
...
if span.error:
# 异常也要同步到底层 span
otel_span.record_exception(span.error)
span._otel_span_cm.__exit__(None, None, None)
这两段代码体现了 OTel 层的两项核心工作。start_span(...) 不只是创建 span,还会判定父链路并把新的标识回写到轻量上下文;finish_span(...) 不只是关闭 span,还会整理节点属性、执行 backend 映射并同步异常信息。也就是说,这一层负责把 LazyLLM 的节点语义转换成标准化的 span 生命周期。
3.4.3 显式入口:enable_trace(...)
默认 hook 解决的是工作流内部节点的接入问题,但入口边界仍然需要单独控制。这正是 enable_trace(...) 存在的原因:它显式准备一次 Tracing 上下文,而不是替代默认节点观测。对于 LazyLLM 组件,它仍然把后续节点交给默认接入;对于普通 Python callable 对象,它会补一个入口 span。
# 显式入口先准备上下文,再决定是否为普通 callable 补入口节点
def _run_with_trace(func, ...):
old_ctx = get_trace_context()
new_ctx_data = old_ctx.to_dict()
# 先复制旧上下文,再覆盖本次入口需要的字段
new_ctx_data.update({
'trace_id': ...,
'parent_span_id': ...,
'request_tags': ...,
'module_trace': ...,
'enabled': True,
})
set_trace_context(LazyTraceContext.from_dict(new_ctx_data))
try:
# LazyLLM 组件继续走默认 hook,普通 callable 才额外补入口 span
is_lazyllm_component = hasattr(func, '_module_id') or hasattr(func, '_flow_id')
span = None if is_lazyllm_component else start_span(func, ...)
...
finally:
set_trace_context(old_ctx)
对于两类对象的分流逻辑:对于 LazyLLM 组件,enable_trace(...) 只准备入口上下文,后续节点仍由默认 hook 创建;对于普通 Python callable,它会在必要时额外补一个入口 span。因此,这一能力解决的是入口边界控制问题,而不是再建立第二套观测机制。
3.4.4 并发与上下文传播
并发场景下,OTEL 标准层要解决的问题是:同一条请求进入新的执行单元后,后续创建的 span 仍能正确续接到原有 trace。LazyLLM 在不同执行器上没有采用单一机制,而是把 ContextVar 传播和可恢复的会话级状态传播组合使用:
- 需要保留
ContextVar链路的线程路径,会使用copy_context().run(...)。因此 OTel active context、_current_trace以及其他基于ContextVar的 Tracing 状态可以一起进入 worker。 - 仅负责维持会话标识的线程封装,会显式重新绑定
sid;这类路径能保证lazyllm.globals/lazyllm.locals访问到当前请求对应的会话数据,但不会自动复制完整的ContextVar状态。 - 需要跨进程执行的路径,则不能直接携带活跃的 span 对象或
ContextVar状态,因此会把当前globals._data的可序列化快照作为global_data传入 worker;其中globals['trace']是 Tracing 最关键的字段,但不是唯一被传递的内容。 - worker 侧通过
_init_sid(sid)和_update(global_data)恢复上下文;后续start_span(...)会读取globals['trace']中的trace_id/parent_span_id,在需要时重建父SpanContext,从而把新 span 续接回原 trace,而不是直接复用父进程中的活跃 span 实例。
@staticmethod
def _worker(...):
lazyllm.globals._init_sid(sid)
if ...:
# 进程路径需要恢复父进程传来的会话级快照
lazyllm.globals._update(...)
...
return func(*args, **kw)
def _parallel_execute_concurrent(...):
...
# 线程路径直接复制 ContextVar,上下文可以一起进入 worker
futures.append(e.submit(worker_call) if self._multiprocessing else e.submit(copy_context().run, worker_call))
# Graph 调度也是线程路径,因此直接复制 ContextVar 即可
future = executor.submit(copy_context().run, partial(self.compute_node, globals._sid, node, ...))
这段代码分别对应线程路径与进程路径的处理方式。线程路径直接复制 ContextVar,因此 OTel active context 和 _current_trace 可以一起进入 worker;进程路径则依赖 globals._data 的可序列化快照恢复会话级状态,并根据 trace_id / parent_span_id 重新续接父链路。总体来说,ContextVar 负责活跃 Tracing 上下文,globals 负责可恢复的会话级状态,两者在不同执行器中承担的角色并不相同。
3.4.5 请求级聚合状态
节点之间的父子关系只能描述调用结构,还不足以表达整条请求的聚合状态。因此,OTEL 标准层还需要一个请求级对象来维护总体状态,这就是 LazyTrace 的作用。通过 _current_trace 把这份聚合状态绑定到上下文中。
active_trace = _current_trace.get()
if active_trace is None or active_trace.trace_id != trace_id_hex or not active_trace.is_active:
# 首个活动 span 才会创建请求级聚合对象
new_trace = LazyTrace(
trace_id=trace_id_hex,
root_span_id=span_id_hex if is_root_span else None,
...
is_reconstructed=is_reconstructed,
)
# 新 trace 绑定到当前上下文,供后续节点继续登记
_current_trace.set(new_trace)
active_trace = new_trace
...
# 记录当前 span 进入请求级聚合状态
active_trace._record_span_start(lazy_span)
这段代码体现了 LazyTrace 的创建与登记方式:首个活动 span 会触发请求级聚合对象的创建,后续节点则继续登记到已有 LazyTrace 中。节点结束后,runtime 再据此完成请求状态更新。因此,LazyTrace 提供的是请求级状态视角,而不是节点视角的简单重复。
3.5 Tracing Backend 底座层
Backend 层负责承接已经标准化的 span,并将其写入具体的观测后端。LazyLLM 没有让业务流程、Hook 逻辑或 OTel 生命周期管理直接依赖某个存储目标,而是通过 Tracing Backend 层统一处理后端接入。它位于 OTEL 标准层之后,用于隔离写入目标差异,使上层只需稳定生成统一的观测数据。
通过这个统一的抽象接口,观测数据可以写入 Langfuse、本地 JSONL 等观测后端,也可以接入其他存储系统、分析系统或可观测平台。新增后端时,只需要沿用这一层接口,而不需要改动上层采集流程。
3.5.1 Backend 层的能力
TracingBackend 基类抽象出两个核心能力:
class TracingBackend(ABC):
name = ''
# 构造写入通道,决定 span 最终写入哪个后端
@abstractmethod
def build_exporter(self):
pass
# 按后端需要补充或转换属性,不改变 LazyLLM 的通用属性生成流程
@abstractmethod
def map_attributes(self, otel_attrs: Dict[str, Any]) -> Dict[str, Any]:
pass
build_exporter(...) 负责构造数据写入通道。例如,Langfuse 后端通过 OTLP exporter 将 span 发送到 Langfuse;Local 后端通过本地文件 exporter 将 span 写入 JSONL 文件。
map_attributes(...) 负责后端专用字段适配。LazyLLM 先生成统一的 OTel 属性,再由 backend 补充目标后端需要的字段。Langfuse 需要将部分通用属性映射为 langfuse.* 字段;Local 后端保留原始 OTel 属性即可,因此不需要额外映射。
3.5.2 Backend 层的实现
具体后端通过名称、模块路径和类名进入统一加载路径。运行时根据配置获取 backend 实例,不直接依赖具体后端类。
# 不同后端通过统一注册表进入加载流程
_TRACE_BACKEND_SPECS = (
('langfuse', '.langfuse.backend', 'LangfuseBackend'),
('local', '.local.backend', 'LocalBackend'),
)
_CONSUME_BACKEND_SPECS = (
('langfuse', '.langfuse', 'LangfuseConsumeBackend'),
('local', '.local.backend', 'LocalConsumeBackend'),
)
其中,Tracing backend 负责写入观测数据,Consume backend 负责在分析消费路径中读取已有观测数据。例如 Local 后端写入本地 JSONL 后,消费端可以将 JSONL span 还原为统一的 RawTracePayload,供后续分析系统使用。
运行时对 backend 的调用方式保持稳定:
# backend 负责构造 exporter,runtime 负责把它安装到 provider 上
backend = self._get_backend()
exporter = backend.build_exporter()
resource = Resource.create({'service.name': 'lazyllm'})
provider = TracerProvider(resource=resource)
provider.add_span_processor(BatchSpanProcessor(exporter))
trace_api.set_tracer_provider(provider)
...
# 先写入 LazyLLM 通用属性,再补充后端专用属性
for k, v in otel_attrs.items():
otel_span.set_attribute(k, v)
for k, v in self._backend.map_attributes(otel_attrs).items():
otel_span.set_attribute(k, v)
Backend 层不改变上层 span 的创建、推进和结束过程,只在运行时初始化阶段提供 exporter,并在 span 结束前补充后端需要的属性。