Google 搜索
本教程将介绍如何使用 LazyLLM 提供的 GoogleSearch 工具,实现自动化网页搜索与内容抓取的完整流程。最终效果:输入一个查询词(如“圆明园”),系统会自动调用 Google 搜索 API 获取网页结果,并抓取网页正文内容输出为表格。
通过本节您将学习到 LazyLLM 的以下要点:
- 如何使用 GoogleSearch 调用 Google Custom Search API;
- 如何通过
BeautifulSoup抓取网页正文; - 如何构建一个自动化网页搜索与内容抽取流程。
设计思路
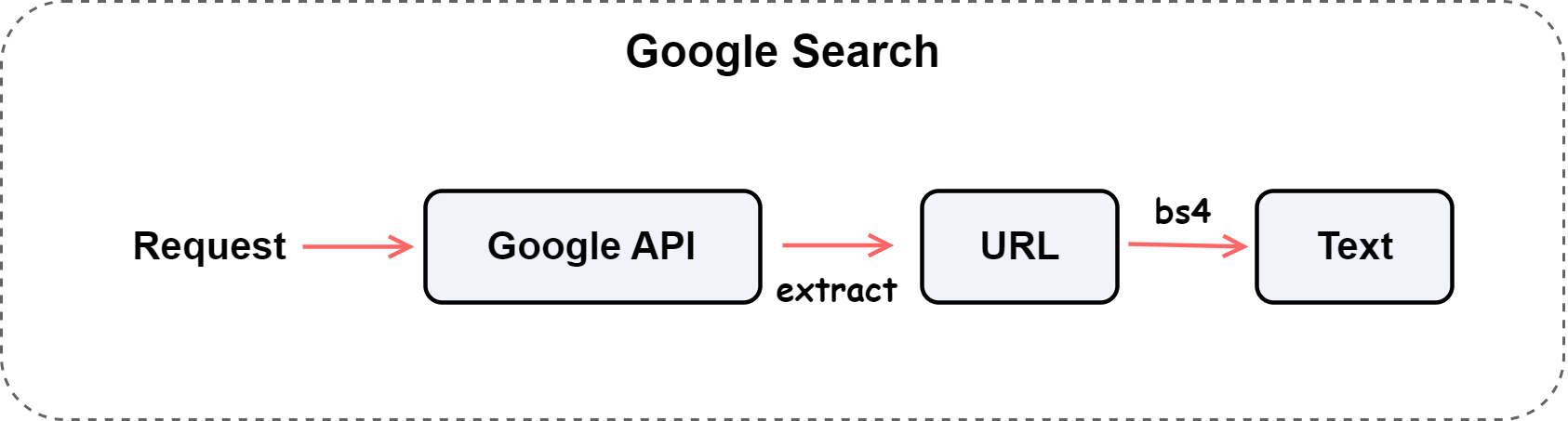
我们的目标是构建一个能够自动化完成搜索与网页信息抽取的智能信息采集工具。
当用户输入一个查询词(例如“圆明园”)时,系统需要完成以下步骤:
- 搜索阶段 —— 调用
GoogleSearch工具,通过 Google Custom Search API 获取相关网页结果; - 解析阶段 —— 从搜索结果中提取网页标题与链接,形成结构化数据表;
- 抓取阶段 —— 遍历链接列表,抓取网页正文内容,并清理掉脚本、样式等无关信息,输出纯净文本。
为实现这一流程,系统采用“搜索 → 解析 → 抓取”的三级架构设计,以实现从关键词到结构化文本数据的自动转换。
整体流程如下图所示:
环境准备
安装依赖
在开始前,请先安装所需依赖库:
准备 API Key
GoogleSearch 工具依赖 Google Custom Search API,请先前往 Google Developers 申请 API Key 与 Search Engine ID。
设置方式如下:
导入依赖
import requests
import pandas as pd
from bs4 import BeautifulSoup
from lazyllm.tools.tools import GoogleSearch
代码实现
搜索结果提取函数
定义 extract_search_results 函数,从 Google API 返回结果中提取标题与链接。
def extract_search_results(response_dict):
items = response_dict.get('items', [])
results = [
{'title': item.get('title', ''), 'url': item.get('link', '')}
for item in items
]
return pd.DataFrame(results)
该函数的输出是一个 pandas.DataFrame,包含两列:
title:网页标题url:网页链接
抓取网页正文内容
使用 requests 和 BeautifulSoup 抓取网页文本并清洗。
def fetch_web_content(url: str) -> str:
try:
headers = {'User-Agent': 'Mozilla/******'}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# 移除脚本与样式
for tag in soup(['script', 'style', 'noscript']):
tag.decompose()
# 提取正文
text = soup.get_text(separator='\n', strip=True)
lines = [line for line in text.splitlines() if line.strip()]
content = '\n'.join(lines)
return content
except Exception as e:
return f'[ERROR] {e}'
实现细节说明:
- 通过
requests.get()请求网页; - 用
BeautifulSoup解析 HTML; - 删除
<script>,<style>等标签; - 清理空行后返回正文内容。
该函数用于从指定 URL 抓取网页正文。它通过 requests 获取网页源码,并用 BeautifulSoup 解析 HTML 内容。函数会移除脚本、样式等无关标签,仅保留纯文本,并按行整理成整洁的正文内容。若过程中发生异常,则返回错误提示。
主程序逻辑
将上述模块组装成完整流程。
if __name__ == '__main__':
search = GoogleSearch(custom_search_api_key=api_key, search_engine_id=engine_id)
result = search('圆明园')
df = extract_search_results(result)
df['content'] = df['url'].apply(fetch_web_content)
print(df.head())
首先,使用 LazyLLM 内置的 GoogleSearch 调用 API 搜索关键词 “圆明园”,然后通过 extract_search_results 提取结果链接,并利用 fetch_web_content 获取并解析网页正文内容。
完整代码
完整代码如下所示:
点击展开完整代码
import pandas as pd
import requests
from bs4 import BeautifulSoup
from lazyllm.tools.tools import GoogleSearch
api_key = 'AI******'
engine_id = 'a3******'
def extract_search_results(response_dict):
items = response_dict.get('items', [])
results = [
{'title': item.get('title', ''), 'url': item.get('link', '')}
for item in items
]
return pd.DataFrame(results)
def fetch_web_content(url: str) -> str:
'''
Fetch webpage content and extract main text body from a given URL.
Args:
url (str): The target webpage URL.
Returns:
str: Extracted text content (first 5000 characters) or an error message.
'''
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0'
}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
# Remove unnecessary elements
for tag in soup(['script', 'style', 'noscript']):
tag.decompose()
# Extract main text
text = soup.get_text(separator='\n', strip=True)
lines = [line for line in text.splitlines() if line.strip()]
content = '\n'.join(lines)
return content
except Exception as e:
return f'[ERROR] {e}'
if __name__ == '__main__':
search = GoogleSearch(custom_search_api_key=api_key, search_engine_id=engine_id)
result = search('圆明园')
df = extract_search_results(result)
df['content'] = df['url'].apply(fetch_web_content)
print(df.head())
运行效果
运行脚本后,终端将显示前 5 条搜索结果内容:

小结
本节我们构建了一个具备“关键词 → 搜索 → 内容抓取”完整流程的网页信息采集系统。
其核心思路是:
- 使用 LazyLLM 的
GoogleSearch进行自动搜索; - 使用
BeautifulSoup清洗网页文本内容; - 使用
pandas对结果进行结构化整理。
该方案展示了 LazyLLM 工具在信息检索与网页内容抽取任务中的实用性与可扩展性。 未来可以在此基础上进一步扩展,如引入多源搜索、网页内容摘要生成或知识库构建等高级功能。